08/22/2025,
$云天励飞-U(SH688343)$
昨晚刷屏的应该是DeepseekV3.1发布了。
期盼已久R2没到来,来的只是V3.1,
虽然只是V3.1,可它却是专为国产算力芯片而来。
DeepSeek-V3.1发布,其核心创新是采用 “UE8M0 FP8”参数精度——一种专为国产芯片设计的超低精度浮点数格式。
尤其在文章末尾,Deepseek官方置顶留言:UE8M0 FP8是针对即将发布的下一代国产芯片设计。
DeepSeek的布局正在形成“国产模型-国产芯片-国产系统”的全国产化闭环。
------
学过一点计算机的都知道“数据类型”,
这么说吧,UE8M0 FP8就相当于Uint8,8位无符号整数。
这种数据类型是最最简单的,最节省内存,最主要是对于乘法运算,指数级节省算力。
英伟达卡 ,
CUDA®Core 支持的精度FP64, FP32, FP16, BF16FP64, FP32, FP16, BF16, INT8 * 初步规格,
fp16以上对内存消耗呈指数级增长,而这种内存卡就是所谓HBM,现在产能跟不上,比较紧缺,
H20相比国产卡,并不是计算速度快,而且它自带HBM内存比国产卡高,这是它的优势。
而DS v3.1支持FP8,适配国产卡,对内存要求大幅降低。
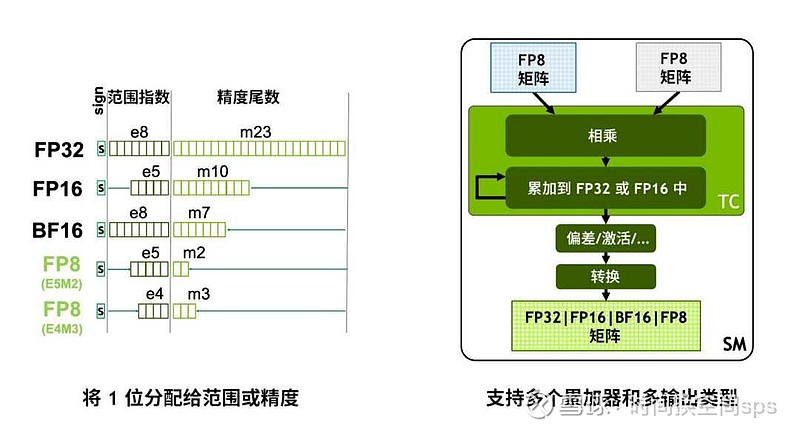
FP8 主要有两种格式,
一种是E5M2,就是1个符号位,5个指数位,2个尾数位。
一种是E4M3,就是1个符号位,4个指数位,3个尾数位。
而DS V3.1版本的FP8 是UE8M0,就是不要符号位,也不要尾数位,8个全部是整数位。
就等于无符号8位整数。这个是最简单的,最最简单的。
当然,总会遇到带小数点的浮点运算,这时候就用两个Uint8拼起来,整数,尾数分别存放。
说白了,就是软件优化。
对算力的节省主要体现在乘法和卷积运算,加法差别不大,16x16矩阵,对比8x8矩阵,复杂度是指数增加。
当然,人家GPT-5也做了优化,数据类型也做了优化,只是没到Uint8这么简单,
正因为做了这些优化,所以在图形渲染,文生视频方面提升就没那么多。
精度高一倍,对算力需求指数级增长,对内存需求也是指数级增长。
Deepseek官方置顶留言:UE8M0 FP8是针对即将发布的下一代国产芯片设计。
就是目前的FP8,主要是E5M2和E4M3这两种类型,
而DSv3.1进一步简化到UE8M0。
-----
总之,DeepseekV3.1就是为了适配国产算力卡而设计,并且从更高层次来说,节能高效也是人类的终极目标。