商汤的“徐立时刻”:分拆是表,算法是里,垂直场景才是真正的开花


$商汤-W(00020)$ 一份藏着“质变”信号的年报,也是来一份AI老兵的重构价值交出的成绩单。
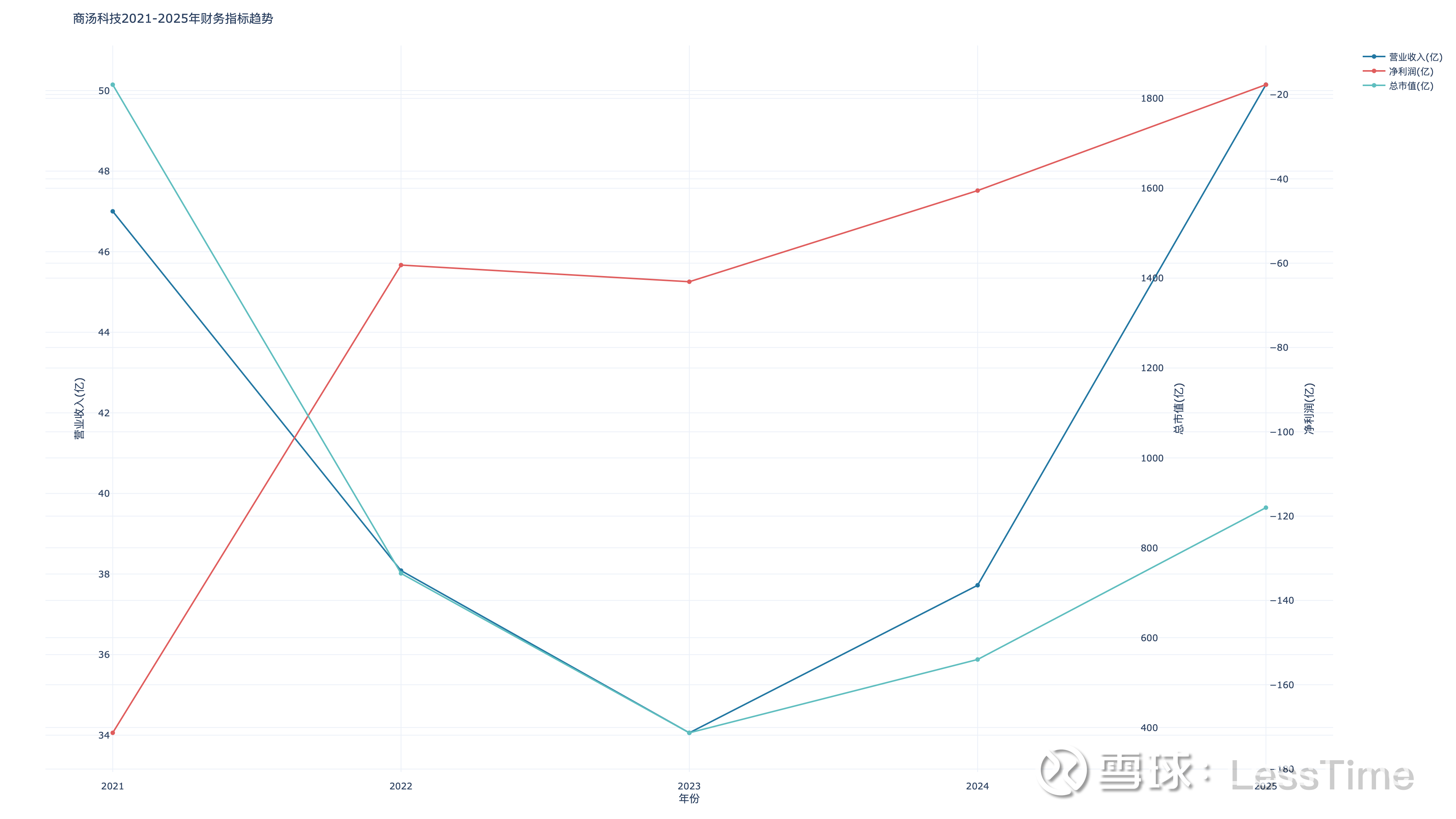
商汤(0020.HK)2025年业绩出炉,市场目光大多聚焦在收入50.1亿,增长33%;净亏损收窄58.6%;下半年EBITDA首次转正这些亮眼数字上。
这些数据确实漂亮,但如果你只看到这些,可能就错过了这份财报里真正值得长期关注的东西。
这份年报最大的看点,不是财务指标的修复,而是商汤正在完成一次从“平台型AI公司”向“算法+垂直生态”的深层蜕变。而这场蜕变的核心推手,正是徐立在穿越周期中做出的关键决策——分拆。
一、业绩不是“修复”,而是“换挡”
先看数据,商汤2025年的表现确实可以用“质变”来形容:
- 总收入50.1亿元,同比增长33%,为近三年最高增速;
- 净亏损同比收窄58.6%,EBITDA亏损收窄85%至4.7亿元;
- 2025下半年EBITDA首次转正,达3.8亿元,经营性现金流首次转正;
- 现金周转周期从228天优化至129天,回款48.7亿元创历史新高。
更关键的是,生成式AI业务收入36亿元,同比增长51%,占比提升至72%。这意味着商汤已经从一个“视觉AI公司”,真正转型为以生成式AI为核心驱动力的企业。
但比收入结构更值得玩味的是,算法效率的跃升。
二、Token对比背后的“算法护城河”
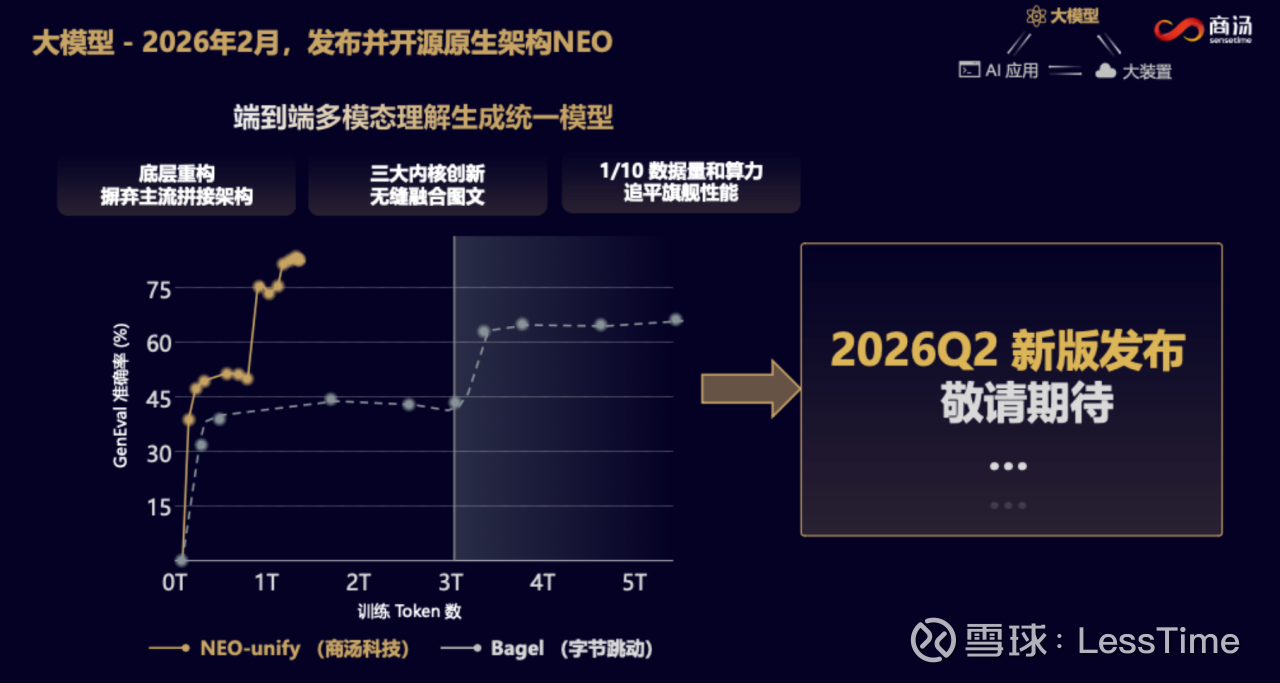
财报中提到一个容易被忽视但极其关键的信息:
“新一代原生多模态架构,仅用业界十分之一的数据与算力达成同等性能。”
如果你对AI行业有了解,就知道这意味着什么——算法效率,正在成为比算力更深的护城河。
再看两组数据:
- 日新6.5性价比提升3倍以上;
- 开悟3.0推理速度达英伟达Cosmos 2.5的7倍。
这些不是营销话术,而是实打实的“单位智能成本”压降。在算力成本高企、大模型军备竞赛进入冷静期的当下,谁能用更少的资源跑出更好的效果,谁就掌握了商业化的主动权。
商汤在算法效率上的积累,正在从“技术领先”转化为“商业优势”。这一点,远比单纯堆算力更具长期价值。
三、分拆,是徐立做的最准确的决定
如果说算法是商汤的“里子”,那分拆就是它“面子”重构的关键一步。
过去几年,AI行业一直有个尴尬的现实:喊着金汤匙出生,却是丫鬟命。技术领先,变现艰难。平台型AI公司往往陷入“什么都做,什么都难盈利”的困境。
而商汤的分拆策略——将芯片、医疗、智能驾驶等业务独立融资、独立发展——恰恰是在解决这个结构性矛盾。
这不是“瘦身”,而是“松绑”。
分拆之后:
- 各业务可以独立融资、独立决策,不再受制于集团层面的资源分配;
- 研发费用同比下降8.6%,部分创新业务“出表”,集团财务结构明显优化;
- 更重要的是,商汤系走出了像Minimax这样具备世界级极致效率能力的创始人团队,这本身就是分拆模式成功的佐证。
徐立很清楚:在AI大爆发之前,平台型公司很难同时兼顾前沿探索与商业变现。分拆,不是放弃,而是让每一颗种子都有机会在最适合的土壤里开花。
四、垂直场景,才是商汤多年积累的“再开花”
AI行业有一个长期被低估的真相:大模型是能力底座,垂直场景才是价值变现的终点。
商汤这些年积累的,不只是模型能力,更是对场景的理解深度。
- 智慧教育覆盖500多所院校;
- 如影数字人覆盖2000家电商直播间;
- 小浣熊服务数千家企业、1500万个人用户;
- 卡皮相机多国App Store登顶。
这些不是“试点”,而是已经在垂直场景中跑通的业务。分拆之后,这些场景业务将获得更大的自主权和资源支持,商业化落地有望从“点状突破”走向“规模化复制”。
而视觉AI C2.0实现盈利、海外老客户复购率提升,也说明商汤在传统优势领域依然具备造血能力。
五、穿越周期的商汤还有哪些王牌?
2025年的商汤,已经不是那个只靠“技术光环”讲故事的公司。
它有数据证明的财务改善,有算法效率支撑的技术壁垒,有分拆带来的组织活力,更有垂直场景中正在开花的结果。
如果你愿意看得更远一点,你会发现:商汤正在完成从“AI平台”到“算法+垂直生态”的深层转型。而这场转型的核心驱动力,恰恰是徐立时代最被低估的那个决定——分拆。
在AI行业从“拼参数”走向“拼效率、拼场景”的下半场,商汤的积累,可能比市场想象的要值钱得多。
商汤的"硬核资产":凭什么让人期待?
抛开情怀,我们来硬碰硬地看:商汤手里到底有什么牌?
1. SenseCore大装置:中国最稀缺的AI基础设施之一
商汤大装置目前运营总算力达到4.04万PetaFLOPS(FP16)。
这是什么概念?
- 已完成华为昇腾384超节点的全面适配
- 沙特上线中国首个出海国产算力集群
- 纳管首个华为液冷910C集群
- 中国原生AI云厂商市场份额第一
徐立在2024年说:早在2014年商汤成立之时,我们的创始人汤晓鸥教授就强调要把技术带到日常生活中。商汤历时五年,建设了业界领先的AI大装置,共有27000块GPU芯片卡,是亚洲目前最大的智能计算平台之一。
这不是普通的算力租赁,这是有软硬协同优化能力的"AI工厂。
2. 原生多模态:可能是中国AI的"弯道超车"机会
商汤NEO架构的核心突破在于:
- 底层重构:摒弃主流"编码器-连接器-LLM中枢"拼接架构
- 三大内核创新:Native Embedding、Native RoPE、Native Multi-head Attention
- 效率提升:仅需1/10的训练数据达到顶尖性能
徐立在2025年WAIC大会上说:多模态模型的发展和AGI的发展'画上了约等号。从数据量来讲,多模态是补充人类智能的核心要素。而从学习方法上来讲,多模态也是效率更高的。"
这句话背后的逻辑是:中文互联网的文本数据质量不如英文,但中文世界的图像、视频、语音数据同样丰富——多模态是中国弯道超车的好机会。
3. 视觉AI的深厚积淀:连续九年中国市场第一
商汤在CV领域的技术积累不是新故事,而是"压舱石":
- 连续九年蝉联中国计算机视觉市场份额第一
- SenseFoundry(方舟)平台全新升级为"通专融合、智训一体"的多模态算法生产体系
- 多模态算法落地的项目占比从2024年的近乎0%提升至2025年的约60%
这意味着:商汤的视觉能力正在与大模型深度融合,形成差异化竞争力。
4. "1+X"战略:聚焦主业,释放生态价值
2024年末,商汤正式发布"1+X"战略:
- 1:核心业务(生成式AI + 视觉AI)
- X:生态矩阵(智能驾驶、医疗、机器人等)
这个战略的本质是:做减法。
商汤终于意识到,在AI的汪洋大海中,不可能什么都做。必须聚焦在有技术壁垒、有商业回报的核心赛道上。
5. 国际化布局:中东、东南亚的先发优势
- 沙特上线首个国产算力集群
- 与阿联酋Miral集团合作文旅AI解决方案
- 泰国泰京银行AI金融解决方案落地
- 印尼高等教育与科技部AI伦理合作
这是一个被忽视的"隐形资产"——在国产大模型出海浪潮中,商汤已经抢占了关键卡位。
六、应对AI巨变时代,商汤能复制MiniMax的"效率奇迹"吗?
当然,挑战依然存在:
- 国产算力占比仅13.6%,大规模替代仍需时间;
- 应收账款结构仍有历史包袱;
- 海外收入占比未披露,国际化进展仍待验证。
基于商汤的硬核资产,完成周期穿越之路,商汤还需要用真实业绩回答以下五大问题:
期待一:NEO架构能否带来"代际领先"?
现状:NEO架构的Benchmark表现亮眼,但还没有大规模商业化验证。
合理期待:2026年Q2基于NEO的新版发布后,观察:
- 是否能在实际场景中实现"1/10成本"的承诺
- 推理成本是否真的能下降5-10倍
- 客户付费意愿是否有明显提升
闫俊杰说过:在AI时代,最终决定胜负的并不是单纯的烧钱和烧资源,而是智能能力进步的速度,而速度来自研发效率。
商汤需要证明:NEO不是"PPT创新",而是能落地的"效率革命"。
期待二:C端产品能否出现"海螺式"爆发?
MiniMax的海螺AI已经做到全球月活3000-4000万,视频生成量每天近1万小时。
商汤的咔皮系列:
- 咔皮相机:全球多国App Store登顶榜首
- 咔皮记账:T+1留存率70%
- 小浣熊:服务用户超1500万
合理期待:商汤的C端产品已经证明了"有爆款潜质",但还没有出现像海螺那样的指数级增长。
关键问题是:NEO架构能否优先赋能C端产品,让用户体验到"质的飞跃"?
期待三:EBITDA转正能否持续?
2025年下半年,商汤EBITDA首次转正(3.76亿元),这是一个重大里程碑。
合理期待:
- 2026年全年能否保持EBITDA正值
- 2027年能否实现non-GAAP盈利
- 收入规模需要达到多少才能盈亏平衡
根据估算,商汤的盈亏平衡收入大约在70-80亿元区间,目前还有30-50%的距离。
期待四:生态矩阵能否"开花结果"?
创新业务虽然收入占比只有6%,但孵化了多个独角兽级别的生态企业:
- 脱胎于商汤智驾的大晓机器人是目前具身智能领域炙手可热的公司;
- 商汤医疗(SenseCare)也完成了10亿融资,正在飞速独立发展;
- 商汤芯片独立成立曦望,也是一级市场的融资宠儿,估值已经超过了30亿。
合理期待:这些生态企业能否在2026-2027年陆续完成外部融资,甚至分拆上市,为商汤带来股权增值?
从2021年作为视觉AI龙头上市,穿越周期的商汤如今也可能正值最好的时代:
2024年底,MiniMax M1发布:53万美元训练成本,性能对标GPT-4。
2025年初,DeepSeek R1:560万美元训练成本,震动全球AI圈。
现在,商汤NEO发布:1/10数据量和算力,追平旗舰性能。
这三家公司的故事线,在某个奇点交汇了。
而更戏剧性的是——MiniMax创始人闫俊杰,曾是商汤的副总裁、研究院副院长。
同样的技术基因,minimax的成功不仅点燃了AI圈对于中国模型极致效率的热望,对于孕育出这样人才摇篮的商汤,也是一次重新再出发的机遇。