
转发:
近日高带宽内存(HBM)供应已成为中美技术竞争和贸易谈判中的一个关键焦点。简单来说,美国对HBM的出口限制直接制约了中国发展先进人工智能的能力,而中国则将解除这一限制作为贸易谈判的核心条件之一,并于近日开始对先进制程和HBM生产有关的稀土限制出口作为条件回应。
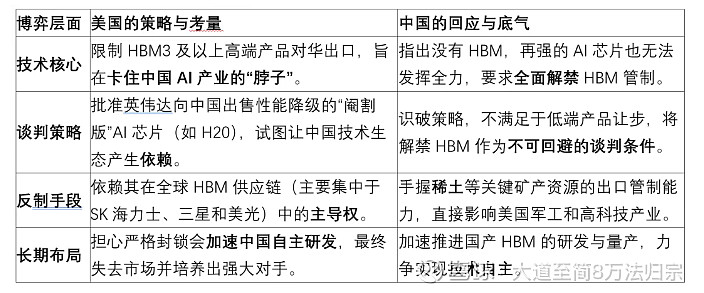
美国封锁HBM供应链,除不允许产品出口到中国市场外,还对HBM的TSV生产设备进行了出口限制,阻断HBM的技术流向中国。
HBM为何如此重要
HBM是一种高性能内存芯片,它通过垂直堆叠多个DRAM芯片,实现了远超传统内存的数据传输带宽和能效。对于处理海量数据的AI模型训练和推理来说,HBM如同一个高速的“数据供应员”,能确保AI芯片(GPU)这个“大胃王”不会因等待数据而闲置。没有高性能的HBM,再先进的AI芯片也无法发挥其全部潜力。
AI时代的内存皇冠
如果普通内存是平房,数据进出要走一条长长的马路。那么HBM就是摩天大楼,数据通过无数部高速电梯(TSV硅通孔)垂直上下传输,路途极短,但通道极多,所以带宽巨大。
内存带宽决定 GPU 速度
内存带宽是指内存子系统每单位时间(通常为每秒)可以传输的数据总量。它直接测量处理器(如 CPU 或 GPU)从连接的内存(DRAM)读取数据或将结果写入其的速度。
内存带宽(GB/s)= [总线宽度(位)× 有效传输速率(GT/s) ] ÷ 8
Bus Width (bit)(总线宽度(位)):内存接口一次可以并行传输多少位数据。更宽的公交车就像在数据高速公路上拥有更多的车道。例如,HBM2E 的接口宽度可以达到 1024 位或更高,远远超过 GDDR6 的 32 位。
有效传输速率(Hz / GT/s):每秒数据传输作数。现代高速内存(如 GDDR、HBM)通常使用双倍数据速率(DDR)或四倍数据速率(QDR)技术,在时钟信号的上升沿和下降沿传输数据。
为了实现更高的内存带宽,需要高有效传输速率(数据“运行速度快”)和宽总线宽度(许多“数据通道”)。
在 AI 应用程序中,模型的参数可能为数百 GB 甚至 TB。在计算过程中,GPU 经常与内存交换大量参数和中间结果(激活、梯度)。
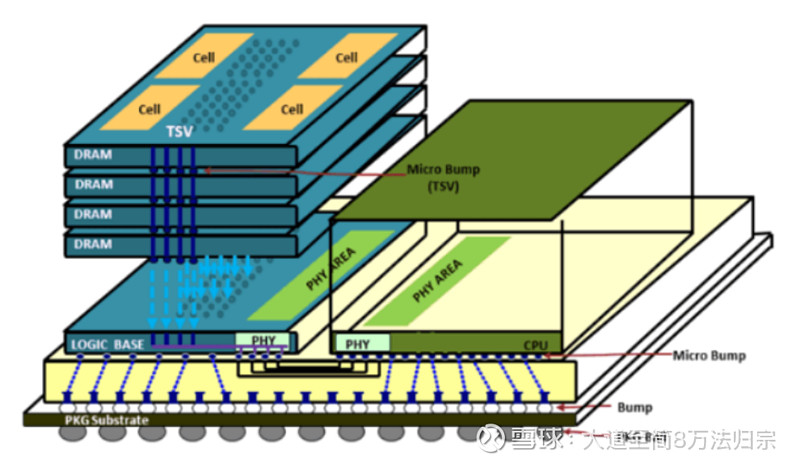
HBM的量产难点在于“极致的3D堆叠工艺”,而国产化的核心短板在于“缺少一个能整合DRAM、先进封装和计算芯片的强大产业链生态”,其中,以台积电CoWoS为代表的先进封装能力是当前最明显的“断点”。
量产工艺难点(怎么把“摩天大楼”盖好?)
HBM的难点,不在于单块“砖”(DRAM芯片),而在于**“盖楼”和“装修”**的极端工艺。
难点一:垂直堆叠的“穿针引线”——TSV(硅通孔)
是什么: 要让数据在楼层(DRAM芯片)间垂直传输,就得在每层楼板上钻几百万个“电梯井”(TSV),再用铜填满,做成电路。
难点在哪:
精度要求变态: 在比头发丝还薄的硅片上,钻出直径只有几微米的孔,还不能损坏硅片结构,相当于在豆腐上绣花。
良率是杀手: 一栋HBM大楼有8层、12层甚至更多。只要其中一层的任何一个“电梯井”钻坏了,整栋楼就废了。这种“一损俱损”的特性,对每一层DRAM芯片的初始良率要求极高。
难点二:芯片间的“精密焊接”——微凸点键合
是什么: 把一层层DRAM芯片堆起来时,要用无数个比灰尘还小的“焊球”(微凸点)把它们粘合通电。
难点在哪:
对准要“神级”: 几万个微凸点必须和下层芯片的触点完美对齐,偏差不能超过头发丝的几分之一。这需要极高精度的设备。
压力要“刚刚好”: 压力太小,接触不良;压力太大,会压坏脆弱的芯片。同时,还要保证所有焊点受热均匀,融化后高度一致,否则大楼就“歪”了。
难点三:散热难题——“火柴盒里的火炉”
是什么: 十几颗芯片堆在一个小面积里,功率密度极高,就像一个火柴盒里塞了个小火炉。
难点在哪: 热量散不出去,中间的芯片会“过热死机”,导致性能下降甚至永久损坏。如何设计有效的散热路径,是HBM稳定工作的生命线。
难点四:测试的“盲盒”困境——KGD(已知良好芯片)
是什么: 盖楼前,你必须确保每一块“砖”(DRAM芯片)都是100%完美的。
难点在哪: 一旦堆叠起来,你根本无法测试中间层的芯片。所以,必须在堆叠前就把有瑕疵的芯片全部挑出来。这要求DRAM芯片本身的良率就要非常高,否则筛选成本会高到无法承受。
国产化供应链短板(我们缺了什么?)
HBM不是单一技术,而是一个“集大成”的产业链。我们的短板是系统性的。
短板一:地基不稳——DRAM芯片本身
现状: 我们有长鑫存储(CXMT)等公司在努力追赶,但目前主流产品是DDR4/LPDDR4,相当于盖平房的“砖”。
差距: HBM用的DRAM芯片是“特供版”,要求速度更快、功耗更低、裸片更薄、面积更小。这背后是深厚的设计和工艺积累,我们还在从“能用”到“好用”的路上。
短板二:缺了“总包工头”——先进封装(CoWoS)
这是最致命的短板。 HBM大楼盖好后,不能直接用,必须和GPU/AI这个“主楼”通过一个“连接平台”(硅中介层)连在一起,最后再用一个“外壳”(CoWoS等先进封装技术)包起来。
现状: 这个“总包工头”的角色,全球几乎被台积电(TSMC)垄断。英伟达、AMD的HBM都由台积电封装。
差距: 我们没有同等规模的先进封装能力。没有CoWoS,就算我们造出了HBM堆栈,也找不到人把它和计算芯片高效地“组装”起来,产品就出不来。这是目前被“卡脖子”最紧的地方。
短板三:没有“金刚钻”——核心设备与材料
现状: 无论是制造TSV的刻蚀机、沉积设备,还是进行精密键合的设备,以及高纯度的硅片和各种特殊化学品,主要依赖美国、日本、欧洲的企业。
差距: 在设备材料领域,我们和国外的差距不是一两年,而是二三十年。没有这些“金刚钻”,就揽不了HBM这个“瓷器活”。
短板四:不成“朋友圈”——生态与IP
现状: HBM是一个全球协作的产物,标准由JEDEC(固态技术协会)制定,三星、海力士、美光、台积电等巨头共同推动。
差距: 我们目前还处于“学习者”和“跟随者”的角色,在标准制定、专利布局上话语权很弱。构建一个自主、可控、高效的产业生态圈,需要漫长的时间。
HBM成为中美贸易谈判美方筹码
因此,美国将HBM,特别是最先进的HBM3和HBM3e产品,作为对华技术管制的重点。其逻辑很明确:通过限制这一关键组件的获取,直接制约中国AI企业开发具有竞争力的AI硬件和模型的能力。
面对美国的限制,中国在谈判中采取了强硬立场。
直击要害,加码要价:当美国在2025年7月做出妥协,允许英伟达对华销售特供版H20芯片时,中国并未满足。相反,中方明确指出,不解除对HBM的管制,其他贸易谈判都“免谈”。这背后的原因是,H20芯片的性能已被大幅削弱,而美国随时可能对更先进的HBM版本实施封锁。中国的要求实际上是将博弈层级从“能否销售成品芯片”提升到了“能否获取核心技术组件”。
双管齐下的反制能力:中国的底气来源于两方面。一是战略资源反制,中国掌握着全球稀土加工的大部分产能,而稀土是制造芯片和高端武器系统的必需品,这为中方提供了重要的博弈筹码。二是加速自主研发,美国的技术封锁反而坚定了中国实现技术自立的决心。国内产业链积极攻关HBM技术,力求实现从0到1的突破。
国产HBM到哪个阶段了
国产HBM供应链虽然整体还处于“爬坡期”,但在几个关键节点上,已经出现了从0到1的实质性突破。
整体来看,外部压力已经转化为了内部最强的催化剂,进展速度比预想的要快。
第一部分:DRAM芯片(“烧砖”技术)——从能用到好用
核心玩家: 长鑫存储(CXMT)、长江存储(YMTC)
关键进展:
长鑫存储(CXMT)的“主攻”:
基础已夯实: 长鑫已经成功量产了LPDDR5,这是消费级主流内存。这意味着它掌握了19nm甚至更先进的DRAM制造工艺,这是研发HBM的“入场券”。能造出合格的“平房砖块”,是盖“摩天大楼”的前提。
HBM样品已出: 这是最关键的进展。据多方消息,长鑫的HBM2(甚至可能是HBM3)样品已经流片,并送交给下游的GPU厂商和客户进行测试验证。虽然良率和性能可能还比不上三星/海力士,但这标志着我们已经跨过了“理论设计”阶段,进入了“工程实践”阶段。
长江存储(YMTC)的“奇兵”:
虽然以NAND闪存闻名,但长江存储也秘密组建了DRAM研发团队。这种“双线出击”的策略,增加了我国在DRAM领域突破的概率,避免了单点依赖的风险。
一句话小结: 我们已经学会了怎么烧高质量的“砖”,并且已经烧出了第一批带有“电梯井预留孔”(TSV雏形)的“HBM专用砖”,正在内部测试强度。
第二部分:先进封装(“盖楼”技术)——自建“建筑队”
核心玩家: 通富微电(TFME)、长电科技(JCET)、华天科技等封测大厂
关键进展:
技术路线明确,并已有储备:
国内封测巨头早已布局TSV、微凸点等技术,主要应用在图像传感器(CIS)等领域。这些技术是相通的,为进军HBM封装打下了坚实基础。
长电科技推出了自己的2.5D/3D集成平台“XDFOI”,通富微电与AMD合作多年,积累了大量先进封装经验。他们都在积极开发自己的类CoWoS技术,目标是打造一个不依赖台积电的“国产封装大楼”。
与客户深度绑定:
最重要的一点是,国产GPU厂商(如壁仞、摩尔线程等)正在与这些封测厂紧密合作。GPU设计公司直接提出需求,封测厂配合进行工艺开发和试产。这种“联合研发”模式,大大缩短了研发周期,确保了产品出来后能“即插即用”。
一句话小结: 我们自己的“建筑队”已经成立,并且正在和“甲方”(GPU公司)一起设计图纸,学习如何盖“HBM摩天大楼”,虽然经验不如台积电,但已经动工了。
第三部分:设备与材料(“工具”)——打造“国产工具箱”
核心玩家: 中微公司(AMEC)、北方华创(NAURA)、盛美上海(ACM)等
关键进展:
关键设备“去美化”替代:
HBM制造中的核心设备,如刻蚀机(中微公司)、薄膜沉积设备(北方华创)等,在28nm及以上的成熟工艺节点上,国产化率已经非常高。好消息是,HBM的后端工艺(制造TSV、堆叠等)主要使用的正是这些成熟设备,对最顶尖的EUV光刻机依赖较小。
这意味着,即使没有最先进的“光刻机”,我们依然有能力搭建起一条不依赖美国的HBM产线。
材料逐步自给:
高纯度硅片、特殊电子气体、光刻胶等关键材料,虽然高端产品仍依赖进口,但中低端领域已有沪硅产业、南大光电等公司在突破,为HBM量产提供了基础保障。
一句话小结: 盖楼需要的“电钻”、“起重机”等核心工具,我们已经能自己造出“可用”的版本,虽然不是最顶级的“德国货”,但已经能开工了。
第四部分:生态与验证(“朋友圈”)——内部循环开始运转
关键进展:
强大的“内需”拉动:
这是最根本的驱动力。美国的制裁让国产AI芯片厂商“无米下锅”,他们迫切需要国产HBM来让自己的芯片跑起来。这种生死存亡的压力,形成了强大的“需求牵引力”,迫使整个产业链加速运转。
“国产化”联盟初步形成:
GPU设计公司 > HBM制造商 > 封测厂 > 互联网客户,这个链条正在以前所未有的紧密程度进行协作。大家目标一致:尽快打造出“全国产”的AI计算解决方案。阿里等云厂商也在积极进行内部测试,为国产HBM提供了宝贵的“练兵场”。
一句话小结: 以前大家各干各的,现在因为“外部压力”,一个目标一致的“国产化朋友圈”正在迅速形成,内部循环开始转动。
总结:从“望尘莫及”到“望其项背”
国产HBM供应链的进展可以概括为:
DRAM芯片: 已出样品,正在攻克良率和性能。
先进封装: 技术路线清晰,正在与客户联合开发。
设备材料: 核心非光刻设备已基本自主,产线可控。
产业生态: 需求旺盛,协同紧密,形成了强大的内生动力。
我们距离世界顶尖水平还有差距,尤其是在良率、成本和极致性能上。但已经从完全的“望尘莫及”,走到了能够看到对手背影、开始奋力追赶的“望其项背”阶段。
这条路依然漫长,但方向已经明确,脚步已经迈开,而且越走越快。
硅通孔(TSV)技术在高带宽存储器(HBM)中的重要性
TSV(硅通孔)技术是实现高带宽存储器(HBM)超高性能的核心引擎。它通过在硅芯片内部制作垂直导电通道,直接完成芯片间的三维互连,从根本上提升了数据传输效率。
原理深析:TSV如何成就HBM高性能
TSV技术通过垂直互连,实现了芯片堆叠的“质变”。
极致缩短互连路径:与传统需要绕行芯片边缘的引线键合相比,TSV创造了最短的垂直电信号路径(仅数十微米)。这极大降低了信号传输的延迟、寄生电容和电感,为HBM实现超高数据传输速率和低功耗奠定了物理基础。
实现超高互连密度:一颗HBM堆叠芯片中可能集成数万甚至数十万个TSV。这种极高的互连密度使得HBM能够拥有1024位乃至2048位的超宽内存总线,这是其获得巨大带宽的直接原因。
异构集成能力:TSV不仅用于DRAM芯片堆叠,在HBM的2.5D集成方案中,硅中介层也内置了高密度TSV。它作为底座,将HBM与GPU/CPU等高功耗逻辑芯片紧密连接在一起,实现了整体系统性能的飞跃。
超越难点:量产中的精密控制
表格中列举的难点在实际量产中需要通过极其精密的工艺控制来解决。
深孔填充的“魔法”:TSV电镀铜并非简单浸泡,而是依赖复杂的添加剂配方。抑制剂聚集在孔口,抑制该处的铜沉积;加速剂则深入孔底,加速底部沉积。整平剂进一步协同作用,确保铜自下而上均匀填充,避免空洞产生。
与“薄如蝉翼”的晶圆共处:HBM堆叠要求芯片厚度极薄。对如此脆弱的结构进行搬运、加工和键合,犹如在针尖上跳舞。整个工艺链必须在洁净度、温度稳定性和机械应力控制上做到万无一失,任何微小的偏差都可能导致整片晶圆报废。
TSV技术的未来展望
随着HBM等高性能芯片持续向更高堆叠层数(如12层甚至更高)和更小尺度演进,TSV技术也面临新的挑战和机遇。通孔尺寸将进一步缩小,晶圆厚度需要减得更薄,这对通孔刻蚀、薄膜沉积的均匀性以及键合精度都提出了近乎极限的要求。同时,散热已成为制约3D堆叠性能的关键瓶颈,如何高效地将堆叠芯片中心的热量导出,是下一代TSV技术必须攻克的核心课题。