
混沌之泊
· 北京
如下是各种先进的NPU计算的能效和延迟对比
第一列是传统的近存计算,SRAM+ALU,计算能效10~50TOPS/W
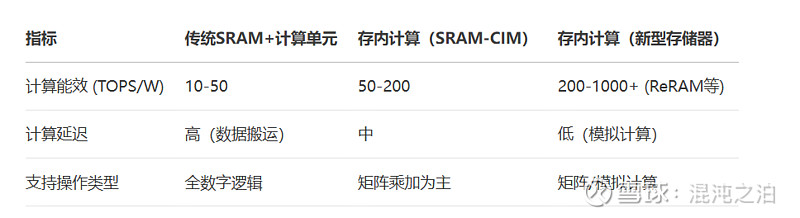
恒玄目前主要是采用这种成熟的技术,随着工艺的提升,可以在芯片面积不变时,主芯片随工艺提升缩小面积的情况下加大 SRAM的面积,而SRAM的尺寸也会随工艺提升变小。像 恒玄 6nm BES2800BP的内置SRAM高达8.3MB。
某些友商宣传的存内计算方案未来已经能够实现近10TOPS/W(目前好像是6.4TOPS/W)。 其实能效 和传统的SRAM+计算单元相差不大。相较高投入的先进工艺而言,是一种在仅在小NPU上追赶高能效的方法。0.1TOPS = 100GOPS 的算力规模,适用于语音识别(RNN/TinyML)、简单图像分类等任务,计算密度不足以发挥CIM优势。CIM在>1TOPS场景才具性价比
