20260106 科蓝软件轻量级智能数据库 SUNDB LITE(华鼎) 商业航天 + 脑机接口 人脑工程

科蓝软件轻量级智能数据库 SUNDB LITE(华鼎)
$科蓝软件(SZ300663)$ 商业航天 + 脑机接口 人脑工程

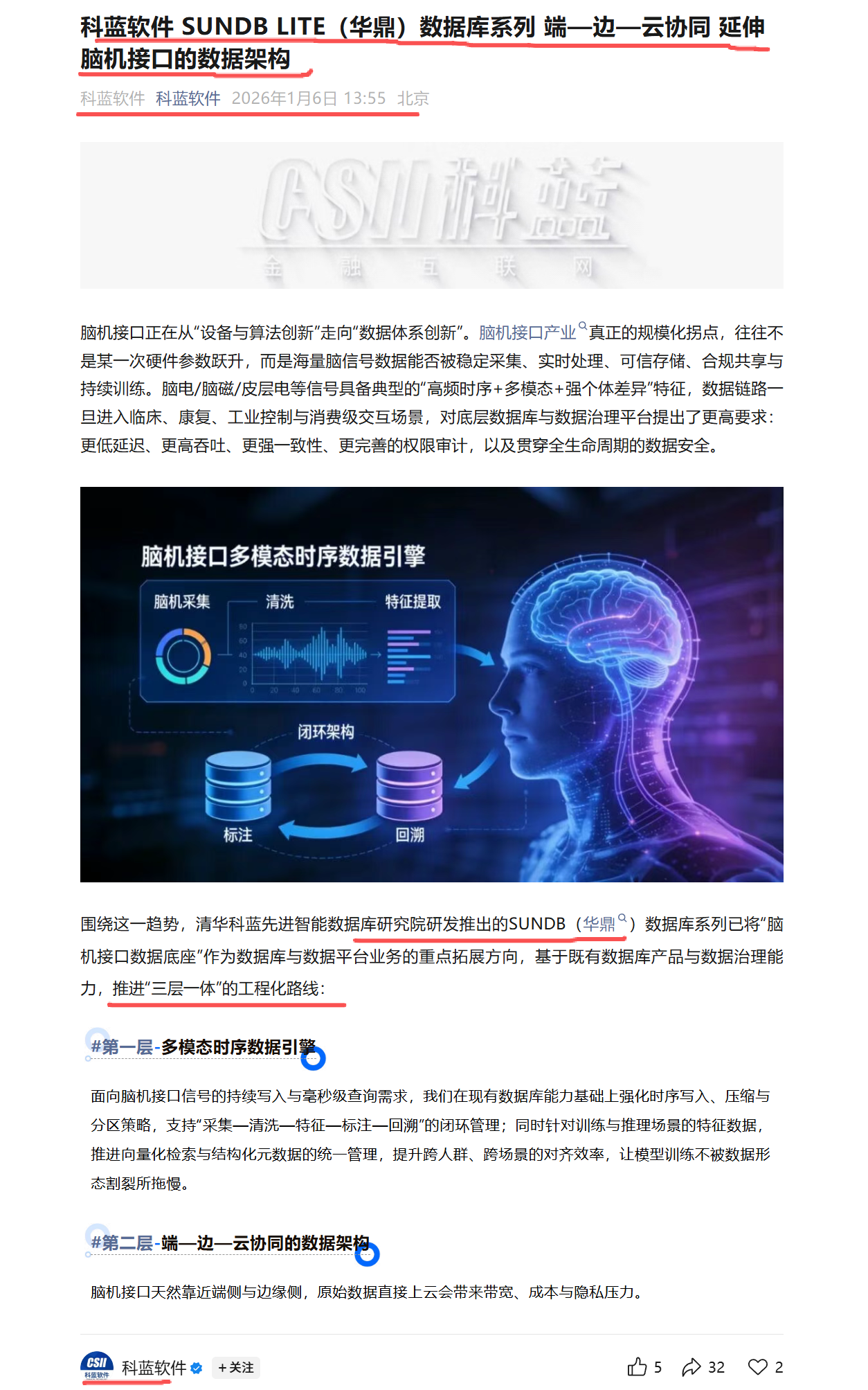
1.科蓝软件轻量级智能数据库 SUNDB LITE(华鼎),面向商业航天打造端侧数据底座
科蓝软件 2026年1月5日 20:41 北京
在小说阅读器中沉浸阅读
清华大学科蓝软件先进智能数据库联合研究院正式发布的轻量级智能数据库 SUNDB LITE(华鼎)面向“端—边—云”一体化架构,致力于在数据产生源头实现高效精炼与预处理,推动数据治理能力与智能边缘计算能力向端侧、边缘侧延伸,加速数据要素价值释放与规模化产业落地。
随着商业航天进入星座化部署与业务化运营阶段,遥感载荷、星基物联网、天地一体通信等应用持续产生海量原始时序数据。若对原始数据进行全量下传并集中至云端处理,将对通信链路、窗口期资源与云端存储计算带来显著压力,且难以满足应急响应、连续运营与安全合规等综合要求。商业航天亟需具备轻量化、可嵌入、可规模部署的端侧数据基础设施,在源头完成数据治理与价值提炼,边缘计算,实现“少传、优传、可信传”。
SUNDB LITE以轻量级智能数据库为核心,采用软硬结合的嵌入式部署形态,将数据库能力与智能处理能力下沉至端侧与边缘侧,支持对时序数据的本地接入、组织管理、筛选精炼与策略化上送。通过在源头就地消化冗余数据,显著降低网络带宽占用与云端资源负担;同时将高价值数据与关键事件按需上送至云端进行汇聚融合、深度模型训练与全局优化,形成“端侧智能处理—边缘协同计算—云端集中训练与决策支持”的闭环体系,全面支撑商业航天从“数据获取”向“数据服务”“智能服务”升级。
面向商业航天典型业务场景,SUNDB LITE可提供关键支撑能力:在遥感应用中,可在星上或地面边缘节点对海量载荷与工况时序数据开展预处理与事件化组织,优先保障关键事件与高价值数据的传输与服务响应;在星基物联网应用中,可在边缘网关与行业终端侧实现多源数据聚合、去重与策略分发,提升数据可用性并降低通信成本;在在轨健康管理与运维保障中,可对关键部件与系统工况进行持续沉淀与轻量分析,强化异常预警、证据留存与闭环诊断能力,提升星座运营可靠性与服务连续性。
在安全与合规方面,SUNDB LITE坚持分层治理理念,强调端侧“可信入口”能力,通过策略化处理、权限约束与可审计机制,为天地链路传输与云端融合提供安全可控的数据基础,满足多主体协同运营模式下的数据边界与数据主权管理需求。随着商业航天、卫星、无人机在公共安全、能源、水利、海事、交通等行业不断深化应用,安全可信的实时数据采集、传输与边缘计算分析能力将成为行业规模化落地的重要支撑。
清华大学科蓝软件先进智能数据库联合研究院表示,SUNDB LITE的发布是研究院围绕“端—边—云”协同计算与数据分层治理方向的重要成果。下一步,研究院将持续推进产品在商业航天、卫星、无人机等重点领域的示范应用与规模化部署,联合产业伙伴开展场景共建与生态协同,推动轻量级智能数据库与嵌入式智能体能力在更多智能设备与智能终端中落地应用,进一步服务国家从“互联网+”向“人工智能+”迈进的发展战略,为智能经济与智能社会建设提供坚实支撑。
2.科蓝软件 SUNDB LITE(华鼎)数据库系列 端—边—云协同 延伸脑机接口的数据架构
科蓝软件 科蓝软件 2026年1月6日 13:55 北京

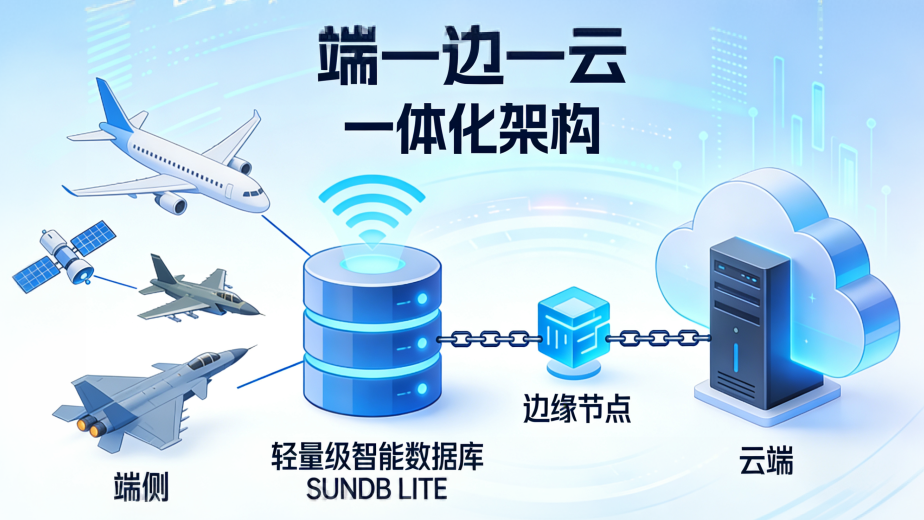
脑机接口正在从“设备与算法创新”走向“数据体系创新”。脑机接口产业真正的规模化拐点,往往不是某一次硬件参数跃升,而是海量脑信号数据能否被稳定采集、实时处理、可信存储、合规共享与持续训练。脑电/脑磁/皮层电等信号具备典型的“高频时序+多模态+强个体差异”特征,数据链路一旦进入临床、康复、工业控制与消费级交互场景,对底层数据库与数据治理平台提出了更高要求:更低延迟、更高吞吐、更强一致性、更完善的权限审计,以及贯穿全生命周期的数据安全。
围绕这一趋势,清华科蓝先进智能数据库研究院研发推出的SUNDB(华鼎)数据库系列已将“脑机接口数据底座”作为数据库与数据平台业务的重点拓展方向,基于既有数据库产品与数据治理能力,推进“三层一体”的工程化路线:
#第一层-多模态时序数据引擎


面向脑机接口信号的持续写入与毫秒级查询需求,我们在现有数据库能力基础上强化时序写入、压缩与分区策略,支持“采集—清洗—特征—标注—回溯”的闭环管理;同时针对训练与推理场景的特征数据,推进向量化检索与结构化元数据的统一管理,提升跨人群、跨场景的对齐效率,让模型训练不被数据形态割裂所拖慢。
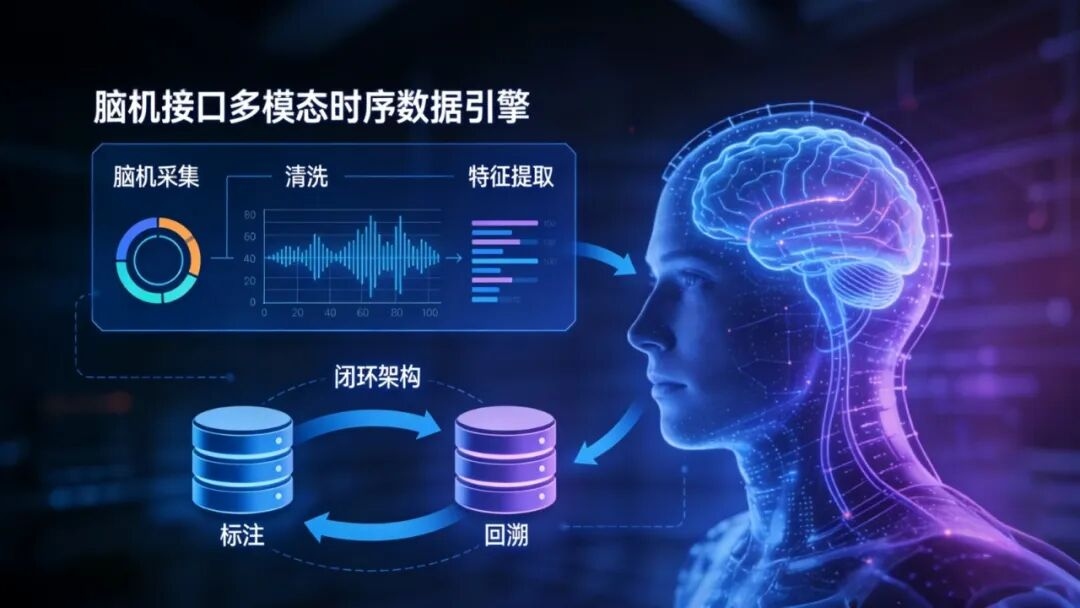
#第二层-端—边—云协同的数据架构


脑机接口天然靠近端侧与边缘侧,原始数据直接上云会带来带宽、成本与隐私压力。
清华科蓝先进智能数据库研究院研发推出的SUNDB(华鼎)数据库系列SUNDB LITE,以轻量化数据库与边缘计算能力为抓手,推动“端侧就地预处理、边缘事件化汇聚、云端集中训练与全局优化”的分层治理,既降低传输冗余,也为实时交互场景提供稳定低时延保障。
#第三层-合规可控的数据治理与可信共享


脑机接口数据的敏感度决定了“能共享”必须建立在“可控、可审计、可撤销”的前提上。我们将把在数据资产管理、元数据、数据质量、血缘与审计等方面的能力沉淀,体系化迁移到脑机接口场景,形成面向多中心研究/临床协作的分级授权、最小权限、脱敏与可控流转机制,并通过全链路留痕实现可追溯、可问责,支撑产业从单点试验走向多机构协同与规模化应用。
下一步,我们将以“数据库根技术+行业工程化”双轮驱动,推进脑机接口数据底座的标准化接口与生态适配:一方面面向设备厂商、科研机构与应用方开放可插拔的数据接入与治理组件,降低集成门槛;另一方面通过场景验证持续打磨高并发写入、跨节点一致性、容灾与连续服务能力,形成可复制、可交付的行业方案。我们相信,脑机接口的长期竞争力最终会体现在“数据能力”上——谁能把数据管住、用好、用稳,谁就更接近下一代智能交互的关键底座。