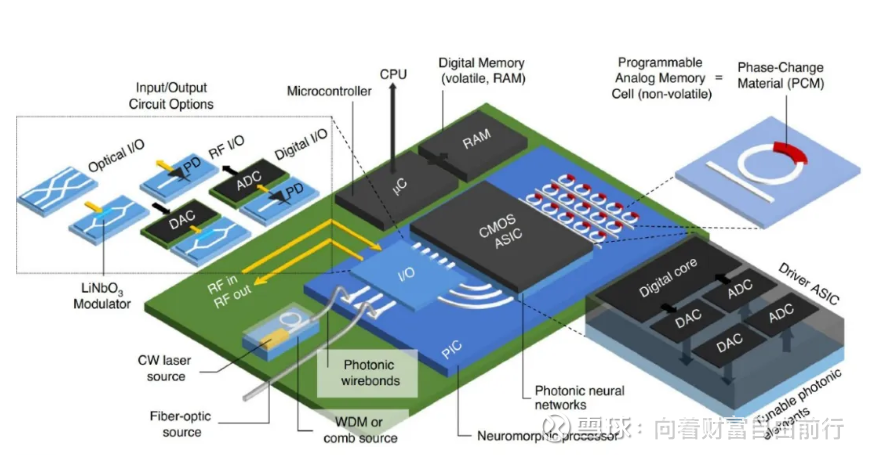
罗博在这次Ai革命中的位置和价值

AI是在算力基础上诞生的一朵花,一朵可称得上是第四次工业革命的花。其土壤算力基本上是计算和通信两块,这篇文章我讲从六个章节来讲罗博特科的价值,分别是集成电路芯片、集成光路芯片、光互联、量子计算、罗博特科的设备、摘取上会稿的内容。
一、集成电路
其中,集成电路主要是GPU、ASIC、TPU等等,也可以说是各种XPU。
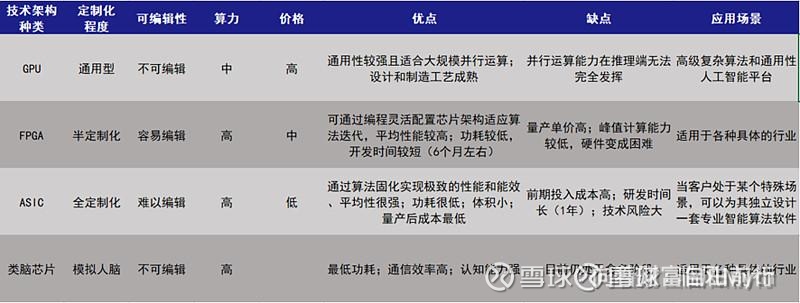
XPU里面核心是三种模块,控制、计算、存储,分别对应下图的 control、ALU、cache(闪存)/dram(内存)
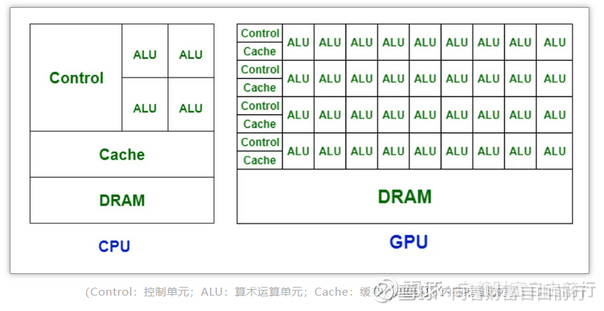
为了算力,一个芯片内,放这三者的数量要更多,距离要更近,这就对制程要求越来越高。但制程存在极限,电路越细就越容易发生量子隧穿和升温,目前我们人类已经接近极限,最先进的英伟达和台积电的GPU芯片越做越大,在制程领域已经快走到头了。
二、集成光路芯片(光芯片)
研究人员借鉴日趋成熟的集成电路的设计思路,在1969年提出了集成光路的概念。
所谓集成光路就是将各种功能的光学器件包括光源、耦合器、调制器、探测器等集成到同一个衬底上,并由集成光波导连接形成一个具有更高级功能的光学系统。
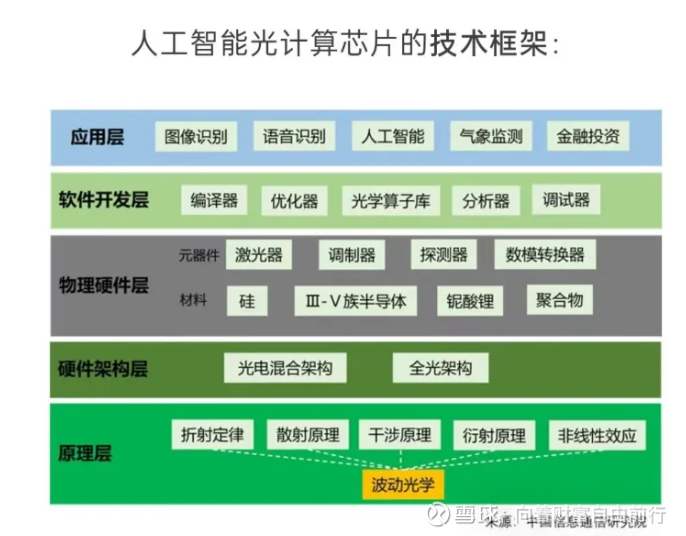
后摩尔时代,光芯片是算力提升的关键,有潜力提供至少两个数量级(即100倍)的速度提升和三个数量级(即1000倍)的能效改善。
光芯片又分为计算用的和互联用的。
光计算芯片有2种类型,全光架构、光电混合架构。前者很牛逼,但是商业化量产难,主要是因为光功率损耗导致扩展性低,串扰噪声,集成难。
光电混合架构,正在商业化。
光电混合架构,有用光计算的,有用电计算的。我自己感觉电计算比光计算靠谱。
这玩意有多牛呢?近段时间清华大学戴琼海团队研制出国际首个全模拟光电智能计算芯片,电路部分采用180nm CMOS工艺,已取得比7nm制程的高性能芯片多个数量级的性能提升,且造价仅为后者的几十分之一。
这是光计算的:
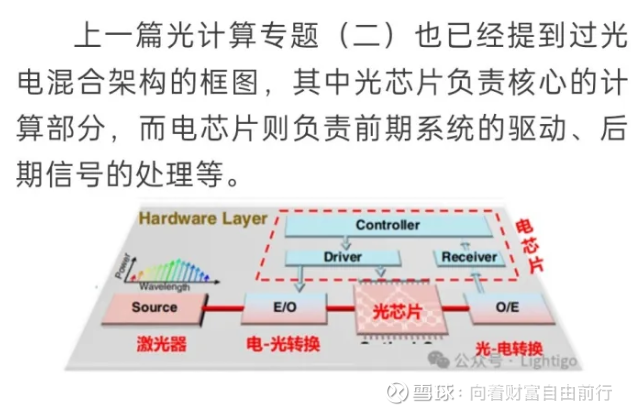
这是电计算的:
三、光互联
说完光计算,再来看光互联。主要是CPO、OIO、ONoC。
CPO主要用于数据中心的以太网网络。
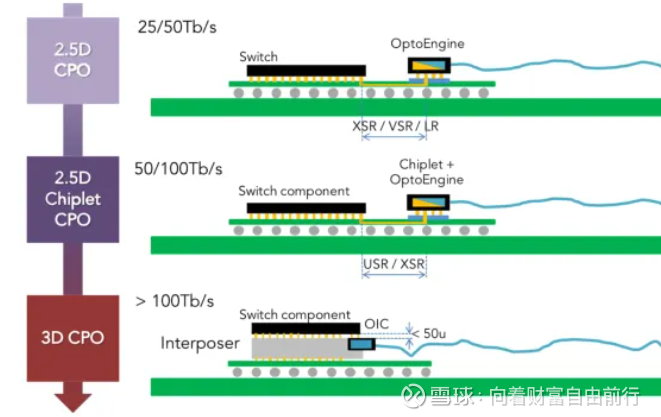
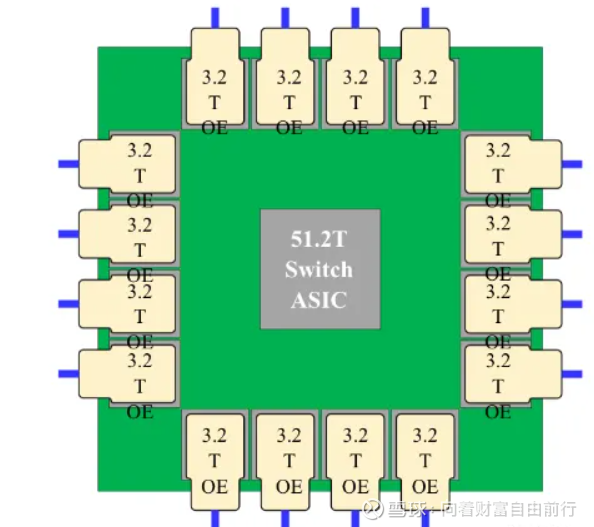
典型的CPO如下:
OIO,用于XPU到XPU的互联。
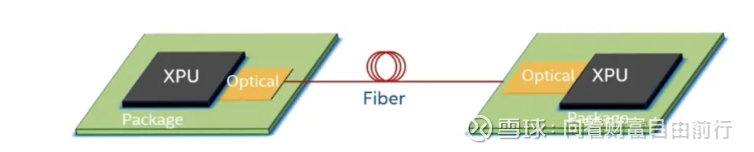
二者的地盘:
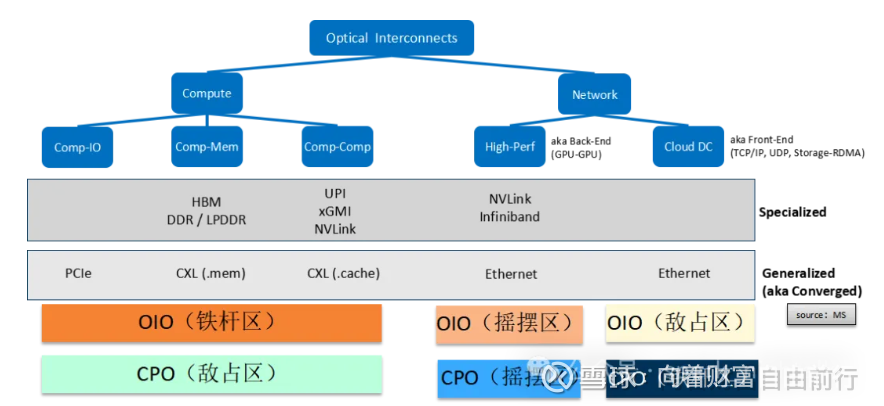
ONoC是片上光网络(Optical Network-on-Chip),简单说就是将芯片内部的通信也用光网络来进行替代。这玩意的价值在哪里呢?
像H100这样的卡贵在哪里?首先,制程贵,动辄3nm的制程,因为要在单颗芯片上集成尽可能多的计算单元,片上NOC(Network on Chip)的效率是远远高于片间通信的效率的;其次,存储贵,如果只是4090这样的显卡,GDDR价格可能还能接受,但是云端GPU使用的HBM,价格就很夸张了,而且在AIGC当道的今天,显存速度和运算速度是强相关的,所以大家也只能咬着牙堆HBM;此外,卡间互联,先进封装,乃至大芯片的散热,也没有一个便宜的,这些因素共同导致了云端GPU的贵。云端GPU需要涉及大存储,高带宽,和高速卡间高速互联,所以“贵点”,一个都绕不开。
解决方案呢?用ONOC替代传统NOC。片上光网络。就是将芯片内部的通信也用光网络来进行替代。以前家里的宽带从电线入户变成了光纤入户,那么ONOC就可以理解为光再进一步,从光纤进门(芯片之间的光通信)到光纤入室(家里内部的通信也是通过光纤)。片上光网络的价值就是功耗小、带宽高、延时低,还和光通信可以无缝衔接,此外,对不同类型计算单元之间的互联还很友好,类似于Chiplet的感觉。想象一下,一长串面积为50 的12nm计算单元通过ONOC互联,和一颗3nm的面积为800的大号芯片,哪一种的扩展性更强,哪一种的良品率更高,哪一种的价格更低。而且,全光通信可以避免PCIE需要用ReTimer/ReDriver(用来解决电信号质量的小芯片)所带来的麻烦,极大提升“显卡面积”,实现弯道超车,这就是中国算力要走的路,也是$罗博特科(SZ300757)$ 最有价值的地方。即XPU分解。把XPU的 control、ALU、cache(闪存)/dram(内存)都通过光电转换联接分为control、ALU、cache池,彻底打破芯片物理边界,打破先进制程瓶颈,所以我一直说罗博是中国算力弯道超车的关键,是大龙的气眼。
四、量子计算量子芯片的原理:量子叠加:传统的二进制比特只能表示0和1两种状态,而量子的特点就是叠加,1个量子比特可以同时包含0和1,也就是2个信息,2个比特就是4个,只要到50个就达到了传统计算机的水平。
如果是300个呢?就超过了宇宙中所有原子的数目。持有量子本体论的人认为,上帝在创造世界的时候,底层框架就是量子。这种特性使得量子芯片能够同时处理多个状态,极大地提升了计算和存储能力。
量子纠缠:量子纠缠是指两个或多个量子比特之间存在一种特殊的相关性,使得它们的状态相互关联。这种特性使得量子计算能够实现高度并行的计算方式,加快计算速度。
量子相干:量子相干是指在量子系统中不同态之间的干涉与相互作用现象。它实现了量子比特之间的信息传递和操作,是量子计算的基础。
量子芯片怎么制造:
有光和电两个技术路线:
光量子芯片: 制造量子芯片,需要我们首先找到可以进入量子态的物质。可能最先想到是粒子,例如九章量子原型机所使用的光子,九章用光子的偏振方向代表1和0,从单一光源发射出一个光子,然后用特定设备把光子劈开,劈出的两个光子就获得了量子纠缠的状态。
劈出的光子量子比特在光路之中运行,我们再通过对光子的干涉来改变光子的量子状态,根据缠绕结果最终实现运算,再换成离子,铍、镁、钙这些最外层只带一个电子的离子可以被电场束缚起来,就像是磁悬浮列车一样,悬浮在半空固定起来,这就叫离子阱。
而离子的能级正好就能表示1和0,要想操作这些离子状态就需要用激光正好照射到单个悬空的离子上,改变离子的能级。
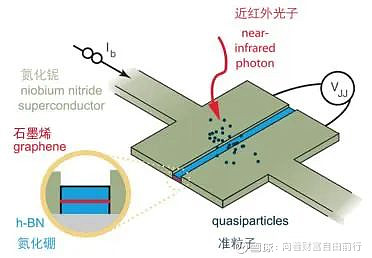
但光量子芯片的问题是:第一个光子芯片完全就跟当年人类第一台30吨的计算机一样,太复杂,太大。目前我们还没有成熟的集成光子技术。第二个离子阱需要用激光操作,也太复杂了。需要工程能力突破,降低体积,提高各种器件的精密制造水平。电量子芯片技术路线: 而现在电量子芯片可以做出来看起来跟正常芯片看起来差不多的量子芯片。关键在于能利用超导现象。
英国物理学家约瑟夫森(Brian D. Josephson,1940年1月4日-,1973诺贝尔奖获得者)在22岁的时候发现一个现象,就是如果在两个超导体之间加一层纳米级别很薄的绝缘材料,那么此时通过量子隧穿效应,超导电流也是可以通过这层绝缘材料的。
简单地说是绝缘材料导电了。这就是约瑟夫森效应,实验装置叫约瑟夫森结。那么现在我们再把约瑟夫森结放入超导电路,就会变成一个量子二级系统,也就是变成了实现量子控制的小装置。
操控光子困难,操控电流简单,这就是为什么谷歌微软这些大公司都选择超导电流来造量子计算机。他们用含约瑟夫森结的超导电路中的电磁震动做为0和1表达,用这种思路造出来的量子芯片,虽然也需要在接近绝对零度的条件下才能出现超导现象,但比着劈开光流的思路,这种更好实现太多了。
五、罗博特科的设备
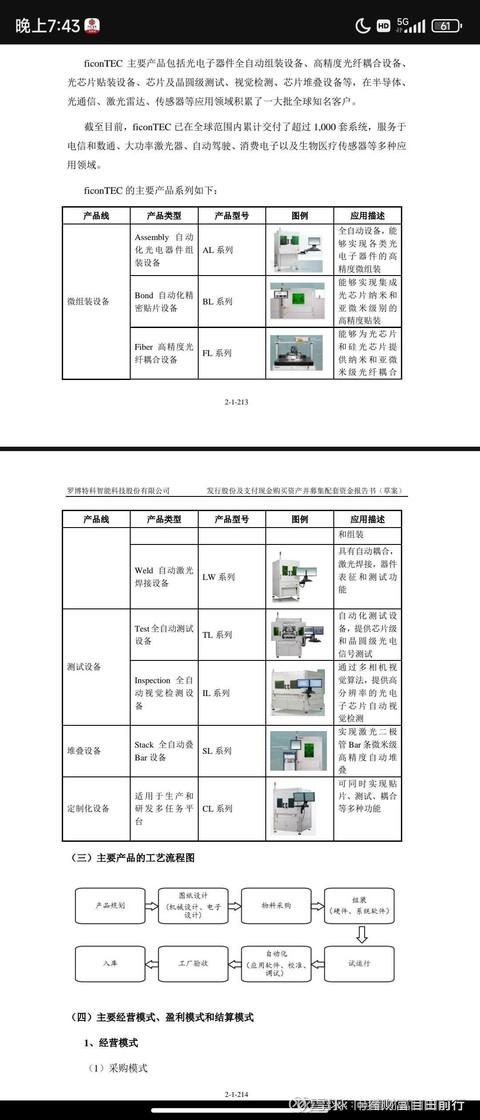
罗博特科的设备,大家关注的主要是要装入上市公司的ficontec设备,这里光伏板块的设备不展开。ficontec已经被罗博特科牵头的财团收购,装入上市公司只是时间问题。
ficontec的设备主要是精密自动化组装、高精度光纤耦合、芯片贴装、芯片CP和FT阶段测试、视觉检测、芯片堆叠设备。需要注意的是这些设备背后的可量产的高精密组装、光纤耦合、物品定位、挪移能力才是关键,这些技术实力是全球第一的,有了这些,后续很多市场都可以做,而不仅限于我们目前看到的这些市场。
博通万亿美元市值和184倍pettm 意味着推理算力的超级景气和巨大空间,也意味着asic的潜力
asic对先进制程要求低,看看寒武纪 地平线机器人 就知道了,都是没有先进制程,但是产品有人买,后者还是中国智能网联汽车车载芯片Top2市场份额的存在,用16纳米制程就可以了
当推理算力制程重要性下降的时候,互联就是最重要的最有价值的
无论是现在的asic算力,还是未来的光计算 光量子 电量子,都非常需要互联(cpo oio onoc)
互联就需要光纤传输
光纤和芯片是不同材料,前者主要是二氧化硅等玻璃材料,以后可能用空芯光纤,后者是主要是硅基半导体材料,注定需要萝卜的光纤耦合设备给二者对接到一起
这块的价值和壁垒,ro大已经写了
同样其他市场也是一样
ficontec的下游市场价值和竞争壁垒、技术领先程度,都在这个上会稿里有点出,只是很多人看不透门道:

精度*稳定性(关乎精度、寿命、利用率) 是这些设备最重要的两个指标
罗博特科收购的飞控的设备是用AI来自动调整精度(能到5纳米的精度…)、运行状态和自动分析环境(背后的数据也是高壁垒)、零部件状态的,需要修理和更换零部件的话会自动提示
这种技术水平,我生平仅见,无论是发那科 阿斯麦 Abb 库卡 大连机床,你听说过用Ai来运营设备的吗?而萝卜最少2-3年前,就这么干了,而且交付客户了
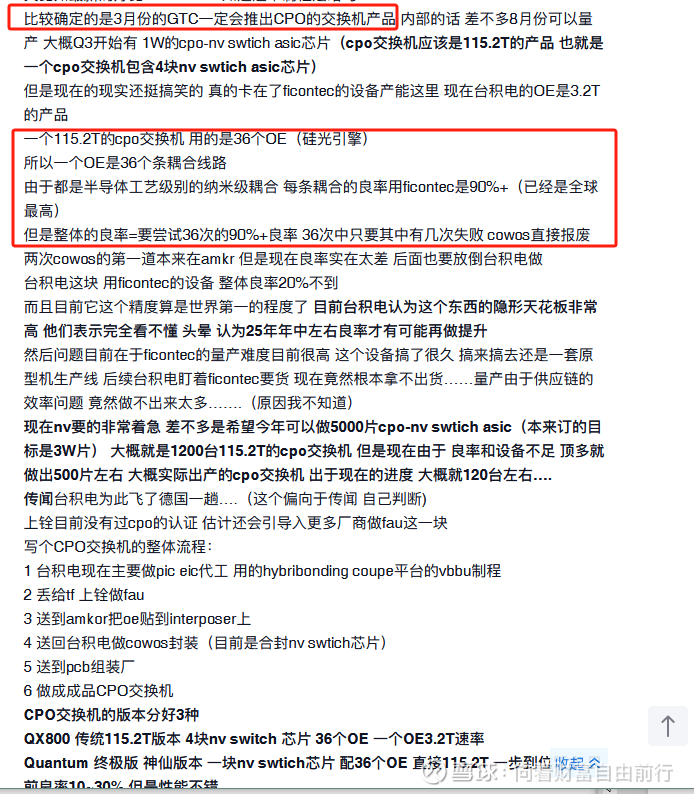
目前我的判断是,萝卜最有壁垒的是CPO OIO onoc要用的光纤和芯片耦合的设备,垄断地位,未来AGI、智能驾驶、机器人等需要的边缘算力、推理算力、云计算等需要这些设备来提升信息传输能力
剩下部分几乎是全球龙1地位,虽达不到垄断地位,比如各种光器件组装【硅光模块(目前封装占成本约8成,都要被设备替代)、激光雷达、大功率激光器】等,但也很值钱,任何一块做好了都能单独造出一个市值超越现在萝卜市值几倍的上市公司还有,芯片贴片(芯片行业主要后道设备、封装设备之一)、光电芯片检测(芯片行业主要后道设备、封装设备之一),也是任何一块做好了都能单独造出一个市值超越现在萝卜市值几倍的上市公司
还有部分价值量没有那么高的市场,我就不提了
如果是闷大提到的“交钥匙”的全产线Turnkey模式,那萝卜的估值最少翻倍算力弯道超车的关键就在全光互联,全光互联的关键是 硅光芯片制造封装能力*光纤和芯片耦合、检测的互联能力,而且萝卜的设备是联合攻关、AI运维的,粘性很高,议价能力强
六、最后再摘一段上会稿的内容
无论是CPO、OIO、ONOC、还是光计算芯片、光量子芯片,核心是硅光技术。硅光技术的核心是利用硅基材料(如SOI或Si)集成光子学器件,结合CMOS半导体制造技术,实现高性能、低成本的光通信技术。看看公司公告是怎么说的:但由于电信号传输会有信号损失的问题,即使单位面积晶体管数量渐增,仍无法避免电耗损的问题。然而硅光子技术$罗博特科(SZ300757)$ 的出现,【以光信号代替电信号进行高速资料传输,实现更高频宽和更快速度的数据处理,使芯片不需挤更多晶体管数量,不需追求更小纳米和节点】,(这里需要高度注意:这是硅光设备的核心价值所在)(再看前文清华大学戴琼海团队研制出国际首个全模拟光电智能计算芯片,电路部分采用180nm CMOS工艺,已取得比7nm制程的高性能芯片多个数量级的性能提升,且造价仅为后者的几十分之一),且能在现有硅制程基础上实现更高集成度、更高效能的选择,进一步推动摩尔定律的发展。由于高频宽、小尺寸、低能耗和成本效益等优势,硅光子在通讯和高速运算领域极具发展潜力,可应用于生医感测、量子运算、机器学习、激光雷达等领域。这些应用潜力将带来革命性的变化。
硅光技术难在哪里?再看看公司公告,尽管硅基光电子发展迅猛,但由于其工艺复杂性和硅材料的天然特性,硅基光电子技术仍然面临着不小的挑战,其中重要的一点就包括光纤和波导的高效耦合、封装。传统的光模块采用自由空间的设计方式,对于封装耦合的精度要求较低,通常采用人工或半自动耦合的方式,封装的成本较低。硅光模块集成度高,封装难度大,硅光子封装的两个主要挑战是尺寸适应(因为光纤直径为 125 微米,而集成波导的直径只有几微米)和模态适应,其耦合对准与封装的精度要求高,较难实现高质量、低成本的封装。因此,传统耦合封装方式无法满足硅光模块的大规模生产需要,必须采用高精度的自动耦合封装设备保障封装精度、良率和效率,降低生产成本。根据 Yole,目前阶段在硅光模块成本中,硅光芯片仅占约 10%,封装成本占比约为 80%(注:需要萝卜设备去替代人工降本)。硅光芯片发展的同时也推动了高精度全自动耦合封装设备的发展,两者互相促进。硅光芯片的耦合封装方案不尽相同,因此设备提供商往往较早就介入硅光模块的设计过程,通过共同设计和验证来保证耦合封装设备能够满足大规模量产的需求。随着封装在硅光电子产业中扮演越来越重要的角色,相关公司不仅是设备提供商也正在成为服务和技术提供商,这种技术涉及到包括光纤耦合、共晶贴装和光电测试等众多领域。目前,全球范围内能够提供满足硅光和 CPO 产品耦合、封装、测试需求的设备供应商较少,目标公司 ficonTEC 是主要供应商之一,能够提供全方位的耦合、封装、测试设备解决方案,是 Intel 硅光方案和 Broadcom CPO 方案的主要合作伙伴之一。
再看看竞争格局。光电子半导体耦合、封装测试设备目前主要由欧洲和美国公司主导,国内公司普遍规模较小,技术先进性不足,国际上主要的竞争对手包括 Mycronic、Finetech、KLA、Camtech、Teradyne 等。ficonTEC 在光子半导体领域拥有较为齐全的产品线,主要产品包括光电子器件全自动耦合封装设备、高精度光纤耦合设备、光芯片贴装设备、芯片及晶圆级测试、视觉检测、芯片堆叠设备等,在高精度耦合封装方面技术水平全球领先。国际上主要的竞争对手多数从事其中一类或几类设备的研发和生产,且耦合精度以及效率与目标公司$罗博特科(SZ300757)$ 相比不具备优势。特别是在硅光芯片和 CPO 领域,目标公司掌握的技术处于世界领先水平,持续为 Intel、Cisco、Broadcom、Nvidia、Lumentum、Velodyne 华为等客户在硅光模块、CPO、高性能计算、激光雷达等产品设计和量产过程中提供支持。经过十余年的发展,ficonTEC 在全球范围内累计交付设备超过 1,000 台,广泛应用于下游光电子行业以及高校、科研机构光子技术研究领域,在全球范围内拥有广泛的合作伙伴,在行业内具有较高的知名度和行业地位。