Token只是表象,真正稀缺的藏在更上游


最近科技圈有两件事挺有意思。
第一件是OpenClaw突然火了。你可能没太关注,但这个开源的AI智能体框架,正在国内开发者圈子里疯狂刷屏。深圳龙岗出了“龙虾十条”补贴政策,无锡高新区也跟着砸钱扶持——就为了抢一个能让AI自己动手干活的东西。
为什么?因为AI从“聊天”进化到“干活”了。
过去我们觉得AI就是个高级聊天机器人,写写文案、画画图。但OpenClaw这样的智能体,相当于给AI装上了手和脚——它能自己点鼠标、敲键盘、调用软件,帮你完成复杂任务。
这就像养了一个数字员工。
你养的“员工”越多,背后的“成本”就涨得越离谱
这里有个容易被忽略的点。
每个数字员工在帮你干活的时候,都在消耗一种叫Token的东西。你可以把它理解成AI世界的“字数”——AI每生成一句话、每做一个操作,都要消耗一定数量的Token。
摩根士丹利预测,2026年全球AI推理消耗的Token将达到68000万亿。这是什么概念?增长是指数级的。
更关键的是,Token正在变得越来越贵。阿里云的订阅最近搞限购,火山引擎新模型的定价——15秒视频消耗30万Token,成本15元——都在释放一个信号:
Token开始“通胀”了。
当几十亿个数字员工同时上线干活,Token的消耗速度会把算力成本推到一个可怕的高度。现在谁掌握Token,谁就掌握了定价权。
但Token只是表象,真正稀缺的藏在更上游
问题来了:Token是AI生成的,AI靠什么生成?靠语料数据。
就像炼油需要原油,AI的智商取决于它吃进去的数据质量。光大海外的一份研报明确指出:中文数字内容正在成为重要稀缺资源,用于国内AI大模型预训练语料库。
现在中文高质量语料有多稀缺?Common Crawl这个全球最大的公开数据集里,中文只占4.8%。更别提训练专业AI智能体需要的那种数据——学术的、专业的、高质量的。这种东西不是网上随便爬一爬就能有的,它需要几十年的积累。
今年两会,有政协委员专门提到一句话:要“围绕智能体、推理和代码等方面加强关键语料供给”。这话翻译一下就是:
高质量语料,正在成为国家级战略资源。
A股里谁能接住这波“语料重估”?
顺着这个思路,我们来梳理一下A股中可能的“语料玩家”,大致可以分成几类:
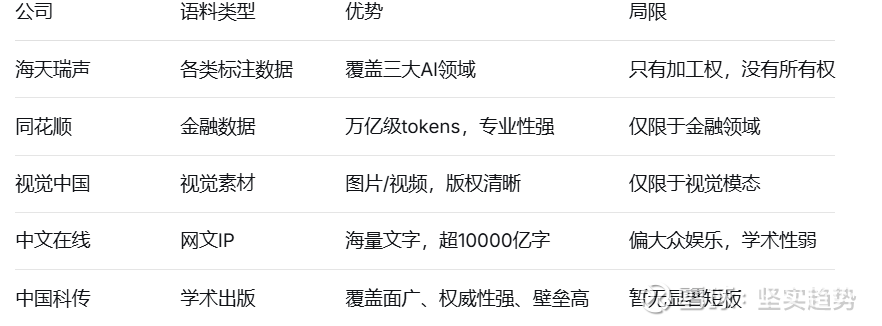
第一类是“数据加工商”,比如海天瑞声和ST汇洲。他们不生产原始数据,而是帮客户做数据标注和加工。海天瑞声的业务覆盖智能语音、计算机视觉、自然语言处理三大领域,还与中科院自动化所、智谱AI等签署了高质量中文大模型训练数据集共建项目。这类公司的价值在于“数据精炼”能力,但问题是——他们没有数据的所有权,只是“来料加工”。
第二类是“垂直领域语料持有者”,比如同花顺、视觉中国、中文在线。
同花顺拥有万亿级tokens的金融语料,涵盖股票、债券、宏观经济指标等。视觉中国手里是数以亿计的专业级图片、视频素材。中文在线则拥有海量网文IP,字数超10000亿字。
这些公司的共同点是:在各自细分领域有深厚积累,语料质量高、版权清晰。但局限也很明显——领域太垂直。金融语料只能喂金融模型,视觉素材只能喂多模态模型,网文内容偏向大众娱乐。
第三类是“综合类出版机构”,代表就是中国科传和中信出版这类国字号出版集团。
光大海外在研报中明确将中国科传列为受益标的之一。为什么?
第一,覆盖面广。作为中国科学院旗下的出版集团,中国科传手握自然科学、工程技术、医学等领域的学术内容——这些正是训练专业级AI智能体最需要的高维语料。
第二,权威性强。互联网数据泥沙俱下,学术出版的数据是经过同行评议、严格筛选的。在数据质量决定模型上限的今天,“纯度”比“数量”更重要。
第三,壁垒高。这不是谁想进就能进的领域。几十年积累的版权资源、中科院的背景背书、学术出版的准入门槛——构成了天然的护城河。
用个表格对比可能更直观:
当几十亿数字员工开始在各行各业干活,当Token变得越来越贵,当高质量中文语料成为稀缺品——真正有价值的,不是那些只做加工的“数据民工”,也不是那些偏安一隅的“垂直玩家”,而是像中国科传这样,站在多学科高质量语料入口的“资源拥有者”。
这或许是语料重估浪潮中,最值得多看几眼的方向。#$中国科传(SH601858)$ $中文在线(SZ300364)$ $视觉中国(SZ000681)$ #龙虾Open Claw#
(一家之言,不构成投资建议)