高频量化入门

什么是股票?股票是资产所有权的一部分。不同的资产有不同的流动性,现金的流动性最高,但长期贬值。二级市场的公司股票流动性较高,因为有大量交易者在场内交易。房地产流动性较差,常常需要房产中介撮合买卖双方,中介从中赚取流动性的差价。
高频量化起初干的就是类似房产中介的工作,提供流动性,承担流动性风险,从中盈利。
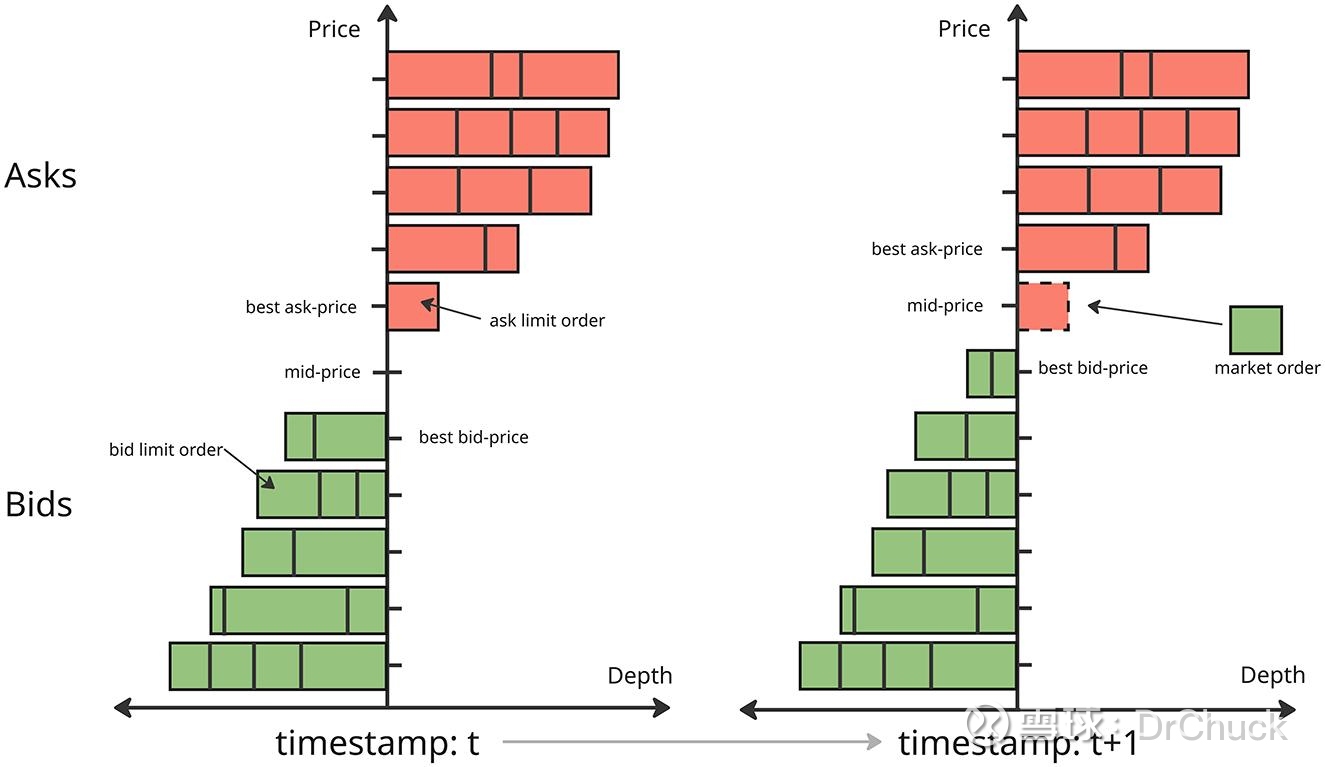
每个时刻,机器看到的不是单一的股价,而是一本买方与卖方的出价订单簿(Limit Order Book/LOB)。每个股票的买卖双方各自出价:

买方举牌价bid最高出价是100块,卖方询问价ask最低出价是102块,中间价mid是101块,买卖价差spread是2块。
高频量化如何盈利?有两种方式:
1. 拉近价差,出价101块买入,等待卖给市场愿意101.5块买入的人,或者101.5块卖空,等待平仓给市场愿意101块卖出的人,赚取0.5块差价。通过承担持有等待期间的风险,将价差从2块拉近,赚取流动性差价。
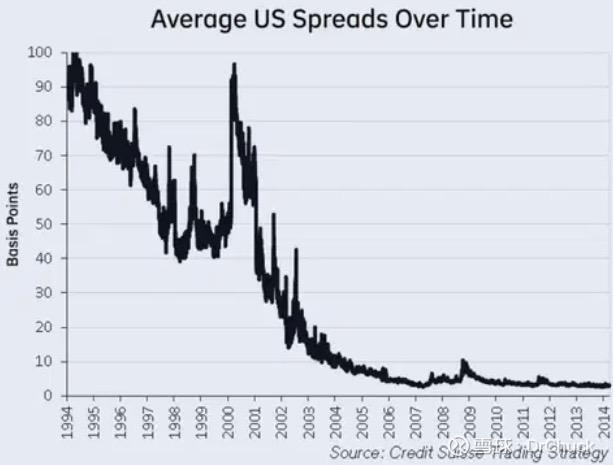
过去二十年,随着高频交易的流行,美国股市的价差急剧收缩,大幅降低了买卖双方的交易成本:
2. 价格发现,通过模型预测未来的价格变化,假如预测价格会涨,则接受卖方102块的ask出价买入股票,等待买方bid更高的价格,如103块,赚取1块差价。
这是AI模型大展身手的地方,通过将出价订单簿转化为一个大规模的机器学习任务,预测并发现资产的公允价格。
ChatGPT和DeepSeek等大语言模型,处理的token单元是自然语言里的词组,高频量化模型处理的基础单元是出价订单簿。相比自然语言,金融数据具有其独特性,不能直接搬运 GPT 架构,因为:
低信噪比: 语言中的词汇通常带有明确含义,但市场数据充满了随机噪音和无效干扰,信号隐藏在极深处。
非平稳性: 市场的统计特征会随时间剧烈变化,而语言规则相对稳定。
高对抗性: 市场是一个博弈场。你的交易行为会改变环境,且其他参与者会试图识别并针对你的模型策略。
因此,全球领先的量化交易机构,如哈德逊河 Hudson River Trading ,通常采用以下步骤将订单簿LOB的状态“语言化”:
1. 状态特征的结构化
在每一个时间戳t,订单簿 LOB 的状态可以表示为一个矩阵。模型首先提取最核心的几个维度:
价格维度:买一到买 N,卖一到卖 N 的价格。
深度维度:每个价格档位上的挂单量。
类别维度:该事件是新挂单、成交还是撤单。
2. 连续值的离散化与缩放
由于价格是连续变化的,不能直接作为Token单元。
相对价格化:将所有价格减去当前的中间价,这样模型学习的是“偏移量”而非绝对数值。
对数缩放:对挂单量取对数log,压缩长尾分布,使模型对小单和大单的敏感度更加平衡。
分桶量化:将这些连续值划分为几千个桶(Bins),每个桶对应一个量化值。
3. 市场节奏编码
大语言模型通过旋转位置编码Rotary Position Embeddings知道上下文的先后顺序,高频量化模型通过Time Delta Embeddings对订单事件的时间间隔进行编码,让模型感知市场的“节奏”。
4. 序列化与因果掩码
将处理好的订单向量按时间顺序排列,形成类似“句子”的序列。
因果掩码:在训练阶段,模型只能看到当前时刻之前的 Token,目标是预测下一档的价格变化。
跨品种建模:如果将相关资产不同品种(如标普500指数期货和其对应的 ETF)的 Token 交织在一起(交织注意力Cross attention),模型就能学习到跨品种的套利逻辑。
总之,将订单簿 LOB 转为词元 Token 的本质是:将高频、大噪声的原始数据(Tick Data),映射到一个能够捕捉市场微弱Alpha的高维空间。
哈德逊河公司收集了全球过去20多年的市场数据,涵盖股票,期货,加密等各种类别,总数据量达到1兆Token,接近训练大语言模型的数据量。同时他们拥有海量的英伟达 B200,GPU多到运输时曾经阻塞了美国东海岸的交通。他们在训练金融模型时也发现了尺度定律,盈利能力随参数量和数据量可预测的提升,正致力于让量化交易从简单的统计套利向通用的金融基础模型演进。