华宇软件:或许是掩盖在烂稻草下的AI明珠(二)

$华宇软件(SZ300271)$ 在2022年开始告别过往,正式转型。
转型前公司是一家典型中国式信息服务公司,依托深厚的政商关系,提供以软件服务为主,兼顾硬件销售的信息化服务集成商。
与大多数中国软件信息化企业一样,在过往无以为继,而人工智能铺面而来的档口,华宇软件毫无犹豫地选择拥抱AI,立志成为以法律科技为核心的智能引擎服务商。
从依托政商关系的信息集成服务商,转型成为依托人工智能技术的智能引擎服务商。
从关系导向的销售型企业,转向技术导向的科技型企业。
这种转变不可谓不大,但其能否成功吗?
问题是华宇软件转型所依托的人工智能技术是什么?
答案是亿信华辰的大数据治理与分析平台和元典信息的万象大模型。
亿信华辰,这是一颗在数据分析和治理领域闪闪发亮的珍珠,在国内数据治理的专业厂商中,其市场占有率排名第一。
IDC估算其2023年的市场占有率约为5.9%,排名第二的专业厂商百分点约为3.4%,其市场份额的领先优势还是不小的。
亿信华辰作为在数据行业沉淀多年的专业厂商,其市场基础极其扎实。
其服务超过的客户超过13000家,覆盖200多个细分行业,包括政务、银行、租赁、制造、能源、卫生、教育等等。
亿信华辰以数据全生命周期为核心,产品和技术平台覆盖数据的采集,存储,处理,分析和应用。
核心产品线分为三块,第一块数据治理平台-睿治:功能包括元数据管理,数据标准管理,数据治理管理,数据资产管理等。
第二块是数据分析平台-亿信ABI:功能包括数据源匹配,ETL数据处理,数据建模,数据分析,数据可视化与决策支持。
第三块是数据批量处理平台,包括支持海量数据查询和处理的分布式数据库petabase,以及内置计算引擎,面向数仓架构的esdatafactory。
这种数据采集,处理,存储,查询,分析的技术平台,几乎是所有企业部署AI和应用AI所必须的工具,是AI应用中很纯粹的一把铲子。
如果能像Databricks那样,强化技术优势,积累客户应用,成为黏性极高的平台式产品,产业价值将无比巨大,从产品必须但厂家可选的卖水人,变成必经之路的收费者。
但面向未来的AI应用,亿信华辰的产品有两个不足,一是产品更偏向BI(商业智能),而非AI。
BI更偏数据的分析,报送,可视化与决策支持。AI更偏海量数据的存储,查询和计算。
二是亿信华辰的产品主要是面向结构化数据,而非AI更注重的半结构,非结构和异构数据,甚至是多模态融合数据。
虽然亿信华辰近年来一直在加大对AI方向的技术研发投入,开发出面向海量非结构数据的存储,查询和计算的产品。
但在底层技术架构,例如湖仓架构,分布式计算等关键技术方面依然存在一定的差距。
特别是去对标DataBricks等国外成功的数据治理平台。
那么国内有哪家企业在面向AI应用的底层技术架构方面做得更好呢?$星环科技-U(SH688031)$ 。
其大数据治理平台TDH,支持PB级海量异构数据的存储,查询检索,实时分析和分布计算。技术上几乎可以直接对标Databicks的产品。
星环科技是强在产品的底层技术架构,但市场基础和营销能力比较弱,所以产品迟迟无法取得突破。
亿信华辰则刚好相反,产品技术不超前但基本够用,胜在客户基础好和市场拓展能力强,随着客户需求的提出而不断投入研发,完善自身产品。
到底谁的发展路径更好,还真不好说!
亿信华辰的这块数据治理与分析的业务收入有多少呢?这是一个对估值来说极其重要的问题。
华宇软件曾披露过2015年为7383万元,2016年就突破了1亿元,然后一直在1个亿左右徘徊,2024年的营业收入只有1.13亿元。(这里的数据是经雪球网友提醒后更新的)
所以亿信华辰这枚小珍珠的产业价值虽高,发展潜力也不小,但目前还难以对华宇软件的估值提升带来很大的帮助。
如果华宇软件集中资源发展这块业务,随着AI应用的普及和大数据处理市场的爆发,其前途不可限量。
华宇软件将亿信华辰的数据治理和分析能力,作为其核心技术基座之一,支撑其转型AI技术引擎服务商还是非常明智的。
试问一句,在目前号称要转型AI应用的上市公司中,有多少能拿得出像亿信华辰这样的AI技术基座呢?
除了亿信华辰,华宇软件转型的另一个核心技术基座就是他的法律垂类大模型-万象大模型。
当下10家转型AI的企业,至少有8家都宣称自己有领先行业的垂类大模型,哪怕企业每年的研发费用只有可怜的一千几百万,例如某家搞市场营销的咨询公司。
那么华宇软件的法律垂类大模型有何独到之处呢?
一是研发孕育的时间足够长,与其他搞了两三年就出来面向市场的垂类大模型不同,华宇软件早在2016年就成立专门的人工智能技术子公司-元典信息。
开始面向法律领域打磨垂类大模型和相关的人工智能技术,直到2023年7月,万象大模型才正式推向市场。
今年已经迭代发展到4.0版本,实现了多模态的融合。
二是其产品架构相对完善,我们不妨将万象大模型的整个架构拆解开来看:
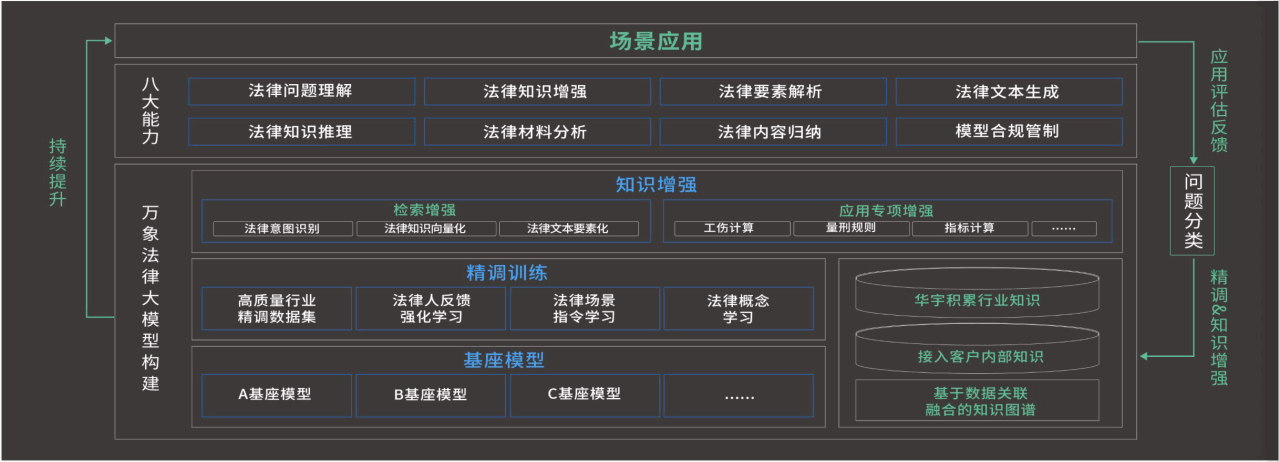
第一层是底层支撑层,华宇选择直接接入不同的主流大模型,如百度文心,DS,Llama等,取他们的泛化智能和各自的相对优势为己用。
第二层是数据资源层,利用华宇20多年的法律科技沉淀,构建专业领先的法律知识图谱和知识引擎。
同时将经过亿信华辰处理的专有法律数据库导入,在泛化智能的基础上实现垂直领域的专业智能。
这是华宇软件的独特优势所在,无论是极其深厚的行业Know How还是丰富的专有行业数据库,又或是亿信华辰的法律大数据处理能力,都是其他企业所无法比拟的。
第三层是专业精调层,又称训练增强型,或者可以直接理解成行业小模型。
其实就是将在底层泛化智能和第二层的法律专业知识图谱和数据库的基础上,引进指令学习和专家反馈强化等技术,用海量数据去训练出一个法律专业的垂直小模型。
第四层是核心能力层,华宇基于上述垂直小模型,结合市场应用需要,开发出八大专业引擎,用以支撑实际的业务应用。
第五层就是最上层的业务应用层,就是直接面向客户的产品或工具。
包括面向法官判案全过程的万象法官数字助手,面向检察官的万象问数,面向企业的元典数智合规管理平台,面向公众的法律咨询Saas平台-元典问答等。
从万象大模型的专业架构来看,基本是没啥问题的,底层大模型采取的是拿来主义,融合各家所长,中间的专业知识图谱和海量数据库又是华宇的独特优势所在,上层的应用所面对的具体场景又都是华宇原有的市场优势。
大家可能想问的是,这个万象大模型的技术到底算不算先进?更关心的是能否在市场上取得突破?
模型的技术是否先进?作为一个法律垂类应用的模型,目前还没查询到权威机构的技术测评。
倒是公司一直在宣传,华宇作为主要参与方,获得2024年“吴文俊人工智能科学技术奖”中的科技进步一等奖。
“吴文俊人工智能科学技术奖”是国内公认的人工智能领域的最高奖,是有提名国家科学技术奖资格的,含金量不低。
其设置有六个不同的奖项,科技进步奖主要是侧重产业应用方面。
查询过历届的科技进步一等奖和特等奖的获奖项目,其中主导或主要参与的上市公司基本都是AI领域,至少是细分市场中的大佬,例如蚂蚁集团,百度,科大讯飞,京东等。
这个奖项的获得,从侧面的一定程度上说明华宇万象大模型的技术水平应该挺好。
但在这个由浙江大学吴飞教授牵头的“智慧司法智能化支撑平台与示范作用”的项目中,华宇软件只是重要参与方之一。
项目的技术主体和核心算法是由华院计算负责的,华宇软件只负责部分偏前端的技术环节和应用场景方面。
所以只能说明华宇万象大模型在行业内和AI技术圈内还是受到认可的,不是一般上市公司那种吹牛逼的性质。但若要说技术上有多牛,那也算不上。
我们不妨在查询一下华宇内部的AI技术专家,真正称得上是技术大拿的应该就是亿信华辰AI实验室的主任刘勤波博士,主攻大数据治理的专家。
其他的与其说是技术专家,不如说是工程应用方面的资深技术人员。
不过这非常复合华宇软件的风格,不追求技术的领先或超前,更强调市场的实际需求,典型的市场先行,研发跟上的务实风格,从亿信华辰的发展轨迹上就能看出一二。
不过如果大家仔细查询一下华宇软件内部的科研技术人员及科研成果,还是会对这家公司的技术实力挺有信心的。
所谓的不足,只是相对AI行业的一些大佬而言的,相对于一般百亿市值以下的AI应用上市公司,其研发技术实力绝对是一流的。
至于大家最关注的问题,华宇软件基于万象大模型开发的一些列AI产品,能否在市场拓展上取得突破?
我们不妨按产品一一展开看看:
第一是面向G端的产品(核心),包括面向法院的万象法官数字助理目前已经在上海二中院,浙江法院体系和吉林法院体系试用。
面向检察院的万象智数系统也同样进入了多地检察院部署试用。
但试用效果有待检验,是否能从点到面,实现全国突破,只能慢慢观察。
第二是面向B端的产品,包括服务于律所等专业法律服务机构的智慧法务管理平台Yodex已经进入众多头部律所。
服务于企业的Amicus法律智能体已经进入中国移动,重庆电建,能源集团等诸多大型企业。
但试用效果同样有待检验,是否能从点到面,实现全国突破,同样只能慢慢观察。
第三是面向C端的产品,主要是法律咨询Saas平台元典问答,据说已经通过微信小程序等入口,服务几百万法律从业者和普通民众。
有试用过上述产品的朋友,都可以出来讲讲使用体验,这个或许更能说明问题。
整体感觉就是与国内大多数AI应用企业一样,积极开发各类产品,努力拓展应用场景,但实际效果有待检验,未来前景有待观察。