【资料翻译】SemiAnalysis:CPO手册(四)

写在前面:第一,该报告所有权属于SemiAnalysis,系本人为学习而尝试翻译,若有错误在我,若侵权请及时联系我删除;第二,为何看SemiAnalysis,因为在我学习经历中,普通人可以获取的公开资料信息中,AI半导体领域我认为它专题报告的价值是首位的,其次才是香港那平台的调研纪要和野村证券的专题报告。第三,为何此时说CPO。曾记否那个简历被删除的来自WW的工程师备注里在狗子从业三年,也就是说三四年前当大家看不清未来时,某公司已经认准液冷是行业发展红利爆发的必然。我认为两三年后CPO也必然是AI红利爆发的必然所在,柯基的经历虽然受惠于大佬的眼界、信息能力、宏观判断、个股挖掘能力,但是大哥们毕竟有功成名就退隐江湖的时候,屌丝仍然需要提升自我修养才能避免命运轮回。第四,全文85页,59252字。分五篇。所发文字本人历时一周,通读五遍,用三个工具校对三遍。同时,与一般的翻译稿不同,本人的版本补充了被隐藏的收费内容,具体评述各受益公司。虽然本人接触CPO也有近十个年头,但是毕竟非此专业的行外,如有错误,欢迎网友指正。以下是正文:
————————————————————
键合,从而在光子与电子两大功能域之间,实现了超短距离、高带宽的互联。

资料来源:英伟达
Quantum-X800-Q3450交换机的ASIC芯片顶部配备有两块铜制冷板,这一设计是闭环液冷系统的组成部分,可高效为每颗交换ASIC芯片散热。与冷板相连的黑色管路负责冷却液的循环,助力维持系统的热稳定性。该冷却系统至关重要,不仅能保障ASIC芯片的热稳定性,还可对相邻的、对温度敏感的共封装光学器件起到温控保护作用。

资料来源:英伟达
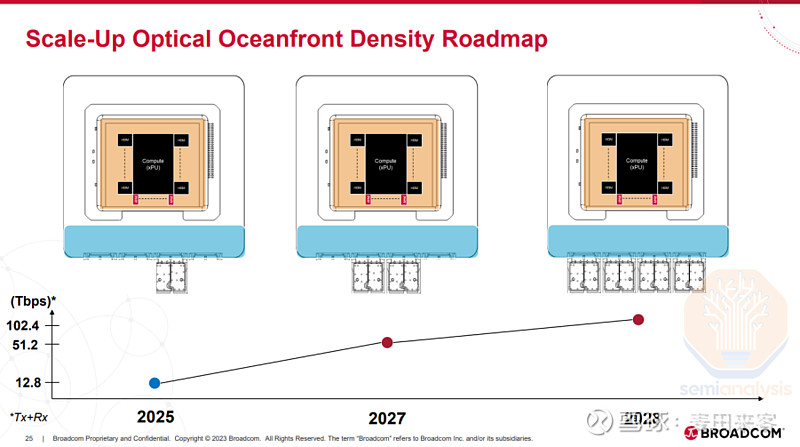
光谱-X光子学
Spectrum-X光子交换机计划于2026年下半年发布,届时将推出两款不同配置的机型:一款是基于X800-Q3450CPO交换机演进而来的以太网版本,总带宽达102.4T;另一款是Spectrum6810机型,总带宽同样为102.4T;其更高规格的同系列机型Spectrum6800,则通过集成四颗独立的Spectrum-6多芯片组件(MCM),实现了409.6T的总带宽。
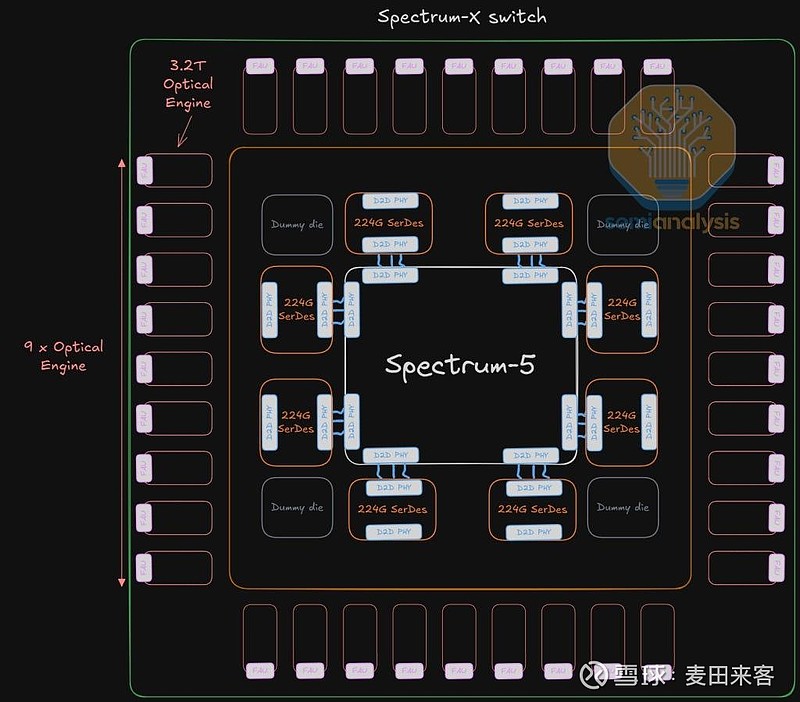
QuantumX800-Q3450共封装光学(CPO)交换机采用多平面架构设计,搭载四颗独立的交换芯片封装,且每一颗交换芯片封装均为一枚单片式裸片,内部集成了28.8T交换专用集成电路(ASIC)、所需的串并收发器(SerDes)及其他电气元件。与之不同的是,Spectrum-X光子交换机的芯片方案为多芯片组件(MCM),其核心是数枚掩膜尺寸更大的102.4T交换专用集成电路(ASIC),四周环绕着八颗224G速率的串并收发器(SerDes)输入/输出(I/O)芯粒——芯片的每一侧各部署两颗。

资料来源:英伟达
每款Spectrum-X光子多芯片组件(MCM)交换芯片封装内,均集成了36个光引擎,对应单封装102.4T的交换带宽。该封装采用英伟达第二代光引擎,单光引擎带宽达3.2T,且内置16个速率为200G的光通道。需要注意的是,这36个光引擎中仅有32个处于工作状态,额外配备的4个为冗余设计,用于应对光引擎(OE)故障的突发情况。采用这一冗余方案的原因在于,光引擎是直接焊接在基板上的,无法便捷地进行更换。
每颗输入/输出(I/O)芯粒可提供12.8T的单向总带宽,该芯粒内置64个串并收发器(SerDes)通道,且每颗芯粒分别与4个光引擎相连。正是基于这样的架构设计,Spectrum-X系列交换机得以实现远超Quantum-X光子交换机的总带宽,同时还能为串并收发器预留出更充裕的布线空间与物理面积.
资料来源:半分析
Spectrum-X6810交换机单机柜搭载1个上述交换芯片封装,可提供102.4T的总带宽。更高规格的Spectrum-X6800交换机单机柜则是一款高密度机框设备,其通过集成4个上述Spectrum-X交换芯片封装,并采用多平面架构设计与外部物理端口相连,最终实现了409.6T的总带宽。

资料来源:英伟达
与采用四颗ASIC芯片、总带宽达115.2T的QuantumX800-Q3450交换机类似,Spectrum-X6800同样通过内置的端口扩展架构,实现了每个端口与所有四颗ASIC芯片的物理互联。

资料来源:半分析
BroadcomCPO交换机产品组合
资料来源:半分析
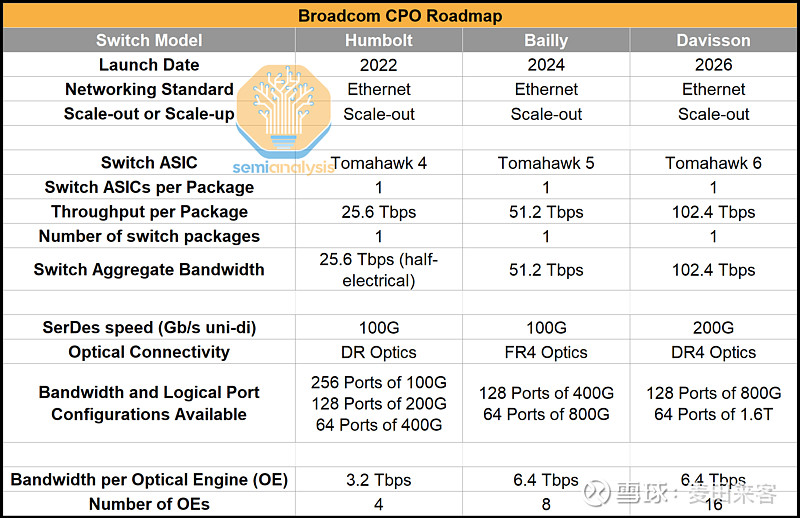
博通(Broadcom)是业内首批推出真正搭载共封装光学(CPO)技术系统的企业之一,也因此被视为该领域的领军者。博通首款CPO产品名为“洪堡(Humboldt)”,其定位以技术概念验证为主。这款名为TH4-Humboldt的交换机是一款总带宽达25.6太比特/秒的以太网交换机,将总传输能力均分给了传统电连接与CPO光连接这两种方式。其中,12.8太比特/秒的带宽由四颗3.2太比特/秒的光引擎提供,每颗光引擎可支持32条速率为100吉比特/秒的传输通道。
这种光电混合设计拥有多个典型应用场景。在其中一种场景下,架顶式(ToR)交换机通过电接口实现与邻近服务器的短距离铜缆连接,同时借助光端口向上连接至更高层级的交换设备。在另一种场景下,汇聚层交换机的电端口负责实现同一机柜内多台交换机的互联,而光链路则延伸至该层级之上或之下的其他交换层级

资料来源:博通
在该设计中,博通采用了硅锗(SiGe)工艺的电子集成电路(EIC),而在其下一代产品(即“贝利”(Bailly))中,则切换为互补金属氧化物半导体(CMOS)工艺。

资料来源:博通
博通的第二代CPO设备贝利(Bailly)是一款总带宽达51.2太比特/秒的以太网交换机。与前代仅半数接口为光接口的设计不同,该设备的输入/输出(I/O)接口全部采用光接口方案。
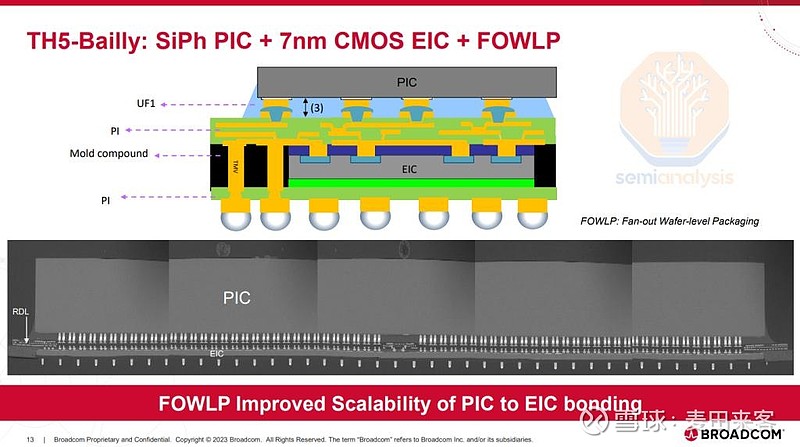
这款交换机内置8个速率为6.4太比特/秒的光引擎,每个光引擎可提供64条速率为100吉比特/秒的传输通道。另一项显著改进在于,其电子集成电路(EIC)不再沿用硅锗(SiGe)工艺,而是升级为7纳米互补金属氧化物半导体(CMOS)工艺。切换至CMOS工艺的EIC支持更复杂的集成化设计,并可集成更多控制逻辑,这一改进直接推动了传输通道数量的提升——新型光引擎的通道数从上一代的32条扩展至64条

资料来源:博通
从第一代到第二代产品的另一项显著转变,是封装工艺从硅通孔(TSV)技术升级为扇出型晶圆级封装(FOWLP)。在该设计方案中,电子集成电路(EIC)借助模塑通孔(TMV)实现与光子集成电路(PIC)的信号互联,同时通过铜柱凸点与基板相连。采用扇出型晶圆级封装(FOWLP)的一个主要原因在于,该技术已在手机市场得到充分验证,且获得了众多外包半导体封装测试厂商(OSAT)的广泛支持,具备更强的技术规模化应用潜力。而日月光/矽品(ASE/SPIL)正是这一FOWLP工艺的合作外包半导体封装测试厂商。
资料来源:博通
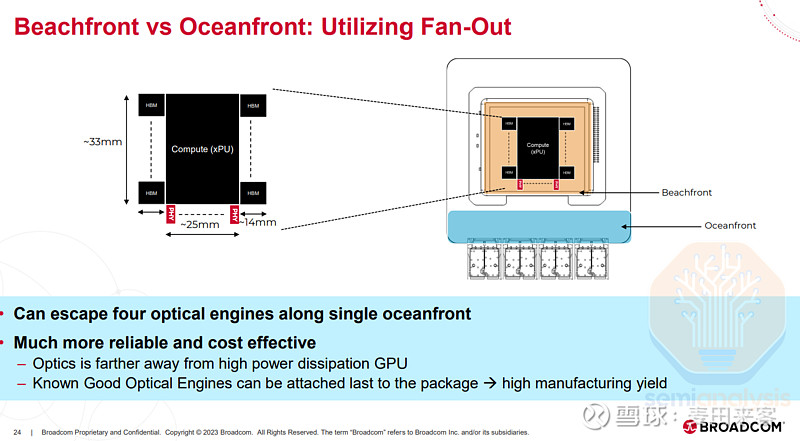
博通公司于2024年热芯片大会(HotChips2024)上公布了一项实验性设计方案,该方案将一个6.4太比特/秒的光引擎集成至一个封装件中,此封装件同时整合了1颗逻辑芯片裸片、2个高带宽内存(HBM)堆栈以及1个串并收发器(SerDes)芯粒。
博通提出采用扇出型封装方案,将高带宽内存(HBM)布置在基板的东西两侧,从而为同一封装件内集成2个光引擎预留出空间。通过将封装工艺从晶圆上芯片(CoWoS-S)升级至大尺寸晶圆上芯片(CoWoS-L),可采用边长超过100毫米的基板。基于此,该封装方案将能够容纳最多4个光引擎,实现51.2太比特/秒的带宽。
资料来源:博通
资料来源:博通
今年,博通公司将推出基于“战斧6”(Tomahawk6芯片架构的戴维森(Davisson)系列共封装光学(CPO)交换机,该系列交换机内置16个速率为6.4太比特/秒的光引擎。交换机的专用集成电路(ASIC)采用台积电(TSMC)的N3工艺节点制造,单封装带宽可达102.4太比特/秒。博通将整机装配业务交由迈卡斯(Micas)、天弘(Celestica)等合约制造商(CM)负责。此外,有消息称日本电信电话株式会社(NTTCorp)正采购博通的“战斧6”(TH6)裸片,并计划采用自研的光引擎及光学解决方案(非博通供应)打造自有CPO系统。这种模式不仅拓展了基于“战斧6”芯片的CPO系统的潜在商业机遇,更有助于推动形成一个更加开放的供应商生态体系

资料来源:半分析
鉴于共封装光学(CPO)技术在可扩展互联架构中展现出更高的应用价值,我们认为博通推出的首款量产型CPO系统,将率先搭载于其客户的人工智能专用集成电路(AIASIC)之上。博通在CPO领域积累的丰富经验,使其成为那些计划在中期产品路线图中引入CPO技术的ASIC客户眼中颇具吸引力的设计合作伙伴。据悉,这也是OpenAI最终选择与博通合作的关键因素。有趣的是,作为博通最大的ASIC客户,谷歌却是一众超大规模数据中心运营商中,对在自有数据中心内部署CPO技术最为迟疑的一家。谷歌的基础设施建设理念更侧重于可靠性优先于绝对性能,而CPO技术当前的可靠性短板,正是导致其无法被谷歌采纳的决定性因素。因此,我们预计谷歌在短期内不会部署CPO技术。
博通下一代CPO终端产品也将转向采用台积电的COUPE封装平台——这一举措是明确的信号,表明COUPE平台所具备的技术特性,能够为带宽的持续拓展提供可行路径。这一转型带来的变化不仅局限于光引擎(OE)的封装方式:博通此前几代产品均采用了边缘耦合技术与马赫-曾德尔调制器(MZM),尽管这两种技术方案从实现角度来看更为简便,但正如前文所述,它们的可扩展性相对有限。而COUPE平台更适配光栅耦合技术与微环调制器(MRM),这与博通现有的技术路线形成了显著差异。尽管博通在CPO领域拥有最为深厚的技术积淀,但此次技术路线的切换,意味着其必须在部分技术环节上近乎从零开始探索。目前的核心问题在于,台积电能够为博通提供多大程度的技术支持,从而降低其相关产品的设计难度。
英特尔的CPO路线图

来源:英特尔
英特尔在今年的英特尔FoundryDirectConnect中公布了其CPO路线图,并概述了4个阶段的发展路线图
2023年:英特尔于2023年提出了一项面向先进封装间电输入输出(I/O)互联的技术概念,以此作为光集成技术的前置探索方向。这一里程碑成果的核心目标,是实现芯片封装之间的直接高带宽短距电链路互联(摒弃传统的印刷电路板(PCB)走线方式),从而为多芯片系统提供技术支撑。该技术通过搭建一套封装级输入输出(I/O)基础架构,为后续集成光子技术、拓展光通道预留了空间,奠定了坚实的技术基础。
2024年:英特尔展示了其首款采用光纤直连方案的第一代CPO解决方案。该方案中,光引擎芯粒无需任何外置连接器,直接与光纤耦合,简化了链路设计。在2024年光纤通信大会(OFC2024)上,英特尔展出了一款4太比特/秒(双向)的光计算互联(OCI)芯粒——该芯粒与一款概念性至强(Xeon)中央处理器(CPU)共封装,可通过单模光纤链路实现无差错数据传输,提供64条传输通道,每条通道速率达32吉比特/秒。其光接口能效表现优异,功耗约为5皮焦/比特。
2025年:英特尔第二代CPO解决方案摒弃了固定式光纤尾纤,转而采用可插拔光封装连接器。英特尔工程师研发出一种玻璃光桥,该光桥可插接在封装侧面,内部集成了嵌入式3D波导与机械对准结构,能够实现封装内光子器件与标准光纤连接器的对接。这种光封装连接器设计支持模块化组装,标志着技术路线向更易于插拔、可维护的形态转型。
2027年:英特尔的目标是在三维集成光子技术领域实现突破:通过垂直扩展光束耦合技术,对光子元件进行垂直堆叠。在这款构想中的第三代设计方案里,光输入输出(I/O)信号可通过短距离自由空间光路或玻璃内光路,在芯片裸片各层之间(例如光子中介层与逻辑裸片之间)实现垂直传输。英特尔希望借助这种封装内垂直光耦合方式,进一步突破电互联瓶颈,并在21世纪20年代后半期实现超高带宽的芯粒互联架构。
联发科CPO计划
作为一家定制化专用集成电路(ASIC)设计厂商,联发科正致力于将共封装光学(CPO)技术能力整合至其设计平台之中。该公司计划推出可与其定制化加速器无缝协同工作的光子集成电路(PIC)与电子集成电路(EIC)设计方案。
联发科认为,在单通道速率200G这一代际下,若光纤间距大于900微米,近封装铜互联(NPC)技术会是一种具备实用性的解决方案;当数据速率提升至200-300G区间时,光纤间距更高密度(大于400微米)的紧凑型近封装互联(CPC)技术或将成为更优选择。然而,一旦单通道速率达到400G及以上,就很可能需要向CPO架构演进——该架构可实现约130微米的超高密度光纤间距,并配备更小型化的互联知识产权(IP)核。
专注于CPO的公司
当Nvidia、Broadcom和Marvell在自己的道路上前进,创建自己的专有解决方案时,几家专注于CPO的公司正在探索另一套方法。这些公司面临的问题是,他们将如何与主要的开关芯片和GPU/ASIC提供商竞争——特别是因为这些现有公司中的大多数已经宣布或展示了专有解决方案。超威半导体(AMD)仍是个例外:该公司虽已知正在内部研发光子互联知识产权(IP)核,但尚未对外展示任何相关产品。
对于AyarLabs、Lightmatter、CelestialAI、Nubis和Ranovus等OEchiplet提供商来说,面临的挑战是超越成熟的参与者,并提供足够引人注目的解决方案以进行集成。阿亚尔实验室(AyarLabs)、天神人工智能公司(CelestialAI)与拉诺沃斯公司(Ranovus)均提供端到端整体解决方案,这意味着客户必须全盘采用其成套的端到端方案。相比之下,努比斯公司(Nubis)则聚焦于更为开放、基于标准协议的解决方案,旨在简化技术落地流程,降低客户的部署难度。与此同时,部分企业的产品路线图中还纳入了一些更为前沿的技术方案——其中典型代表包括莱特马特公司(Lightmatter)的光子中介层,以及天神人工智能公司(CelestialAI)的光子桥接技术。这类方案要想充分释放潜能,需要从根本上重新设计芯片封装结构与主芯片架构。但这类技术路线也伴随着成本攀升与诸多不确定性,尤其是在与基于互补金属氧化物半导体(CMOS)工艺的芯片实现无缝集成,以及实现大规模量产这两个方面,仍存在较大挑战。
让我们开始参观这些公司的架构,并了解市场计划。
阿亚尔实验室
阿亚尔实验室(AyarLabs)的核心产品为其TeraPHY光引擎芯粒,该芯粒可集成封装至高性能处理器(XPU)、交换专用集成电路(ASIC)或存储芯片之中。第一代TeraPHY光引擎芯粒的单向带宽可达2太比特/秒,功耗仅为10瓦;第二代TeraPHY光引擎芯粒的单向带宽提升至4太比特/秒,同时也是全球首款遵循UCIe标准的光学重定时器芯粒,可在芯粒内部完成电/光信号转换,从而将主芯片信号以光信号形式进行后续传输。UCIe接口标准的选用,应能大幅提升该产品对客户的吸引力——因其具备标准化的接口,可便捷地集成至客户的主芯片之中。

资料来源:Ayar实验室
阿亚尔实验室(AyarLabs)的前两代TeraPHY光引擎芯粒均采用格芯(GlobalFoundries)的45纳米工艺制程,以单片集成方案打造,实现了电子元件与硅光子器件的一体化集成;而第三代TeraPHY光引擎芯粒则转而采用台积电(TSMC)的COUPE封装平台。这种将环形调制器、波导以及控制电路高度集成的设计,有助于降低电信号损耗。
不过,前两代产品所采用的成熟单片工艺节点,对电子集成电路(EIC)的性能形成了制约,这也是早期几代TeraPHY光引擎芯粒只能采用低调制速率的原因所在。

资料来源:Ayar实验室
这款代号为“鹰”(Eagle)、单向带宽达4太比特/秒的第二代TeraPHY光引擎芯粒,集成了8个速率为512吉比特/秒的输入输出(I/O)端口。每个端口均采用32吉比特/秒不归零编码(NRZ)×16波长的架构,并由微环调制器(MRM)完成信号调制。其外置激光源名为“超新星”(SuperNova),由瑞典西弗斯公司(Sivers)供应。该激光器借助密集波分复用(DWDM)技术,将16种波长(即“光色”)的光束整合至单根光纤中进行传输。每个端口各采用一对单模光纤分别负责信号发送(Tx)与接收(Rx),这意味着单颗4太比特/秒规格的芯粒共计需连接24根光纤——其中16根用于信号收发,8根用于接入激光源。阿亚尔实验室在该产品的封装工艺中采用了边缘耦合(EC)技术,同时该技术方案也具备支持光栅耦合(GC)技术的能力。该公司指出,若要提升单芯粒带宽,随着连接器技术的发展,光纤密度(当前单芯粒为24根)未来数年内有望实现实质性翻倍。此外,通过提升单波长数据速率,单端口/单光纤的带宽同样可实现翻倍,这将使其在近期产品路线图中达成整体4倍的带宽扩容。这款“超新星”(SuperNova)激光器符合多源协议(MSA)标准,能够与其他粗波分复用(CW-WDM)标准光器件实现兼容互通。

来源:Ayar实验室
阿亚尔实验室(AyarLabs)的第三代TeraPHY光引擎芯粒转而采用台积电(TSMC)的COUPE封装平台,单光引擎的单向带宽可达13.5太比特/秒,是第二代产品的三倍以上。在下文提及的阿亚尔实验室与颀邦科技(Alchip)合作的XPU解决方案中,8个该款光引擎集成后,可实现约108太比特/秒的封装级总扩展带宽。
这一超13.5太比特/秒的带宽,是通过四电平脉冲幅度调制(PAM4)技术,将单波长带宽提升至约200吉比特/秒实现的。
尽管阿亚尔实验室尚未披露具体的端口架构细节(例如密集波分复用的波长数量、每个光纤接入单元对应的光纤根数等),但其采用的双向光链路设计意味着,该产品用于信号收发的光纤最多仅需约64根,连接外置激光源的光纤也至多再增加数十根。不过,阿亚尔实验室的技术战略始终聚焦于波分复用(WDM)技术,这意味着每个光纤接入单元的光纤总用量最低可至32根。与前两代产品一致,第三代TeraPHY光引擎芯粒继续采用微环调制器,既能够保持光引擎芯粒的紧凑尺寸,又可依托粗波分复用(CWDM)或密集波分复用(DWDM)技术,为未来的带宽扩展提供技术路径。

资料来源:AyarLabs、Alchip
阿亚尔实验室(AyarLabs)还与颀邦科技(Alchip)及金仁宝电子(GUC)达成合作,推动其光引擎芯粒集成至颀邦科技与金仁宝电子的高性能处理器(XPU)解决方案中。上文所举案例为一款搭载两枚掩膜版尺寸计算芯片裸片与8颗TeraPHY光引擎芯粒的高性能处理器,该方案的单向带宽最高可达108太比特/秒。
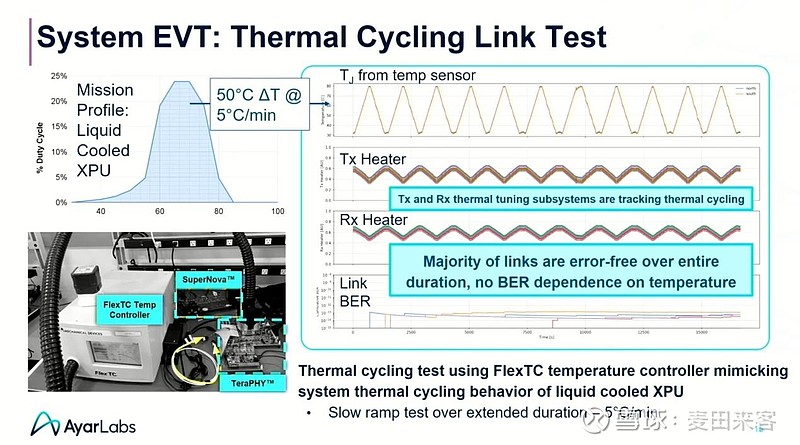
在2025年热芯片大会(HotChips2025)上,阿亚尔实验室公布了一项低速温度循环链路测试的结果——测试以约5摄氏度/分钟的速率进行了超4小时的温度循环,全程链路的误码率(BER)表现均十分稳定。
资料来源:Ayar实验室
不过,研究微环调制器(MRM)应对快速温度变化的抗干扰能力,重要性不亚于验证链路在宽温度区间内的长期稳定性。在同一场热芯片大会(HotChips)的演讲中,阿亚尔实验室(AyarLabs)阐释了他们的测试方案:由于封装内暂未搭载可实现0–500瓦功率阶跃变化的专用集成电路(ASIC),因此团队选择通过扫描激光波长的方式,来模拟快速升/降温过程。
控制电路会实时检测微环谐振腔是否发生谐振漂移——这种漂移既可能由入射激光的波长变化引发,也可能源于微环自身的温度波动。为此,研究人员会以与等效温度变化速率相对应的频率扫描激光波长。例如,20纳米/秒的波长扫描速率,可模拟出在0.2秒内温度变化64摄氏度的工况,换算后等效温度变化速率高达320摄氏度/秒。该研究结果显示,即便等效温度变化速率提升至800摄氏度/秒,系统传输过程中也未出现任何误码。
AyarLabs拥有广泛的战略支持者,包括GlobalFoundries、英特尔投资、英伟达、AMD、台积电、洛克希德·马丁、应用材料和唐宁。
努比斯
Nubis最近于2025年10月被Ciena收购。与阿亚尔实验室(AyarLabs)类似,努比斯公司(Nubis)同样提供可与客户主芯片集成的光引擎芯粒,但其技术路线更侧重于单波长连接方案。努比斯公司将研发重心放在了兼容性层面——既包括协议兼容性,也涵盖机械结构兼容性(即支持可插拔设计),这一核心需求也决定了其技术方案的选型方向。此外,努比斯还肩负着一个更宏大的使命,即攻克输入输出(I/O)性能瓶颈这一行业共性难题,因此其解决方案的覆盖范围也同时包含了光学互联与铜缆互联两大技术路径。
该公司现有的光引擎产品为Vesta1001.6TNPX光引擎。这是一款支持插槽式安装的模块,可提供1.6太比特/秒的双向带宽,包含16条速率为100吉比特/秒的传输通道,模块尺寸仅为6×7毫米。与其他厂商不同,努比斯(Nubis)在产品中大量采用马赫-曾德尔调制器(MZM),主要原因在于这类调制器具备优异的兼容性、可靠性与技术成熟度。另一项核心设计决策是,该产品被设计为兼容符合IEEE/OIF标准的电接口,因为努比斯认为,绝大多数专用集成电路(ASIC)开发者会持续沿用这类技术。
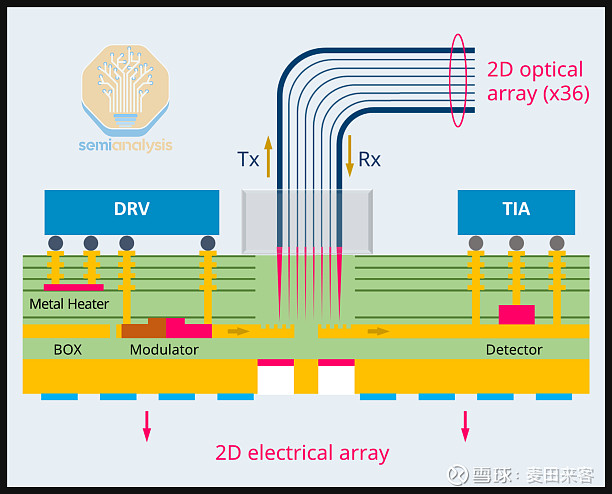
努比斯的核心差异化优势体现在光纤耦合方式上。该公司采用的是光子集成电路(PIC)表面耦合方案,具体而言,是通过一片薄玻璃片辅助光纤的路由与对准。传统边缘耦合技术是将光纤连接在芯片的侧面,而努比斯独创的二维光纤阵列方案,则是从硅光子芯片裸片的顶部实现光纤连接。
结合下方示意图来看:位于底部的绿色部分是光子集成电路(PIC),其内部集成了调制器、光电探测器与波导,上方则搭载了电子集成电路(EIC)。红色柱状结构为光纤,而容纳这些光纤的部件是一个玻璃块(即光纤接入单元FAU),该玻璃块同时起到光纤固定座的作用。光纤接入单元(FAU)的顶部设有激光钻孔,以此确保光纤的精准定位。通过采用二维光纤阵列技术,努比斯可在单块光子集成电路(PIC)上连接36根光纤(其中16根用于信号发送、16根用于信号接收、4根用于接入激光源),无需借助波分复用(WDM)技术,就能以更少的光纤实现更多波长的传输。这也使得努比斯的光纤接入单元(FAU)成为目前已量产的集成密度最高的同类产品之一。
资料来源:努比斯
尽管二维光纤阵列已被台积电等企业列入产品路线图,同时也是垂直耦合技术的一大核心优势,但目前仅有努比斯实现了该技术的量产落地,这一点构成了其差异化竞争力——不过其他厂商也计划在后续跟进布局二维光纤阵列技术。
光纤需要向上延伸并向侧面弯折,这一过程依靠的是由住友电工研发的一款特种光纤,该光纤被命名为柔性光束导向光纤(FlexBeamGuidE)。这款光纤即使在90度弯折状态下,仍能保持高可靠性与低传输损耗的性能表现。
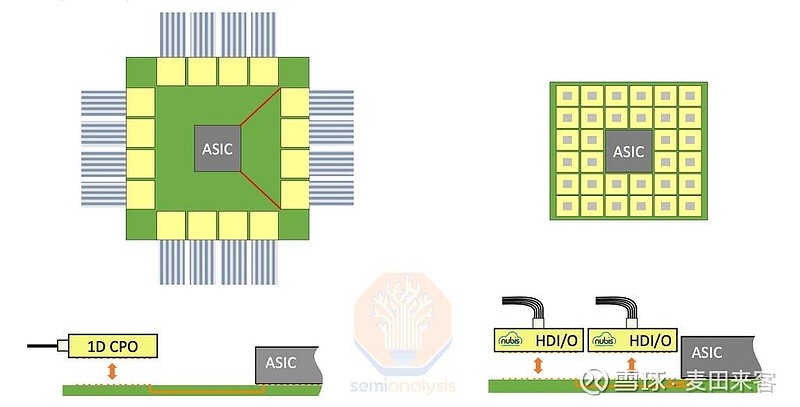
相较于边缘耦合技术,采用二维光纤阵列的另一大优势在于,可连接的光纤数量在物理层面所受的限制更小。从下方示意图中可以看出,借助努比斯的二维光纤阵列结构,只要封装条件允许,就能在专用集成电路(ASIC)的周围布置多排光引擎,从而提升带宽密度。
资料来源:努比斯
2025年4月,努比斯公司(Nubis)宣布推出其下一代光子集成电路(PIC)。这款硅光子芯片采用16通道、单通道200吉比特/秒的设计规格,单向前沿带宽密度可达0.5太比特/秒・毫米(与电信号主接口的带宽密度持平)。此外,努比斯还宣布与萨姆泰克公司(Samtec)达成合作,计划推出一款32通道、单通道200吉比特/秒(总带宽6.4太比特/秒)的即插式光模块,该模块可与萨姆泰克的Si-FlyHD共封装铜缆连接器兼容匹配。相较于其他共封装光学(CPO)技术方案,该方案可实现铜缆与光模块的物理尺寸通用化;假以时日,这一特性有望构建出一套面向共封装光学部署的开放式可插拔生态体系。
在铜缆互联领域,努比斯同样有所布局——其在光纤通信大会(OFC)上发布并展示了一款名为Nitro的线性重驱动芯片,该芯片适用于有源铜缆(ACC),可将200吉比特/秒速率的铜缆传输距离延长至数米。此项产品落地是与安费诺公司(Amphenol)合作推进的,后者将基于该Nitro线性重驱动芯片打造有源铜缆产品。
天神人工智能公司
天神人工智能公司(CelestialAI)是一家专注于为人工智能可扩展网络提供光互联解决方案的知识产权、产品及系统供应商。该公司技术的核心目标,是将光子器件(调制器、光电探测器、波导等)集成至中介层中,并配套设计与外部互联的接口(即搭载光纤接入单元的光栅耦合接口)。下方示意图清晰展示了天神人工智能公司这套基于光子技术的互联解决方案体系,该公司将其命名为“光子互联架构™”(PhotonicFabric™,简称PF)。
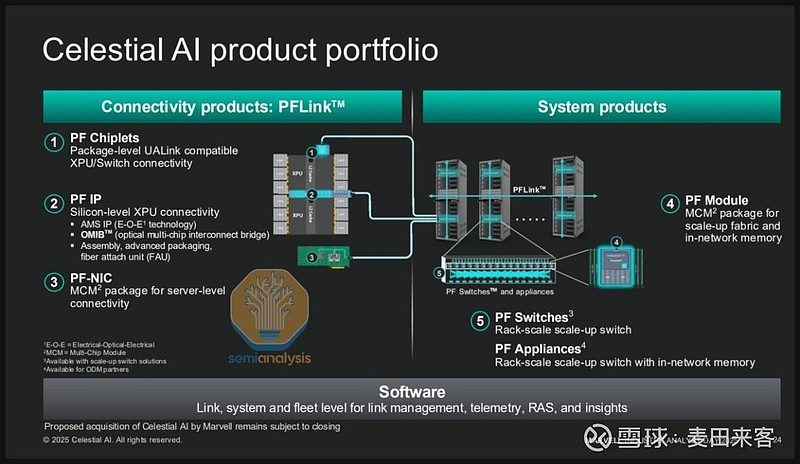
来源:天神AI

来源:天体AI
光子互联架构™(PF)芯粒采用台积电5纳米工艺制程打造,集成了通用芯粒互联接口(UCIe)、MAX物理层接口(MAXPHY)等芯片间互联接口,可实现高性能处理器(XPU)间、高性能处理器与交换机、高性能处理器与存储设备的互联。客户可将此类芯粒与自有高性能处理器进行共封装,相较基于电串并收发器(SerDes)接口的共封装光学(CPO)产品,能实现更高的带宽密度与更低的功耗。天神人工智能公司(CelestialAI)基于客户定制模式研发这类芯粒,以适配不同客户的芯片间(D2D)互联接口与协议需求。第一代光子互联架构芯粒支持16太比特/秒的带宽,第二代产品带宽将提升至64太比特/秒。
与传统铜缆走线方案相比,光芯粒具备显著的功耗优势。传输速率达224吉比特/秒、搭载线性串并收发器的传统铜缆,单端功耗约为5皮焦/比特;考虑到链路两端均需部署器件,总功耗约为10皮焦/比特。而天神人工智能公司的解决方案,在完整的电-光-电链路中,整体功耗仅需约2.5皮焦/比特(外置激光器功耗另计,约为0.7皮焦/比特)。
其次,光子互联架构™光多芯片互联桥接器™(OMIB™)本质上是一种类晶圆上芯片-大尺寸基板(CoWoS-L)或嵌入式多芯片互联桥(EMIB)的封装解决方案。该技术将光子器件直接集成至中介层的嵌入式桥接结构上,使桥接器能够直接将数据传输至终端负载。由于不受沿边带宽密度限制,其芯片整体带宽表现优于光子互联架构芯粒。
在采用金属互联方案的传统中介层或基板中,将输入输出接口(I/O)布置于芯片中心是不具备可行性的——高密度的信号汇集会引发极高的布线复杂度与严重的串扰问题。但依托光多芯片互联桥接器(OMIB)光中介层技术,天神人工智能公司(CelestialAI)可将该光中介层直接置于专用集成电路(ASIC)下方,从而突破沿边接口的物理限制,实现更高速、高效的数据传输,同时将串扰控制在极低水平。