星环科技:一边是大模型订单斩获近5000万,一边是五矿资本招标案以更低报价落败——能否撑起300亿市值?

“在这个信息过载、噪音漫天、K线图让人焦虑的市场里,我想做一件‘笨’事——为您提供一个关于公司价值的‘秤砣’。作者曾在机构研究部深耕多年。我看过太多投资者,因为对公司价值心里没底,在股价的短期波动中迷失方向。A股整体估值偏高,情绪钟摆极易过头,一旦追高被套在趋势的末端,回本往往遥遥无期。
逍遥投研社的核心工作,就是回归生意的本质,剥去市场的情绪,为您测算这家公司‘到底值多少钱’。这个秤砣不一定是最精准的,但一定是理性的、冷静的、经得起推敲的。我希望这个秤砣能帮您做到两件事:
高位不贪婪:当股价远超价值时,管住手,或是敢于分批离场。
低位不恐惧:当股价跌入价值区域时,心里有底,敢于分批布局。
投资是一场长期主义者的修行,也是认知的变现。如果您厌倦了追涨杀跌,愿意静下心来,从价值出发寻找确定性,欢迎关注我的深度分析。
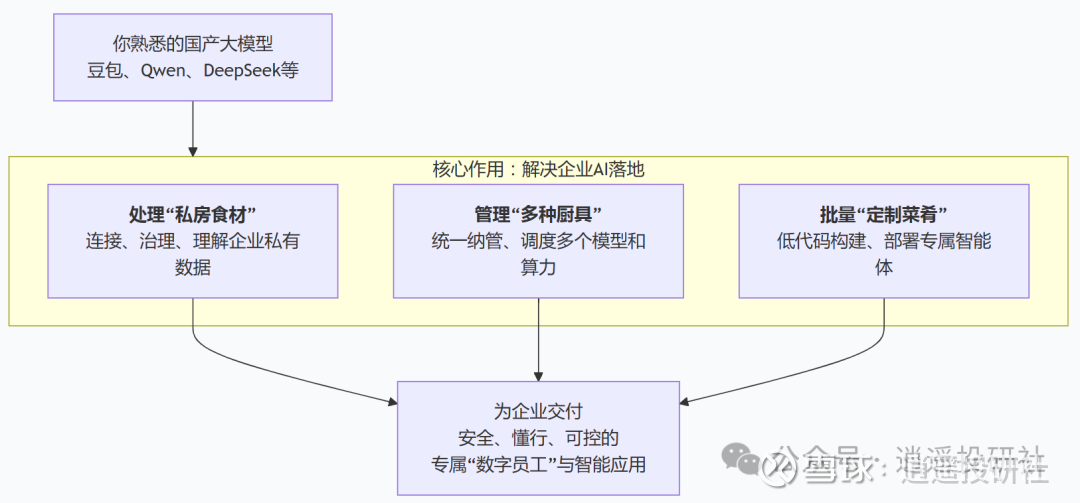
大家肯定有疑虑,目前国产大模型基本是豆包全家桶、Qwen全家桶、deepseek、minimax、智谱,星环在这么激烈竞争下的环境中如何自处。
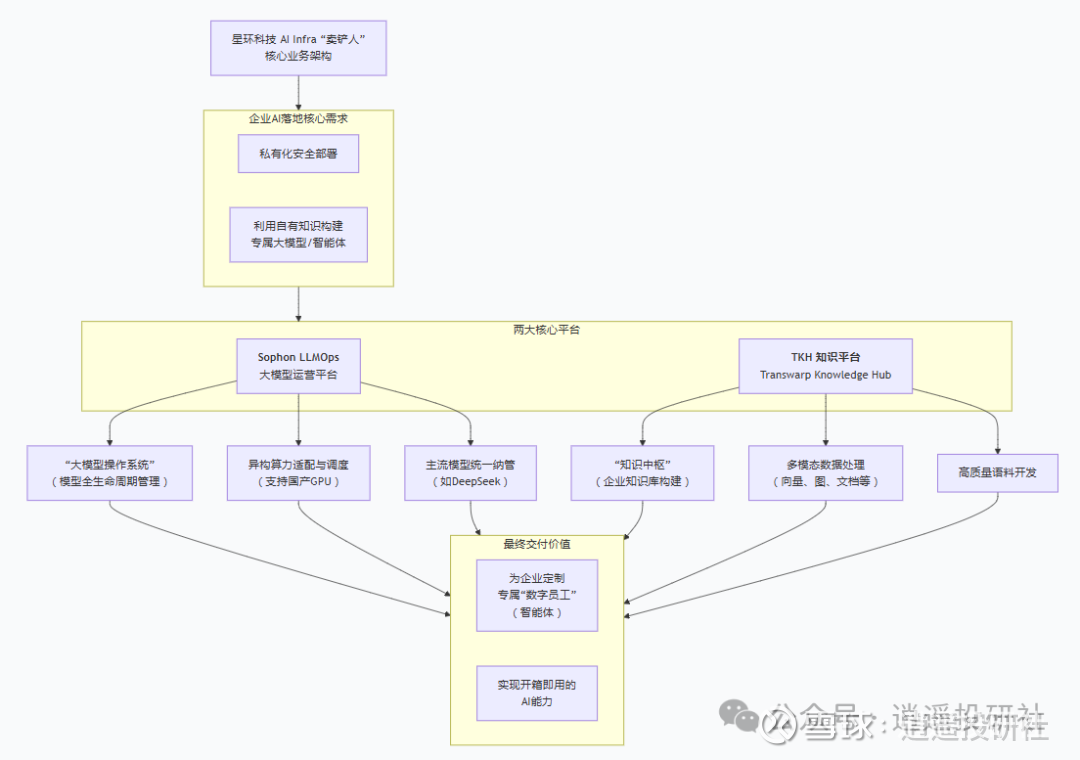
一、主业:AI时代的“中央厨房”,而非“厨师”
要理解星环科技,首先要理解一个关键区别:它不生产大模型,而是帮助企业用好大模型。
如果把豆包、Qwen、DeepSeek等国产大模型比作“高级食材”,那么星环科技的角色就是一套完整的“中央厨房”设备。这套设备的核心价值在于解决企业AI落地的三个“系统性问题”:
第一,处理企业的“私房食材”——私有数据。每个企业都有自己独有的数据:散落在ERP、CRM里的业务数据,堆积如山的PDF合同、Word文档、Excel报表。这些数据格式混乱、互不相通、质量参差不齐。星环科技的AI-Ready Data Platform,就像一个功能强大的“食材处理中心”,能把所有杂乱的数据统一收集、清洗、整理,加工成大模型能直接使用的“净菜”和“高汤”。没有这一步,再好的大模型也是“巧妇难为无米之炊”。
第二,管理企业的“多种厨具”——大模型和算力。一个大型企业不可能只用一种模型。风控部门需要严谨的模型,营销部门需要创意的模型;有的场景适合用DeepSeek,有的适合用Qwen。星环科技的Sophon LLMOps平台就像一个“智能厨房总管”,能统一纳管30多种大模型,根据不同业务需求自动分配最合适的模型和最经济的算力(包括英伟达和国产GPU),并确保业务的连续性。
第三,批量“定制菜肴”——构建专属智能体。企业最终需要的不是一个聊天机器人,而是能干活、懂业务的“数字员工”。星环科技的TKH知识平台,把第一步处理好的“私房数据”注入大模型,让这个智能体不仅会说人话,更懂企业的业务流程和行业黑话。而且这一切都可以在企业的内部私有环境中完成,核心数据完全闭环。
截至2025年6月,星环科技累计服务超过1600家终端用户,其中包括约110家《财富》中国500强企业。这些客户集中在金融、政府、能源等对数据安全要求极高的行业——正是“私有化部署”最刚需的领域。
但这里也埋下了第一个质疑的种子:如果只能服务于大型企业,这个市场的天花板是否太低?
二、转折点:AI推理带来的“GPU-Native”革命
如果说星环科技过去十年的积累是在打地基,那么AI推理时代的到来,可能是它从“地基”变成“高楼”的转折点。这个转折的核心,是一项正在发生的技术革命:GPU直连SSD(固态硬盘)带来的存储架构变革。
要理解这场变革,需要先理解AI训练和AI推理的根本不同:
AI训练:需要大数据块(10MB-1GB),少并发,总存储容量相对较低(1-10TB)。这就像一次性地运输大批货物,对吞吐量要求高。
AI推理:需要小数据块(几KB甚至更小),高并发(数千条同时请求),大存储容量(PB级)。这就像无数个人同时从仓库里取不同的小件商品,对“每秒读写操作次数”(IOPS)要求极高。
传统的存储架构是以CPU为中心的:CPU同时掌控存储IO的控制路径和数据路径,GPU只是被动接收数据的“辅助加速器”。这种架构在AI训练时代还能应付,但在AI推理时代——当需要处理海量、高并发、小I/O请求时——CPU的串行任务特点就成了瓶颈。GPU的并行能力被闲置,只能等待CPU慢慢喂数据。
于是,一场架构革命正在发生:GPU的地位正在从“配角”变成“主角”。
在新的架构中,GPU直连SSD,绕过CPU和系统内存,直接、高效地从固态硬盘读取数据。GPU成为数据访问的控制中心,CPU被“降级”为仅负责辅助性的“内务管理”。英伟达正在推动这一变革,SK海力士、闪迪等存储巨头也在联合制定“高带宽闪存”(HBF)技术规范,预计2026年发布样品,2027年正式亮相。
这对数据库意味着什么?
意味着数据库软件必须被彻底重构。传统数据库是以CPU为中心设计的,存储引擎、查询执行引擎、查询优化器都是围绕CPU的能力和局限构建的。在新的GPU直连SSD架构下:
存储引擎需要革新:传统的基于内存的缓冲池管理机制效率降低,新的缓存管理器需要直接管理GPU显存和直连SSD之间的数据流动。
查询执行引擎需要重写:扫描、连接、聚合等核心算子需要深度重写为GPU内核,并能直接从SSD流式消费数据。
查询优化器的成本模型需要剧变:传统的基于CPU周期和磁盘寻址的代价模型失效,新模型需纳入GPU计算核心占用率、HBM与SSD间的带宽等新因素。
东吴证券在研报中这样描述这场变革的深远意义:“GPU直连SSD技术将使得数据库从一个在通用操作系统上运行的、管理磁盘文件的应用程序,演变为一个直接调度和管理GPU、SSD计算和存储硬件的‘数据中心级操作系统内核’。”
星环科技在这场变革中的位置是什么?
它是中国最早布局这一领域的公司之一。IDC在2025年发布的《中国面向生成式AI的数据基础设施厂商评估》报告中,将星环科技定位为“领导者”类别。公司在向量数据库、分布式关系型数据库、AI基础设施等领域均有产品布局,2025年上半年,大模型相关商机已带动近3000万元订单。
如果GPU-Native数据库的产业趋势如期到来,星环科技有望成为“数据库新架构”时代的受益者。这正是东吴证券给予其“买入”评级的核心逻辑。
但这里需要辩证地看:产业趋势是确定的,但谁能在趋势中胜出是不确定的。这场变革同样吸引了全球巨头的目光:甲骨文、微软、华为云、阿里云都在布局。星环科技作为一家年营收不足4亿元、持续亏损的中国公司,凭什么在巨头环伺的赛道中突围?
三、业绩预测:2026-2027年,能扭亏吗?
后续内容请。。。。