「存储产业」第一性原理:“超级成长vs强周期”,存储投资的底层逻辑


【前言】
本文是鹏友圈CapitalCircle产业分享第五期,主题是《从第一性原理看存储及供应商的投资价值》。
分享嘉宾是AI产业资深人士/某大厂资深产品总监 陈总、深圳某私募基金投资总监/存储产业资深投资人 李总,本文再次表达感谢。
2025年下半年,AI驱动的超级周期轮到了存储产业,全球存储产业从‘周期性博弈’正式跨入‘资源分配战’。
于是产业端发生了如下几个事件:
巨额包场:OpenAI 预计将消耗全球 40% 的 DRAM 总产能,目标是在 2029 年前达成每月 90 万片晶圆的稳定供应。
价格跳涨:随着三星将产能向HBM 倾斜,2025 年 11 月服务器 DDR5 价格从 9 月的 149 美元 跳升至 239 美元,涨幅高达 60%。
市场垄断:SK 海力士在 2025 年继续把持着 60% 以上的 HBM 市场份额,迫使 OpenAI 甚至采取“跪求产能”的姿态与之签署战略意向书(LOI)。
研发倾斜:厂商内部超过70% 的新增资本支出(CAPEX)已从通用芯片转向 HBM4 和下一代定制化存储,这意味着传统 PC 和手机市场的存储供给遭到了前所未有的“战略性挤压”。
发生以上产业端巨大的变化的底层逻辑,是AI驱动算力紧张向存力紧张演变,内部有深刻的产业周期、技术限制、成本刚性、扩产与商业策略选择、竞争格局寡头化等产业格局的变化。
本文尝试探讨存储产业从【强周期】向【超级成长】演变的底层技术逻辑,同时也关注其强周期属性仍然制约着高端HBM以下的产品的周期属性,同时探讨本轮存储的超级周期下,潜在的投资机会。
(昨晚讨论到23点,今日加更,也是考虑到开年第一周后,在NV算力产业链短期似乎成为“老登”后,投资者或有些迷茫,本文在周日加更产业分享,也是为老粉提供一些产业思路。26年投资主线是大科技+顺周期双主线,具体投资上要准确把握。)
「风险提示:本文系基于公开行业数据、券商研报及个人研究的整合分析,所有结论及观点仅为信息分享,不构成任何投资建议。提及标的仅供案例参考,投资者须结合独立判断并自行承担风险。市场有风险,决策需谨慎」

【正文】
一、第一性原理阐述存储的物理学诅咒——为什么供给侧是“刚性”的?
在讨论AI之前,我们必须先解决一个更本质的问题:为什么这一轮存储(尤其是DRAM)的扩产这么难?为什么三星和海力士即便面对泼天的富贵,也显得如此“克制”?
技术层面核心观点:摩尔定律在内存上已失效+物理困境
1.1 “1T1C”的物理困境:当电容变成摩天大楼
逻辑芯片(CPU/GPU)可以通过EUV光刻机,从5nm走到3nm,再走到2nm,晶体管密度的提升即意味着算力和能效的质变。但是,DRAM不行。
DRAM的基本单元结构是 1T1C(1 Transistor + 1 Capacitor,一个晶体管+一个电容)。晶体管负责开关,电容负责存储电荷(代表0或1)。
核心矛盾在于那个“C”(电容)。

[技术拆解:DRAM微缩的物理极限]
这里引入一个半导体物理概念:高深宽比(High Aspect Ratio) 。
电容的噩梦 :电容存储电荷的能力公式为。随着制程微缩(比如从1y nm到1alpha nm),电容在地基上的投影面积被迫变小。
物理刚性 :为了保持电容值不变(否则电荷太少,数据会瞬间丢失,或者刷新频率太高导致功耗爆炸),工程师只能向天空“借空间”——把电容做得极高,像一根极细的摩天大楼。
工程极限 :目前DRAM电容的深宽比已经超过50:1 。在10nm级别的工艺上,这就像要在在一根头发丝上雕刻出一座埃菲尔铁塔。继续增高,结构会倒塌,或者刻蚀离子根本打不到底部。
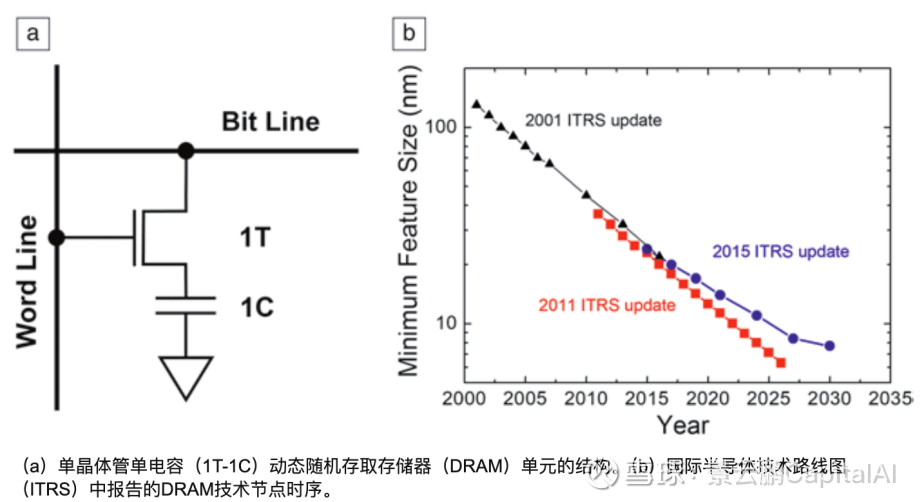
这就是为什么DRAM制程停留在10nm级别很难向下推进的原因。制程微缩带来的“位元增长(Bit Growth)”效率,已经从过去的30%+断崖式下跌至10%以内。
这意味着,要增加产量,只能物理上增加晶圆投片量,而不能指望技术升级自然带来产量翻倍。
1.2 扩产的成本刚性:从“摩尔定律”到“资本定律”
既然技术(制程)无法带来产能的爆发,那能不能靠堆钱(扩建工厂)?
分享人李总在会上分享的第二个产业真相:HBM(高带宽内存)正在对传统DRAM产能进行惨烈的“挤出效应”。
这是一笔简单的算账:
1)产能置换 :生产一颗HBM颗粒消耗的晶圆,是普通DDR5的3倍以上(因为Die Size更大,且需要额外制造Base Die)。
2)良率黑洞 :HBM需要堆叠8层、12层甚至16层,涉及极其复杂的TSV(硅通孔)和CoWoS封装。每多堆叠两层,良率就会下降10%以上。
3)利润驱动 :生产DDR4,毛利可能只有25%;生产HBM,毛利高达80%。
于是,一场阳谋诞生了:
三大原厂(三星、海力士、美光)达成了默契的“共谋”。他们并没有大规模新建产线(因为太贵、太慢,建一个厂要2-3年),而是将原本生产通用DDR4/DDR5的产能,通过改造去生产HBM。
导致的存储产业变化结果是:
1)DDR4被战略性放弃:三星和海力士已明确在2024年8月后大幅削减DDR4产能。这款服役了10年的老将,正在被强制退役。
2)供给刚性:即便你在2025年看到某些厂商宣布扩产,那也只是为了填补HBM造成的窟窿,通用内存的供给将长期处于“紧平衡”甚至“缺货”状态。

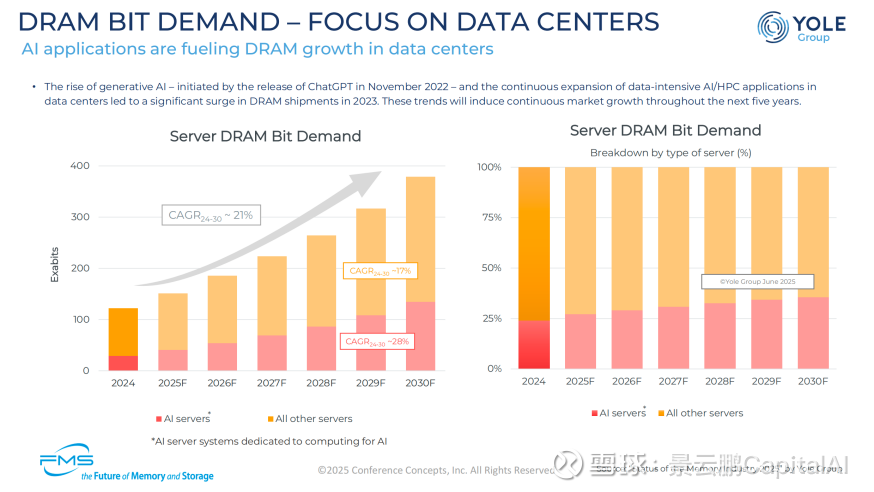
二、没有天花板的需求——AI Agent的吞噬
如果说供给侧是物理学锁死的“刚性”,那么需求侧就是被AI Scaling Law炸开的“无限性”。
很多人还在用“手机销量”或“PC换机周期”来预测存储需求,这是典型的线性思维。AI时代的需求,是指数级的。
2.1 英伟达的预言:Context is the New Bottleneck
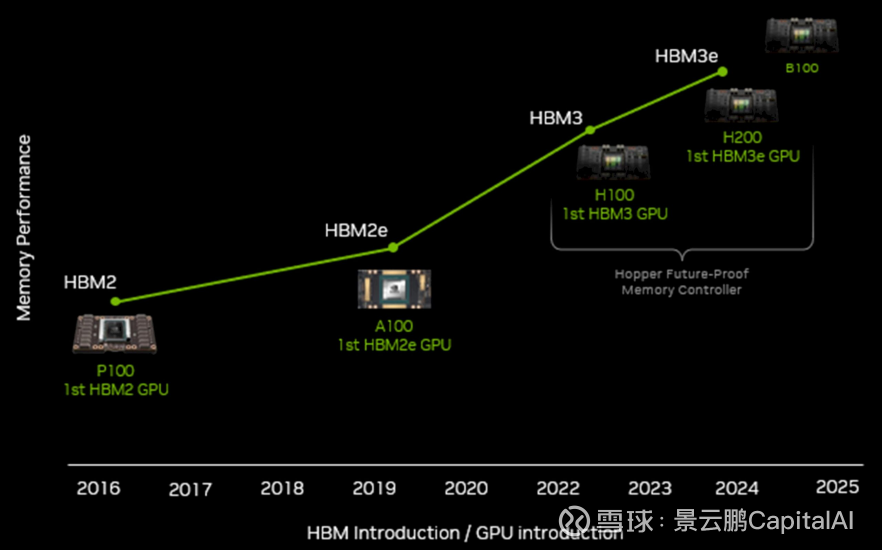
HBM和存储需求为何“看不到天花板”的四大需求因子:
1)Model Size(模型越来越大) :
从GPT-3的175B到GPT-4的MoE架构,再到未来的万亿参数模型,模型权重本身就要占用海量显存。但这只是“静态需求”。
2)Context Length per Agent(单体Agent的上下文窗口) :
这是最可怕的增量。以前我们用ChatGPT是“回合制”(Chatbot),问一句答一句。现在的Agent(智能体)是“任务制”。
你给它一个指令:“帮我写一个贪吃蛇游戏。”
Agent不会直接给结果,它会思考(Chain of Thought)、拆解任务、写代码、运行代码、报错、读取报错日志、修正代码、再运行……
在这个过程中,后台可能生成了数万次Token交互 ,所有的历史记录、报错日志、代码版本,全部都要塞进显存(KV Cache)里。
结论 :Agent时代的上下文需求,是Chatbot时代的100倍甚至1000倍。
3)Accumulated Context(累积上下文) :
随着多模态(视频、图像)的加入,Token的消耗速度不再是线性的。处理1分钟的高清视频,消耗的显存可能等同于读完一整部《红楼梦》。
4)Concurrent Users/Sessions(并发会话) :
当AI应用普及,并发用户数从百万级走向亿级,每一路会话都需要独立的KV Cache空间。
这四点因子叠加,构成了一个可怕的乘法效应。 这就是为什么黄仁勋会说:“Context is the new bottleneck.”(上下文是新的瓶颈)。
(笔者提示:以上关键是四因子,未来也会是硅谷和华尔街最大的预测分歧,华尔街认为2027年是存储的周期峰值,这种看法确实与AI驱动的底层技术逻辑不符。)
2.2 存储分级体系的重构:从HBM溢出到SSD
当HBM(显存)不够用时,数据往哪溢出?这涉及到一个极具前瞻性的产业趋势—— 存储分级体系的崩塌与重构。
Deepseek(深度求索)的技术实践被作为一个典型案例:
为了让大模型在推理时能够处理超长上下文(Long Context),他们开发了一套专门的文件系统,将海量的 KV Cache(键值缓存)放在了 SSD(固态硬盘)上。
[技术拆解:KV Cache的溢出效应]
这里的技术逻辑是这样的:
1)L1 级存储(HBM):最快,最贵($20+/GB),放模型权重和最热的激活值。但容量太小(单卡仅80GB/141GB)。
2)L2 级存储(DDR5):次快,较贵,作为HBM的后备弹药库。
3)L3 级存储(Enterprise SSD):容量大,便宜。
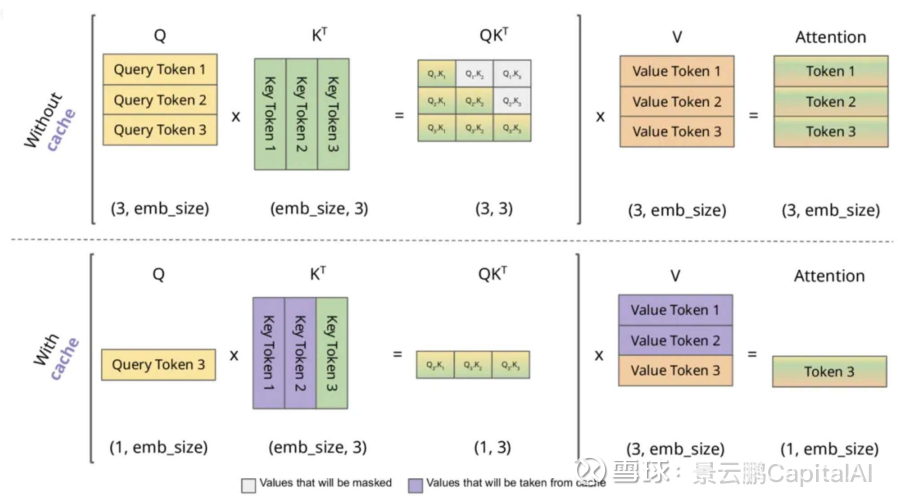
关键变化 :在Transformer架构下,推理(Inference)对 容量 的敏感度,在某些场景下已经超过了对 带宽 的敏感度。只要你想做长文本(1M Context)或者复杂的Agent任务,HBM一定是不够的。
结论 :数据会像洪水一样,填满HBM,溢出到DDR5,最后溢出到SSD。
这就是为什么近期企业级SSD(eSSD)价格也在暴涨的根本原因——它不再是冷数据仓库,它被迫变成了“慢速内存”。
2.3 SK海力士2031年DRAM发展路线图及最新进展
DDR6、GDDR8、LPDDR6和3D DRAM即将问世。
SK海力士在SK AI Summit 2025上发布了其DRAM发展路线图。虽然该路线图以非常概括的方式呈现,并未透露重要的细节,但仍然展现了DRAM技术的发展方向以及新技术出现的大致时间表。
由于SK海力士是在人工智能盛会上展示该路线图,其重点放在人工智能服务器领域。

传统的DRAM类型——例如DDR、GDDR和LPDDR——在可预见的未来仍将继续满足AI服务器的内存需求,尽管应用场景会有所不同。
与此同时,HBM内存将继续服务于对带宽要求极高的AI和HPC处理器。
SK海力士预计3D DRAM将于2030年问世。
未来几年,DDR5 将继续在成本、密度和性能之间保持平衡,其外形尺寸可能要等到 2026-2027 年才会推出,例如支持 12,800 MT/s 数据传输速率的第二代 MRDIMM,或者预计在 2027-2028 年上市的第二代 CXL 内存扩展器。DDR6 要到 2029 年或 2030 年才会问世;在此之前,DDR5 将继续发展演进。

LPDDR6 内存芯片目前已具备众多面向数据中心的功能,预计将在本十年末实现高容量、高性能和低功耗的完美结合。
SK 海力士预计,基于 LPDDR6 的 SOCAMM2 模块将于 2020 年代末期面世,届时英伟达可能会推出其 Vera 之后的 CPU,并需要新的内存子系统。
SK 海力士计划在 2028 年推出面向特定应用的 LPDDR6-PIM(模块内处理)解决方案。
至于GDDR7,它仍将是推理加速器(例如Nvidia的Rubin CPX)的专属解决方案,因为它兼具极高的性能和相对较低的成本(与HBM相比),但容量却严重不足。
SK海力士列出了“GDDR7-Next”,这可能指的是GDDR8,因为该公司并不以开发Nvidia专用解决方案而闻名,不像美光那样为Nvidia开发了GDDR5X和GDDR6X。
未来几年,SK海力士性能最高的DRAM解决方案将是HBM4、HBM4E、HBM5和HBM5E内存产品,这些产品将从现在到2031年以1.5到2年的周期陆续发布。
HBM5(据推测是英伟达Feynman显卡的动力来源,预计将于2028年底发布)似乎要到2029年甚至2030年才会面世。对于需要定制内存解决方案的客户,SK海力士还将提供定制的HBM4E、HBM5和HBM5E模块,但客户将如何定制这些设备还有待观察。


至于有望提供与HBM 相当的性能和与 3D NAND 相当的容量的高带宽闪存 (HBF)产品,SK 海力士预计它们在 2030 年之前不会面世,因为该公司必须开发全新的介质,并与其他 NAND 存储器制造商(特别是今年早些时候提出该技术的 SanDisk)就最终规格达成一致。

三、存储市场展望及竞争格局简述
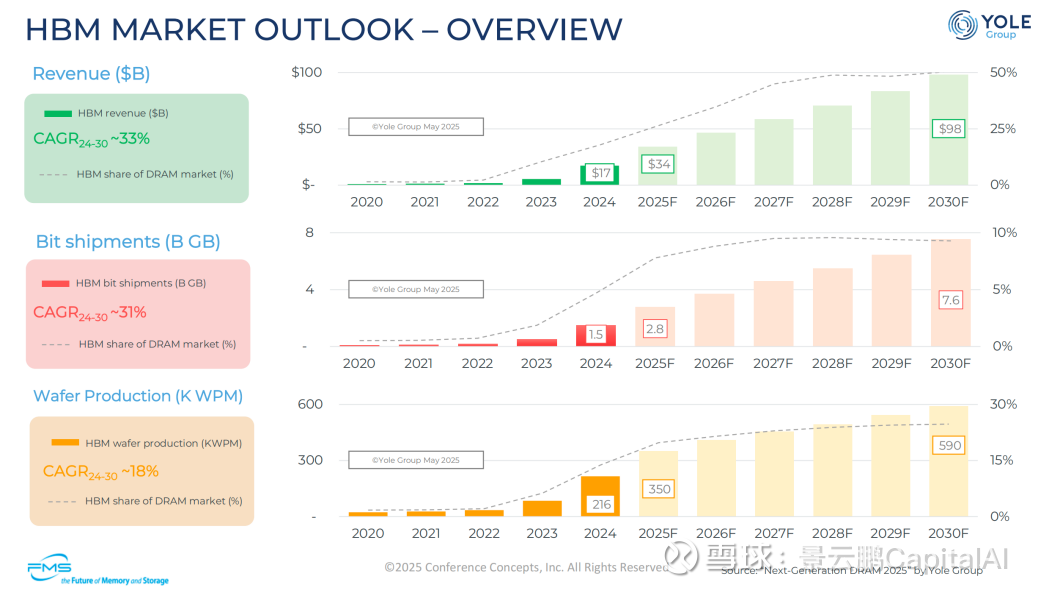
1、HBM 市场展望
根据产业机构预测,其收入趋势(单位:十亿美元)预计:
2024 年:17
2025 年(预测):34
2030 年(预测):98
2024-2030 年复合年增长率(CAGR):约 33%
HBM 占 DRAM 市场收入份额:逐步提升至 2030 年约 50%
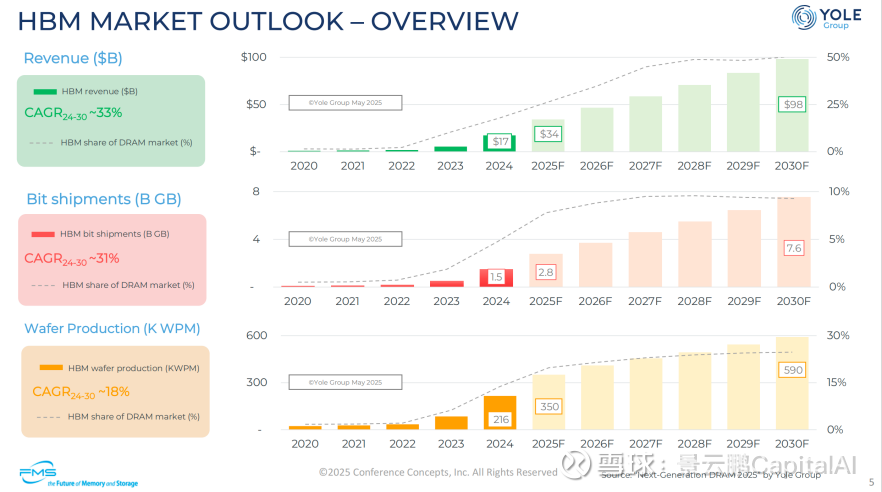
2、晶圆产量(单位:千片/月)
2024 年:216
2025 年(预测):350
2030 年(预测):590
2024-2030 年复合年增长率(CAGR):约 18%
HBM 占 DRAM 市场晶圆产量份额:稳步提升
3、市场格局
核心结构:高带宽内存(HBM)+ 处理器(xPU)
关键技术:硅通孔(TSV)与微凸点(Microbumps)+ HBM 堆叠
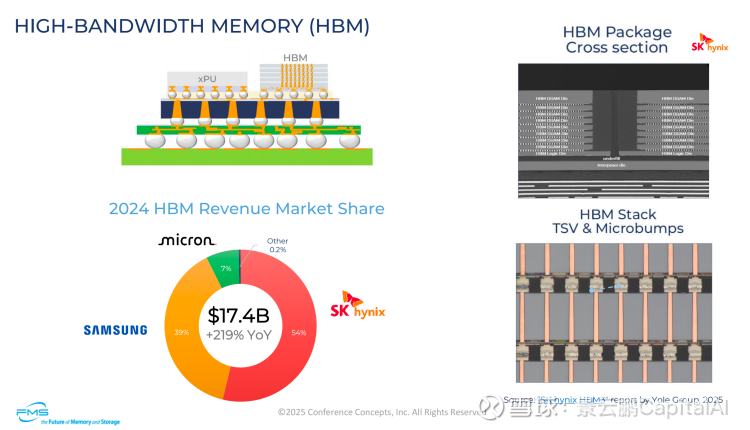
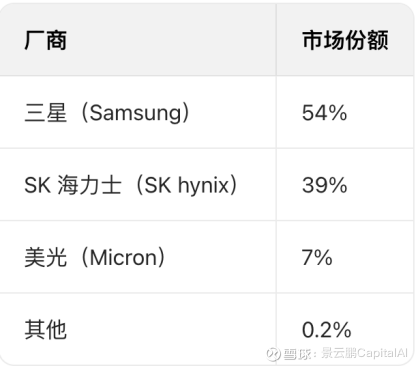
2024 年 HBM 收入市场份额(总收入 174 亿美元,同比增长 219%)
4、高宽带内存-全球供应链公司一览

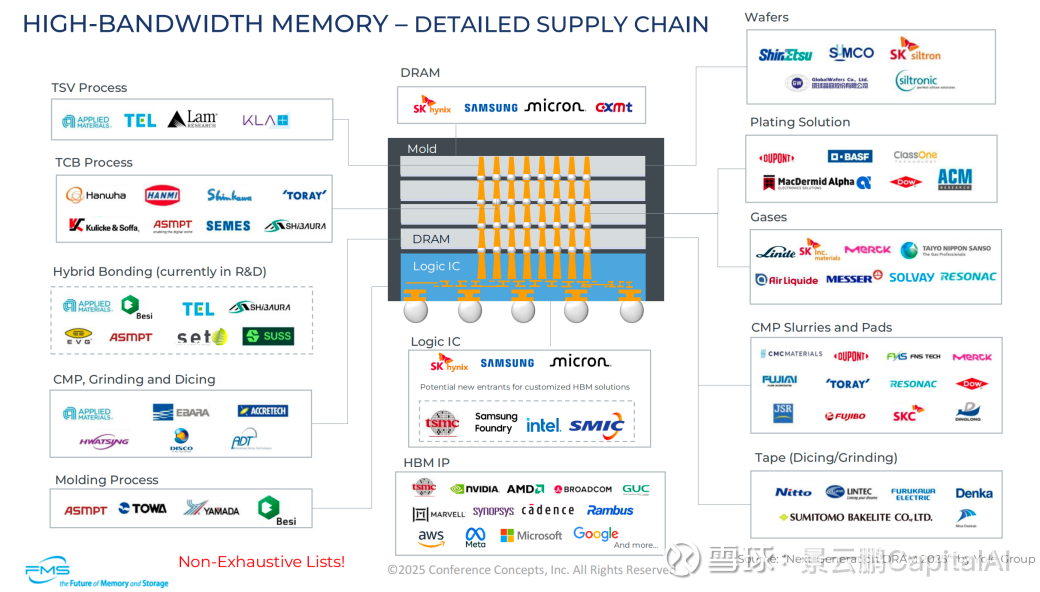
5、中国内地的HBM 生态系统中活跃的企业
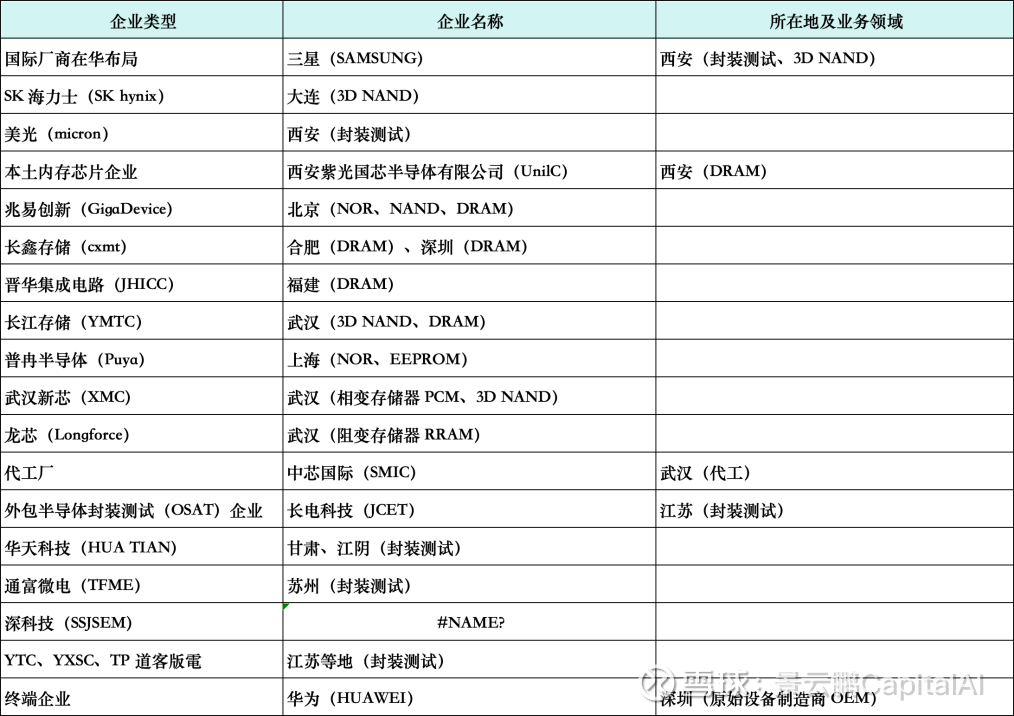
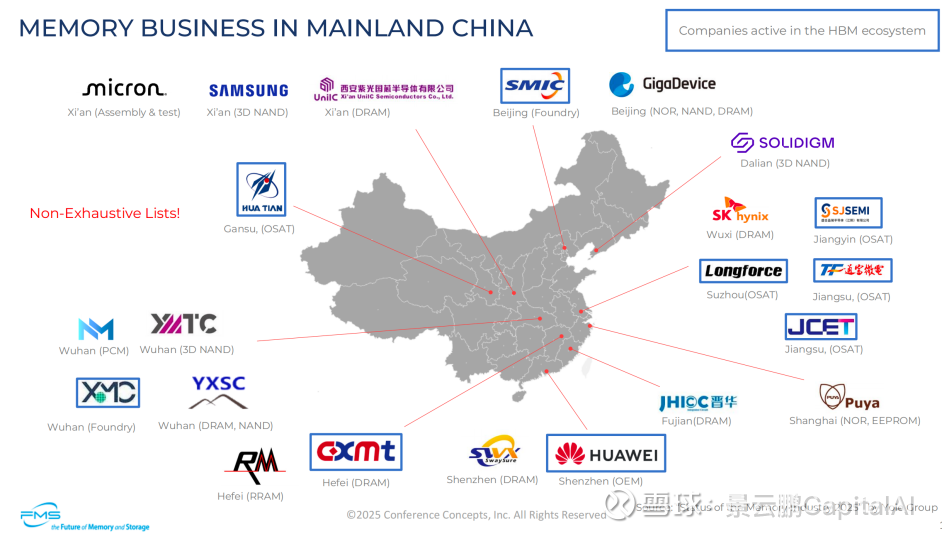
四、存储墙的突围——被忽视的技术变量
在阐述存储赛道“超级成长”成长性的同时,关注技术变量。科技投资最怕的技术迭代和技术颠覆。
如果发生技术突围,那么未来存储的某个时点,可能超级成长叙事会重回周期。
在“供需双杀”的宏大叙事之外,我们绝不能忽视技术的反噬。这就是我在回复中特别强调的“存储墙”技术 。
既然物理上很难把DRAM做得更密(1T1C极限),那能不能换一种连接方式?
4.1 CXL:内存的“共产主义”
CXL (Compute Express Link) 是2025-2026年最值得关注的架构革命。
痛点 :过去,内存是插在CPU旁边的“私有财产”。CPU A的内存,CPU B不能直接用,导致大量内存闲置浪费。
革命 :CXL协议允许建立一个 内存池(Memory Pooling) 。所有的CPU、GPU都可以通过CXL总线,像访问自己口袋一样,去访问这个巨大的共享内存池。
影响 :这直接利好 接口芯片厂商 (如澜起科技)。每一条CXL内存模组,都需要一颗高性能的控制器芯片。这就像是给每块内存条装了一个“路由器”。
4.2 PIM:让内存自己“动脑子”
PIM (Processing In Memory,存算一体) 则是另一种思路。
逻辑 :既然数据搬运(从内存搬到GPU计算)消耗了90%的功耗,那为什么不直接在内存里计算?
现状 :SK海力士已经展示了 GDDR6-AiM 和 HBM-PIM 产品。它们在内存颗粒内部集成了简单的计算单元,专门处理矩阵乘法。
趋势 :虽然PIM目前还是非主流,但在端侧AI和特定推理场景下,它是打破“功耗墙”的唯一解。
[观点补充]
CXL和PIM的出现,并没有减少对存储颗粒的需求,反而因为它们 降低了使用存储的门槛和成本 (提高了利用率),会进一步刺激下游配置更大的内存容量。这就像高速公路修通了(CXL),车流量(数据量)只会更多。

五:存储赛道投资图谱——在不确定性中寻找确定性
基于硅谷技术层面“超级成长”逻辑,以及传统重资产的强周期的逻辑下,目前至少可以判断2026年是存储的高成长确定性时点。
未来要持续跟踪产业进度,包括高端HBM的产能及扩产进度、国内NOR Flash 是否会随AI PC/AI Phone的需求爆发而爆发、MCU 的去库存、DDR4的渠道商库存和价格变化等。
基于存储一直以来的强周期属性,深耕赛道多年的投资人也坦言,不敢妄言存储赛道就可以持续维持高价格、高成长,尤其除高端HBM外的消费电子级的存储,渠道商库存是“黑盒”,不知道他们手里到底有多少库存,这点要观察,尤其2026年年中。
所以2026年投资存储赛道而言,首选当然是直接投资三星、美光、海力士,次选是国内产业龙头及长鑫的核心设备供应链。具体公司的投资和估值上,要投资者自行研判。
5.1 全球市场:拥抱垄断,买入“铲子”
最确定的标的,依然是那几个掌握了物理产能的寡头。
SK海力士 :目前在HBM良率和技术(MR-MUF封装)上最为领先,是英伟达的核心一供。 投资逻辑:技术垄断溢价。
美光(MU) / 三星 :它们拥有HBM的定价权,拥有10nm以下制程的入场券。只要AI浪潮继续,它们的业绩就是线性的。
Western Digital (WDC) / Kioxia :随着SSD在AI推理中的地位提升(Deepseek模式),NAND Flash厂商也将迎来价值重估。
5.2 A股市场存储赛道投资:夹缝中寻找阿尔法
A股的痛苦在于:我们没有真正的IDM(像三星那样既设计又制造的巨头)。长鑫(CXMT)和长存(YMTC)虽然强,但尚未上市或难以直接投资。
因此,A股的逻辑必须“拐个弯”,寻找供应链的溢出效应。
逻辑一:国产替代的“卖水人”——设备与材料
设备26年是成长逻辑。长鑫扩产,那么设备商就是“刚需”。
核心逻辑:HBM和高端DDR5的测试时间大幅延长,测试复杂度指数级上升。这直接利好测试机和分选机厂商。长川科技已经切入长鑫供应链,且有望在台积电成熟制程中获得突破。
前道量测:中科飞测 。国产化率极低,空间巨大。
探针卡:强一科技(刚上市)。这是消耗品,且国内竞争格局极好(几乎独家)。随着晶圆出货量增加,探针卡需求是线性的。
谨慎推荐:周期反转的“囤货商”——模组厂
逻辑:低价囤货,高价卖出。26年
风险:由于库存的消耗,2025年低价库存消耗大部分之后,26年业绩成长的确定性大打折扣。总体来讲,模组厂2026年投资要谨慎,成长确定性不足,具体公司具体分析。
逻辑二:细分赛道的“小而美”——设计公司
兆易创新 :
核心逻辑 :它是长鑫的“亲兄弟”(同一实控人背景),在DDR3/DDR4利基市场有代销权。当三大原厂退出DDR4时,留下的市场真空将由长鑫和兆易创新填补。
普冉股份 :
逻辑 :产品结构类比“小兆易”,收购了SHM,获得了企业级应用的技术积累。NOR Flash在端侧AI中有增量。
澜起科技 :
正宗的AI存力标的 。它的内存接口芯片(RCD/DB)是DDR5服务器的标配,且是CXL技术的核心受益者。这是纯粹的“量价齐升”逻辑。

六、结语
AI驱动的超级周期还在继续,从算力转向存力也是已经发生的必然产业趋势;
26年对于存储赛道是业绩大年,海外核心存储企业的高端HBM产能大部分已经被包圆,数据中心驱动高景气向eSSD等细分延伸;
A股的存储投资首选长鑫存储及其核心供应链,扩产周期上具备成长属性,其次是DRAM的国内产业龙头企业;
对于超级成长的叙事,投资人要理性看待,一方面认识到存储技术层面底层逻辑是“刚性”,包括成本刚性、扩产刚性等约束短期无法消除,以及NV阐述的存储超级成长的“Context is the New Bottleneck”;
另一方面也要理性看待存储历来是强周期属性,DDR4及以下等强周期老产品,是否重拾成长还需观察。
「风险提示」本文仅作为阐述存储赛道底层逻辑,仅阐述产业逻辑,文中提及的产业链公司不作为投资建议,请读者自行甄别,自行研判,本文不对读者投资行为负责,请注意投资风险。
【鹏友圈CapitalCircle】继续欢迎科技行业、半导体行业、有色化工顺周期行业的资深投资人、产业投资人、机构研究员等人士加入鹏友圈,一起分享讨论投资机会。
申请免费,仅要求加入后,未来做一期内部产业分享或投资分享。
欢迎更多符合要求的朋友,私信或邮箱背景履历、拟分享题目,我们一起拥抱2026年更多产业及投资机遇。Email: jypcapital@163.com