十年垂直软件创业老兵,我对软件股大抛售的5点判断

2026年1月30日,AI巨头Anthropic为Claude Cowork推出了11个开源插件,涵盖销售、财务、法律、数据、市场营销等多个领域。
通过接入这些插件,Claude即可化身销售专家、财务专家、法律顾问或数据分析师。过去需要一整套软件与流程才能完成的工作,如今可以直接打包交给AI处理。
华尔街随即高呼「SaaS末日」来临,软件股遭遇大规模抛售。
针对这一现象,垂直软件创业者Nicolas Bustamant于2月17日发表了一篇题为《十年构建垂直软件:我对抛售的看法》的文章,迅速引发广泛讨论。
这篇文章讨论了五个主题,无论你是软件从业者、投资者,抑或是使用者,本文都值得一看。
以下为正文。
过去几周,软件与服务类股票市值蒸发了近1万亿美元。FactSet(慧甚|美国金融数据与软件提供商)从200亿美元的峰值跌破80亿美元。S&P Global(标普全球|全球金融市场信息供应商)在几周内缩水了30%。Thomson Reuters(汤森路透|全球专业信息服务提供商)在近一年几乎腰斩。涵盖140家公司的标普500软件与服务指数,年初至今下跌了20%。
上周,Anthropic发布了针对 Claude's Cowork 的行业专用插件。Cowork是一款专为知识工作者设计的AI agent,能够自主处理复杂的研究、分析和文档工作流。
华尔街称此为恐慌。过去十年,我一直在做垂直软件。先是创立了Doctrine,现在是欧洲最大的法律信息平台,然后创立了Fintool,一个在美国与彭博、FactSet和标普全球竞争的、由AI驱动的股票研究平台。
我曾打造过大语言模型(LLM)如今正在威胁的那类软件。我现在又在打造发起这种威胁的那类软件。我亲身经历过这场颠覆的两边。
我的看法是:LLM正在系统性地瓦解曾经让垂直软件固若金汤的护城河,但并非全部。结果是,我们需要重新定义什么能让垂直软件具备价值,以及它应得的估值倍数。
本文内容:
垂直软件的十大护城河,以及LLM对每条护城河的影响
为何市场抛售在结构上是合理的,但在时间上被夸大了
真正的威胁究竟是什么(并非你想的那样)
什么将取代垂直软件
垂直软件行业未来何去何从
一、垂直软件的十大护城河
垂直软件是为特定行业构建的软件。例如,金融业的彭博,法律界的LexisNexis,医疗保健领域的Epic,建筑行业的Procore,生命科学领域的Veeva等。
这些公司都有一个共同特征:收费高昂,且客户极少流失。FactSet每个用户年费超过1.5万美元。彭博终端每个席位收费2.5万美元。LexisNexis每月向律所收取数千美元费用。客户留存率普遍在95%左右。
我认为存在十条不同的护城河。LLM正在攻击其中一些,同时保留另一些。理解哪些被攻击、哪些不会,是这场游戏的关键。

1. 习得性界面 → 被摧毁
彭博终端的用户花了数年时间学习键盘快捷键、功能代码和导航模式。GP、FLDS、GIP、FA、BQ——这些并非直观易用,而是一门语言。一旦你熟练掌握,切换到另一个平台就意味着你要重新变回"文盲"。
我听过无数次这样的说法:"我们是一家FactSet商店"、"我们是Lexis律所"、"我们是彭博社"。这些说法并非关乎数据质量或功能集,而是关于软件肌肉记忆的陈述。人们花了十年时间学习使用某个工具,这种投资是无法迁移的。
这是最被低估的护城河。知识工作者愿意付费,就是为了不必重新学习他们已经花了十年时间精通的工作流。界面本身就是价值主张的重要组成部分。
我在Doctrine亲身体验过这一点。我们有一支设计师团队和一小队客户成功经理(CSM),他们的全部工作就是引导律师熟悉我们的界面。每一次UI改动都是一个项目:用户研究、设计冲刺、谨慎发布、手把手指导。我们可能会花数周时间重新设计一个分面搜索筛选器,因为律师们已经对旧版本形成了肌肉记忆。界面不仅仅是一个功能,它就是产品本身。维护它也是我们最大的成本中心之一。
而在Fintool,我们完全没有新手引导,没有客户成功经理教人们如何使用产品。用户只需用简单直白的英语输入自己想要什么,就能得到答案。没有需要学习的界面,因为一切都是对话。整个成本中心——设计师、CSM、UI变更管理——都不复存在了。聊天界面吸收了所有这些支撑结构。
LLM将所有专属界面整合到一个Chat。
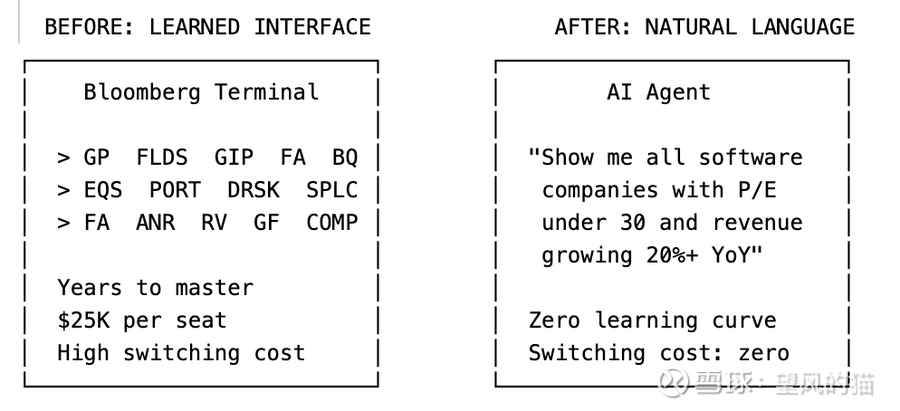
想想今天一个金融分析师在彭博终端上做什么。他们导航到股票筛选功能,使用专门语法设置参数,导出结果,切换到DCF模型构建器,输入假设条件,运行敏感性分析,导出到Excel,制作演示文稿。
每一步都需要学习界面知识,每一步都在强化转换成本。
现在再想想,同样的分析师用LLM agent做这件事:
“找出所有市值超过10亿美元、市盈率低于30、年营收增长超过20%的软件公司。为前五名构建DCF模型。对折现率和终值增长率进行敏感性分析。"
三句话。没有快捷键,没有功能代码,没有导航。用户甚至不知道LLM查询了哪个数据提供商,他们也不在乎。
当界面变成自然语言对话时,多年的肌肉记忆变得一文不值。每年每席位2.5万美元的转换成本消融了。
对许多垂直软件公司来说,界面构成了大部分价值。底层数据是授权的、公开的或半商品化的。高定价的合理性是建立在数据之上的工作流。这个时代结束了。
2. 定制化工作流和业务逻辑 → 被蒸发
垂直软件将行业的实际运作方式编码进软件。一个法律研究平台不仅仅存储判例法,它编码了引文网络、Shepardize信号、判例摘要分类体系,以及诉讼律师撰写案情摘要的特定方式。
这种业务逻辑花了多年时间才建立起来,它反映了与领域专家成千上万次的对话。
当我创建Doctrine时,最困难的部分不是技术,而是理解律师的实际工作方式:他们如何研究判例法,如何起草文书,如何从立案到庭审构建诉讼策略。将这种理解编码成可工作的软件,是垂直软件有价值,也是其防御能力的来源。
LLM将所有这一切变成了一份Markdown文件。
这是最未被充分认识到的转变,我认为也是长期来看最具破坏性的。
传统的垂直软件将业务逻辑编码在代码中。成千上万个if/then分支、校验规则、合规检查、审批工作流。由工程师们经过多年硬编码而成,而且不是随便什么工程师都行。你需要真正理解该领域的软件工程师,这种人凤毛麟角。找到一个既能编写生产级代码,又懂得诉讼工作流如何运作,或者DCF模型应如何构建的人,是极其困难的。每次修改业务逻辑都需要开发周期、QA和部署。
让我从我自己的经历中举一个具体的例子。
在Doctrine,我们构建了一个法律研究工作流,用来帮助律师针对特定法律问题查找相关判例。系统需要区分法律领域(民事vs刑事vs行政),将问题解析为可搜索的概念,跨多个法院数据库查询,按相关性和权威性排序,并附上规范的引用上下文。构建这个系统花费了一个由工程师和法律专家组成的团队数年时间。业务逻辑分布在数千行Python代码、自定义排序算法和手动调优的相关性模型中。每一次修改都需要工程冲刺、代码审查、测试和部署。
在Fintool,我们有一个DCF估值技能。它告诉LLM agent如何进行贴现现金流分析:需要收集哪些数据,如何按行业计算WACC,需要验证哪些假设,如何运行敏感性分析,何时加回股权激励。这是一个Markdown文件。写这个文件花了一周时间,更新它只需几分钟。一个做过500次DCF估值的投资经理,可以在不写一行代码的情况下,将他们整个方法论编码进去。

数年的工程VS一周的写作。这就是转变。
而且不仅仅是速度问题。Markdown技能在很多重要方面都更胜一筹。任何人都能读懂,可审计,可为每个用户定制,并且随着底层模型的改进,它能自动变得更好,而我们无需碰一行代码。
业务逻辑正从由专业工程师编写的代码,迁移到任何拥有领域专业知识的人都能编写的Markdown文件。垂直软件公司花十年积累的业务逻辑,现在可以在几周内复制出来。工作流护城河正在迅速消融。
3. 公共数据访问 → 被商品化
垂直软件价值的很大一部分在于,让难以获取的数据变得易于查询。FactSet让SEC文件可搜索,LexisNexis让判例法可搜索。这些都是实打实的服务。SEC文件在技术上是公开的,但你可以试试阅读原始HTML格式的200页10-K报表。不同公司间的结构不一致,会计术语晦涩难懂。要提取你真正需要的数据,必须解析嵌套的表格、追踪脚注引用、核对调整后的数据。
在LLM出现之前,访问这些公共数据需要专门的软件和大量的工程架构支持。像FactSet这样的公司构建了成千上万个解析器,每种文件类型一个,应对每家公司特有的格式。随着格式变化,成群的工程师维护着这些解析器。将原始SEC文件转化为可查询数据的代码,曾经是一个真正的竞争优势。
在 Doctrine,这同样是极其繁重的工作。我们为不同判例法搭建了NLP 流水线:用命名实体识别(自然语言处理中识别人名、地名、机构名等特定意义实体的技术)来提取法官、法院、法律概念;用专用机器学习模型按法律领域分类判决;为每家格式各异的法院开发定制解析器。我们有工程师花费数年时间搭建并维护这套底层架构。这确实是令人印象深刻的技术,也是一条真正的护城河,因为复制它意味着数年的工作。
而在Fintool,我们完全没有构建这些。零命名实体识别,零定制解析器,零行业专用分类器。为什么?因为前沿模型已经知道如何解析10-K报表。它们知道家得宝的股票代码是HD,理解GAAP和非GAAP营收之间的区别。它们无需被教导就能解析分段披露的嵌套表格。Doctrine花费数年构建的解析架构,现在已成为模型免费提供的商品化能力。
LLM让这变得轻而易举。前沿模型已经从训练数据中学会了如何解析SEC文件。它们理解10-K报表的结构,知道在哪里找到收入确认政策,如何调节GAAP和非GAAP数据。你不需要构建解析器,模型本身就是解析器。输入一份10-K报表,它能回答关于它的任何问题。输入整个联邦判例法库,它能找到相关的先例。
垂直软件花费数十年构建的解析、结构化和查询能力,现在已成为基础模型本身自带的通用功能。数据本身并非一文不值,但「让数据可搜索」这一层(大量价值和定价权所在)正在崩塌。
4. 人才稀缺性 → 被逆转
构建垂直软件需要既懂领域又懂技术的人。既能写生产代码又懂信用衍生品结构的工程师,极为稀有。这种稀缺性创造了天然的进入壁垒,历史上限制了任何垂直领域内真正有实力的竞争者数量。
LLM完全颠覆了这条护城河。
在 Doctrine,招聘非常严苛。我们要的不只是优秀的工程师,而是能真正理解法律推理的工程师:先例如何运作,司法管辖区如何相互作用,以及向最高法院上诉的理由是什么样的。这种人几乎不存在。所以我们只能自己培养。每周我们都会举办内部讲座,由律师向工程师讲解法律系统的实际运作方式。一个新工程师,往往要过好几个月才能有产出。人才稀缺是真正的壁垒,不仅对我们,对任何试图与我们竞争的人也是如此。
在Fintool,我们完全不需要做这些。我们的领域专家(投资组合经理、分析师)直接将自己的方法写进Markdown技能文件。他们不需要学习Python,不需要理解API。他们用日常语言描述一个好的DCF分析是什么样的,LLM去执行它。工程部分由模型处理。领域专业知识,这一直是丰富的资源,现在可以直接转化为软件,而不再受制于工程瓶颈。
LLM让工程部分变得唾手可得,这意味着稀缺资源(领域专业知识)突然间在转化为软件的能力上变得充裕。这就是进入壁垒如此急剧崩塌的原因。
5. 捆绑销售 → 被削弱
垂直软件公司通过捆绑相邻功能来拓展业务。彭博从市场数据起步,然后增加了消息、新闻、分析、交易和合规模块。每新增一个模块,都会提高客户的转换成本,因为客户现在依赖的是整个生态系统,而不仅仅是一个产品。标普全球以440亿美元收购IHS Markit正是这种策略。捆绑本身成了护城河。
在Doctrine,捆绑是我们的增长策略。我们从判例法搜索起步,然后增加了法规、法律新闻、动态提醒、文档分析。每个模块都有自己的界面、自己的新手引导、自己的客户工作流。我们构建了复杂的仪表盘,律师可以在上面配置监控列表,设置特定法律主题的自动提醒,管理他们的研究文件夹。每一个功能都意味着更多的设计工作、更多的工程投入、更多的界面体量。这些捆绑锁定了客户,因为他们整个工作流都围绕我们的生态系统构建。
LLM agents打破了捆绑护城河,因为agents本身就是捆绑。在Fintool,提醒就是一个提示词,监控列表是一个提示词,投资组合筛选是一个提示词。没有为每个功能单独设置模块,没有需要维护的界面。客户说"当我的投资组合中有任何公司在财报电话中提到关税风险时提醒我",它就能自动运行。agents在一个工作流程中协调十个不同的专门工具。它可以从一个来源获取市场数据,从另一个来源获取新闻,通过第三个来源运行分析,并汇总结果。用户永远不知道也不关心背后查询了五个不同的服务。

当集成层从软件供应商转移到AI agent时,购买捆绑包的动机就消失了。当一个agent可以为每个功能挑选最好(或最便宜)的提供商时,为什么还要为彭博的全套服务支付溢价?
这并不意味着捆绑模式会一夜消失。毕竟,管理十家供应商与只管理一家,在运营复杂度上的差异是真实存在的。但趋势是明确的:agents使"解绑"变得可行,这在以前是不可能的。
6. 私有和专有数据 → 变得更强
一些垂直软件公司拥有或授权了别处不存在的数据。彭博从全球交易台采集实时定价数据。S&P Global拥有信用评级和专有分析。邓白氏维护着超过5亿家实体的商业信用档案。这些数据通常是经过数十年,通过独家关系收集而来的。你无法简单地抓取,也无法重新创造。
如果你的数据确实无法复制,LLM会让它更有价值,而不是降低。
彭博从交易台获得的实时定价数据?无法爬取,无法合成,也无法从第三方授权。在LLM的世界里,这种数据成为每个agent都需要的稀缺输入。彭博在专有数据上的定价能力实际上可能会增强。
S&P Global的信用评级也类似。信用评级不仅仅是数据,它是一种观点,背后有受监管的方法论和数十年的违约数据支持。LLM无法发布信用评级,但标普可以。
测试方法很简单:这些数据能否被其他人获取、授权或合成?如果不能,护城河保持。如果能,你就有麻烦了。
我在两家公司都见证过这种情况。当我们创办Doctrine时,核心价值是用行业特定的架构(分类法、引用网络、相关性排名)来梳理公开判例法。但团队很早就意识到,仅靠公开数据是不够的。
大约五年前,我们开始建立一个独家内容库:专有的法律注释、编辑分析、精心策划的评论。如今,这个库确实难以复制,它已成为真正的护城河。
能在这场转型中幸存下来的公司,正是那些从"我们更好地组织公开数据"转向"我们拥有你在别处无法获取的数据"的公司。
变化在于:那个智能层过去需要多年的工程投入,现在已成为模型自带的能力。甚至数据访问本身也在被商品化。MCP(模型上下文协议|一种数据标准化协议)正在将每个数据提供商变成一个插件。已经有数十家公司以MCP服务器的形式提供金融数据,任何AI agent都可以查询。当你的数据作为Claude插件可用时,“让数据可访问”的溢价就消失了。
讽刺的是,LLM加速了两极分化。拥有专有数据的公司赢得更多,没有的公司将失去一切。
如果你的数据不是真正独特的,如果它可以在别处获取、授权或合成,你就不安全,你面临被商品化的风险。AI agent将拥有与客户的关系,它将成为用户交互的界面、他们信任的品牌、他们付费的产品。你变成了agent的供应商,而不是客户的供应商。
这是聚合理论在实时上演:聚合者(agent)捕获用户关系和利润,而供应商(数据提供商)为了接入平台而竞相压价。如果彭博、FactSet和十几家小型提供商都提供类似的市场数据,agent将选择最便宜的那个。你的定价权消失了,利润被压缩,你最终只能沦为别人产品里一个廉价的原料供应商。
7. 监管与合规锁定 → 结构性的
在医疗领域,Epic的主导地位不仅仅在于产品质量,还在于HIPAA合规性、FDA认证以及医院需要忍受的18个月实施周期。更换电子病历(EHR)供应商是一个长达数年、耗资数百万美元的项目,甚至可能危及患者安全。在金融服务领域,合规要求也造成了类似的锁定:审计追踪、监管报告、数据保留政策,全都内嵌在软件中。
HIPAA不关心LLM。FDA认证不会因为GPT-5的存在而变得更容易。SOX合规要求不会因为Anthropic发布了新插件而改变。
Epic在医疗EHR领域的主导地位本质上是一种监管护城河。那18个月的实施周期、合规认证、与医院计费系统的集成,所有这些都不受LLM的影响。
事实上,监管要求可能会在合规锁定最强的垂直领域减缓LLM的采用。医院不能用LLM agent取代Epic,因为LLM agent未获得HIPAA认证,没有所需的审计追踪,也未获得FDA对临床决策支持的验证。
8. 网络效应 → 具有粘性
一些垂直软件随着行业内更多参与者使用而变得更有价值。彭博的即时通讯功能(IB chat),是华尔街事实上的通讯层。如果每个交易对手都使用彭博,你就必须使用彭博。不是因为数据,而是因为网络。
LLM不会摧毁网络效应。如果有什么影响的话,它们可能会让通讯网络变得更有价值。流经这些网络的信息变成了训练数据、上下文和信号。
同样的情况也适用于任何作为行业内通讯层的垂直软件。Veeva在制药公司间的网络效应,Procore 在建筑行业各参与方之间形成的网络效应,这些都是具有粘性的,因为价值来自于平台上的其他用户,而不是来自于界面。
9. 交易嵌入 → 持久
一些垂直软件直接嵌入资金流中。餐厅的支付处理,银行的贷款发放,保险公司的理赔处理。当你嵌入交易时,转换意味着中断收入。没人会自愿这么做。
如果你的软件处理支付、发放贷款或结算交易,LLM无法绕开你。它可能为你提供更好的前端界面,但底层交易系统仍然是必不可少的。
Stripe不受LLM威胁,FIS或Fiserv也是如此。交易处理层是基础设施,而非界面。
10. 记录系统地位 → 长期受威胁
当你的软件是关键业务数据的权威来源时,转换不仅不方便,还存在生存风险。如果迁移过程中数据损坏了怎么办?如果历史记录丢失了怎么办?如果审计追踪中断了怎么办?
Epic是患者数据的记录系统,Salesforce是客户关系的记录系统。这些公司受益于留下成本与离开成本的不对称性:留下,只需支付高昂费用;离开,却要承担数据丢失、业务中断的巨大风险。
LLM目前并不会直接威胁记录系统的地位。但agent正在悄悄构建自己的记录系统。
情况是这样的:AI agent不仅查询现有系统,它们h还会读取你的SharePoint、Outlook、Slack。它们收集用户数据,编写跨会话持久的详细记忆文件。当它们执行关键操作时,会存储这些上下文。久而久之,agent积累的用户工作画像,会比任何单一记录系统都要更丰富、更完整。
agent的记忆成为新的信息源。不是有人刻意安排,而是因为agent是唯一能看到一切的层级。Salesforce看到你的CRM数据,Outlook看到你的邮件,SharePoint看到你的文档。agent三者都能看到,并记住。
这不会一蹴而就。但从方向上讲,agents 正从零开始建立自己的记录系统。随着agent上下文记忆的增长,传统的记录系统的护城河会逐渐削弱。
二、对抛售的看法
净效应:进入壁垒崩塌
综合来看,五条护城河被摧毁或削弱,五条能稳住。但被摧毁的五条正是阻止竞争者进入的那些。而得以保留的,只有部分现有企业才拥有。
LLM出现之前,构建一个能与彭博匹敌的有力竞争者,需要数百名懂行的工程师、数年的开发时间、大规模的数据授权协议、能攻克保守企业的销售团队,以及监管认证。结果就是:大多数垂直领域只有 2-3 个有力竞争者。
LLM出现之后,一个小团队,利用前沿模型API、领域专业知识和良好的数据管道,就能在数月内构建一个能完成垂直软件80%功能的产品。我亲身经历过,因为Fintool就是由一个六人团队构建的。我们服务的对冲基金,以前只依赖彭博和FactSet。不是因为我们有更好的数据,而是因为我们的AI agent比需要多年训练才能掌握的终端/工作站,能更快速、更直观地提供答案。
关键洞见在于,竞争不是线性增长——而是组合式爆发。行业不是从3家现有企业增加到4家,而是从3家直接跳到300家。这正是定价权崩溃的原因。在LLM之前,每个垂直领域都只有2-3家主导企业,因为进入壁垒高不可攀,它们能收取高价。当50家AI原生初创公司能以20%的价格提供80%的功能时,这种局面就彻底改变了。
微妙之处:这是一个多年的转型,而非一夜崩塌
我认为市场在时机判断上可能错了,即使方向是正确的。
企业收入不会一夜消失。
FactSet的客户签的是多年合同。彭博终端的合同通常至少两年。这些合同不会因为Anthropic发布了一个插件就蒸发。
企业采购周期以季和年计,而非以天计。一个500亿美元的对冲基金不会因为Claude能查询SEC文件,明天就撤掉标普全球的CapIQ(标普旗下的一个研究平台)。他们会用12-18个月评估替代方案,运行试点项目,谈判合同条款,等待现有合同到期。
收入悬崖是真实存在的,但它是一个斜坡,而不是峭壁。当前收入在未来12-24个月内基本上是锁定的。
但市场已经明白的是:不需要收入下降股票才会崩盘,只需要估值倍数压缩。一家金融数据公司,当它拥有定价权和95%的留存率时,交易倍数是收入的15倍;当市场认为这两者都在被侵蚀时,可能只值6倍。收入保持不变,股价却跌了60%。而这,正是当下部分企业正在经历的现实。
市场不是在为收入崩溃定价,而是在为溢价倍数的终结定价,因为支撑那个倍数的护城河正在消融。
三、真正的威胁
真正的威胁不是LLM本身,而是一个垂直软件现有企业未能预见的钳形攻势。
从下方看,数百家AI原生初创公司正涌入各个垂直领域。当构建一个可信的金融数据产品需要200名工程师和5000万美元的数据授权费用时,市场自然整合到3~4个玩家。而当它只需要10名工程师和前沿模型API时,市场就会剧烈碎片化,竞争者从3家直接飙升至300家。
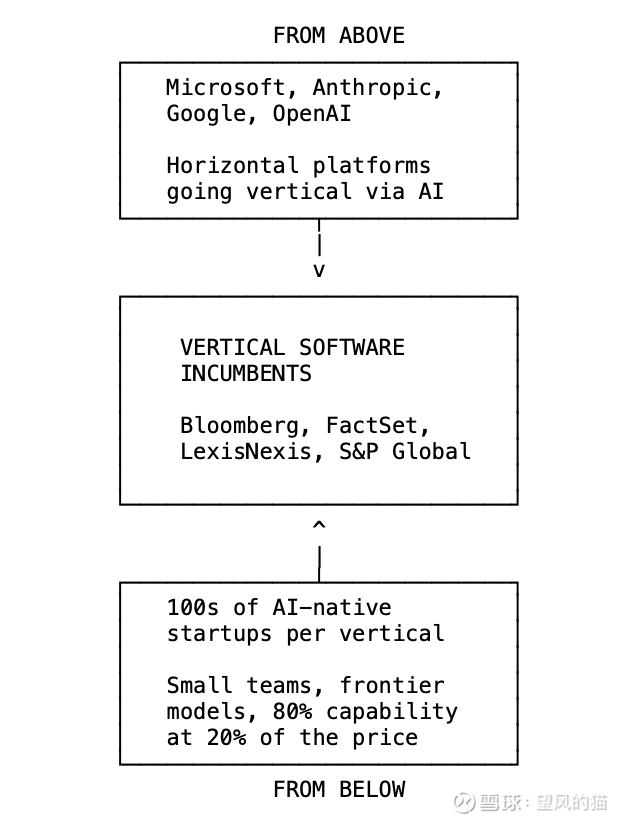
从上方看,水平平台首次深入垂直领域。微软Copilot在Excel内部进行AI驱动的DCF建模和财务报表解析。Copilot在Word内部进行合同审查和判例法研究。水平工具通过AI,而非通过工程,变得垂直化。
Anthropic正从另一个方向做着同样的事情。我之所以近距离观察着这一切,因为Fintool是一家Anthropic投资的公司。Claude正在全力进军垂直领域。其策略简单得可怕:一个通用agent工具包(SDK),可插拔的数据访问层(MCP),以及特定领域的技能(Markdown文件)。就这些。这就是你从水平走向垂直所需的全部技术栈。不需要领域工程师,不需要多年的开发。
软件正在变得"无头化"。界面消失了。一切都通过agent流动。重要的不再是软件本身,而是拥有客户关系和使用场景,这意味着拥有agent本身。
实现垂直深度的技术(LLMs + 技能 + MCP),正是让水平平台最终能够进入它们以前从未能触及的领域的技术。这或许是垂直软件最根本的生存威胁:像微软这样的水平B2B巨头,不再只是浅尝辄止地涉足垂直领域 —— 它们正强势大举进军。原因很简单:如今切入垂直领域比以往任何时候都容易,更重要的是,在这个 AI 优先的时代,它们必须掌控核心应用场景和工作流,才能保持自身的竞争力。
四、风险评估框架
并非所有垂直软件都面临同等风险。以下是我对哪些类别能够存活、哪些不能的思考框架。
高风险:搜索层
如果你的核心价值只是通过专业界面让数据可搜索和访问,而底层数据是公开或可授权的,那你就麻烦大了。这包括基于持牌交易所数据构建的金融数据终端、基于公开判例法的法律研究平台、专利检索工具,以及任何本质上只是“我们为你的行业打造了一个更好的数据搜索引擎”的垂直产品。
这些公司之所以能有15-20倍收入的估值,靠的是界面锁定和有限的竞争。这两者都在消失。看看过去一年市值蒸发40-60%的金融数据提供商。市场对它们重新定价是正确的。
中等风险:混合组合
许多垂直软件公司,同时拥有可防御和易受攻击的业务线。一家公司可能有一个真正专有的评级业务,同时也有一个主要是重新包装公开信息的数据分析板块。或者有一个嵌入交易的指数授权业务(非常可防御),同时也有一个纯粹搜索层的研究平台(非常易受攻击)。
该类股票下跌(20-30%),反映了市场对哪些细分板块主导估值的不确定性。关键问题是:收入中有多大比例来自LLM无法触及的护城河?
较低风险:监管堡垒
如果你的护城河是监管认证、合规基础设施以及与关键任务工作流的深度集成,那么中期内,LLM基本不会影响你的竞争地位。比如,具备HIPAA 合规和 FDA 认证的医疗电子病例系统,具有监管锁定的生命科学平台、财务合规和报告基础设施。
这些公司甚至可能从其他地方的AI颠覆中受益,因为客户会围绕他们信任的供应商进行受监管的工作流,同时从他们过去用于信息检索的供应商转出。
五、测试方法
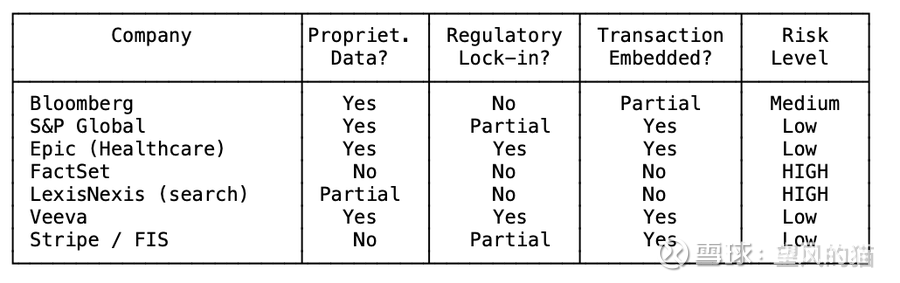
对于任何垂直软件公司,只需问三个问题:
1. 数据是专有的吗?
是 → 护城河依然稳固
否 → “让数据可访问”这层壁垒正在崩塌
2. 是否存在监管锁定?
是 → LLM不会改变切换成本的计算公式
否 → 转换成本主要由界面驱动,且正在消融
3. 软件是否嵌入交易?
是 → LLM只会叠加在你之上,而非取代你
否 → 你是可替代的。
零个"是":高风险。
一个"是":中等风险。
两个或三个"是":你大概没问题。
我在两边都学到的经验
当我从2016年开始创建Doctrine时,护城河之一就是界面。我们在判例法和成文法上构建了漂亮的搜索体验。律师们喜欢它,因为它比市场上的任何产品都更快、更直观。大部分数据是公开的,但我们的界面和搜索使其易于获取。如果今天从零开始创建Doctrine,将面临一个完全不同的竞争格局。一个LLM agent就可以像我们的界面一样高效地查询判例法。
垂直SaaS的这场清算,并非意味着所有垂直软件都会消亡。而是市场终于开始区分:谁真正拥有LLM agent无法撼动、真正稀缺的核心壁垒。