CPO 为英伟达AI工厂的核心使能器


2025年8月18日 Ashkan Seyedi 英伟达产品营销总监
随着人工智能重新定义计算格局,网络已成为塑造未来数据中心的关键支柱。大型语言模型训练的性能不仅取决于计算资源,还取决于底层网络的敏捷性、容量和智能性。业界正在见证从传统的以CPU为中心的基础设施向紧密耦合、由GPU驱动、网络定义的 AI 工厂的演变。
NVIDIA 构建了一套全面的网络解决方案,以满足现代 AI 大规模训练和推理的快速突发、高带宽和低延迟需求。这套解决方案包括Spectrum-X 以太网、NVIDIA Quantum InfiniBand和BlueField平台。通过协调计算和通信,NVIDIA 网络产品组合为可扩展、高效且具有弹性的 AI 数据中心奠定了基础,而网络是赋能未来 AI 创新的中枢神经系统。
人工智能工厂基础设施与传统企业数据中心相比如何?
在传统的企业数据中心中,一级交换机集成在每个服务器机架内,允许直接通过铜缆连接到服务器,并最大限度地降低电源和组件的复杂性。这种架构足以满足以 CPU 为中心的工作负载,且网络需求适中。
相比之下,NVIDIA 率先打造的现代 AI 工厂拥有超高密度的计算机架和数千个 GPU,这些 GPU 的架构设计使其能够协同完成一项任务。这要求整个数据中心拥有最大的带宽和最小的延迟,因此需要新的拓扑结构,将一级交换机迁移到行尾。这种配置极大地增加了服务器和交换机之间的距离,使得光纤网络至关重要。因此,功耗和光学元件数量显著增加,现在网卡到交换机以及交换机到交换机的连接都需要光学元件。
如下图1所示,这种演变反映了满足大规模AI工作负载的高带宽、低延迟需求所需的拓扑结构和技术的重大转变。它从根本上重塑了数据中心的物理和能源配置。

图 1. 横向扩展和 AI 密度取决于光纤连接。
如何优化人工智能工厂的网络可靠性和功率?
采用可插拔收发器的传统网络交换机依赖于多个电气接口。在这些架构中,数据信号必须经过漫长的电气路径,从交换机ASIC到PCB、连接器,最终到达外部收发器,然后转换为光信号。这一分段式传输会产生巨大的电气损耗,对于200千兆/秒的信道,损耗高达22 dB,如下图2所示。这加大了对复杂数字信号处理和多个有源元件的需求。
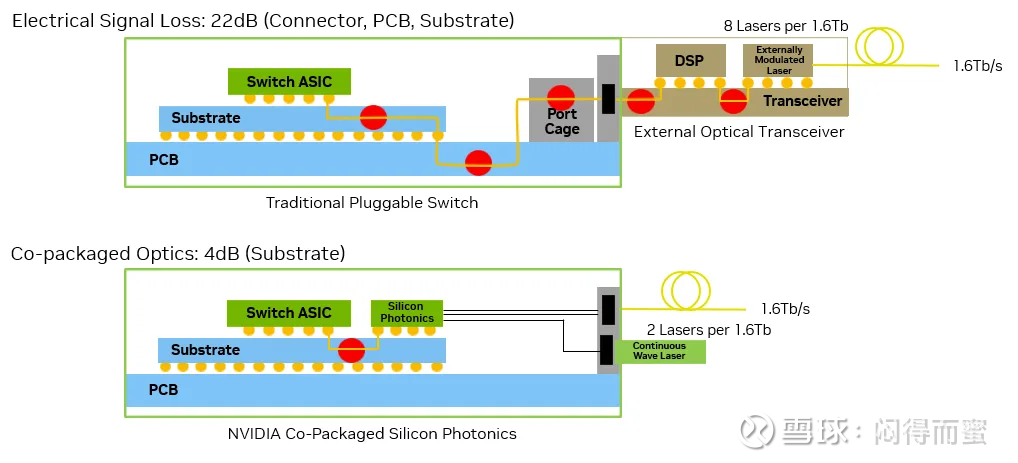
图 2.Spectrum-X Photonics 提供 64 倍更好的信号完整性。
其结果是功耗更高(通常每个接口 30W),发热量增加,潜在故障点增多。大量的分立模块和连接不仅增加了系统功耗和组件数量,还直接损害了链路可靠性,随着人工智能部署规模的扩大,这会带来持续的运营挑战。组件的典型功耗如下图 3 所示。
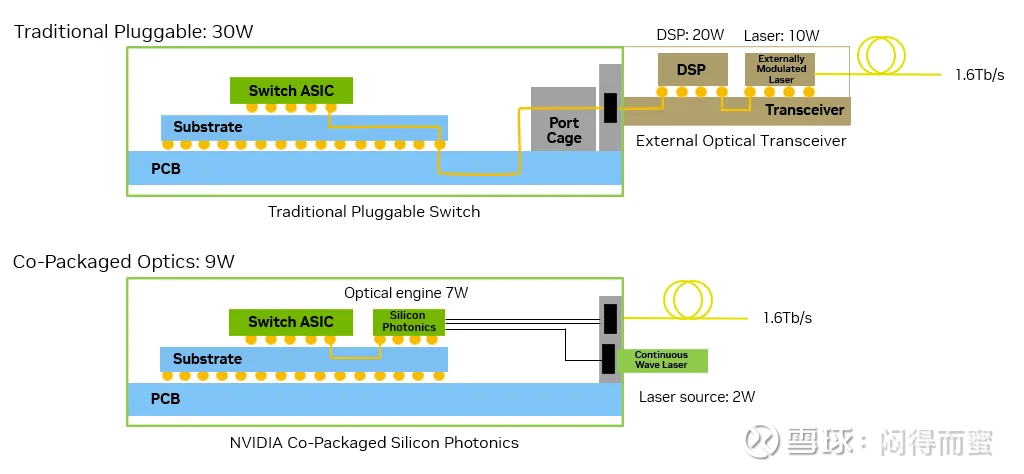
图 3. 使用 Spectrum-X Photonics 可节省 3.5 倍能源
相比之下,采用共封装光学器件 (CPO) 的交换机将电光转换直接集成到交换机封装中。光纤直接连接到位于 ASIC 旁边的光学引擎,将电气损耗降低至仅约 4 dB,并将功耗降至 9W。通过简化信号路径并消除不必要的接口,这种设计显著提高了信号完整性、可靠性和能效。这正是高密度、高性能 AI 工厂所需的。
共封装光学器件能为AI工厂带来什么?
NVIDIA 设计了基于 CPO 的系统,以满足前所未有的 AI 工厂需求。通过将光学引擎直接集成到交换机 ASIC 上,全新的 NVIDIA Quantum-X Photonics 和 Spectrum-X Photonics(如下图 4 所示)将取代传统的可插拔收发器。这些新产品简化了信号路径,从而提高了性能、效率和可靠性。这些创新不仅在带宽和端口密度方面创下了新纪录,而且还从根本上改变了 AI 数据中心的经济性和物理设计。

图 4:集成共封装硅光子引擎的 NVIDIA 光子交换机 ASIC
Quantum-X Photonics 如何标志着下一代 InfiniBand 网络
随着 NVIDIA Quantum-X InfiniBand 光子技术的推出,NVIDIA 将 InfiniBand 交换机技术推向了新的高度。该平台具备以下特性:
115 Tb/s 交换容量,支持 144 个端口,每个端口 800 Gb/s
液体冷却实现卓越的热管理
NVIDIA Quantum-X 利用集成硅光子技术,实现无与伦比的带宽、超低延迟和运营弹性。一体封装的光学设计可降低功耗、提高可靠性、实现快速部署,并支持代理 AI 工作负载的海量互连需求。
Spectrum-X Photonics 如何实现大规模以太网 AI 工厂
NVIDIA Spectrum-X Photonics 交换机将 CPO 革命扩展到以太网领域,专为生成式 AI 和大规模 LLM 训练及推理任务而设计。全新 Spectrum-X Photonics 产品包括两款基于 Spectrum-6 ASIC 的液冷机箱:
Spectrum SN6810:带宽 102.4 Tb/s,128 个端口,速率为 800 Gb/s
Spectrum SN6800:带宽 409.6 Tb/s,拥有 512 个 800 Gb/s 端口
这两个平台均采用 NVIDIA 硅光技术,大幅减少了分立元件和电气接口的数量。与之前的架构相比,其能效提升了 3.5 倍,并通过减少可能发生故障的光学元件数量,将弹性提升了 10 倍。技术人员受益于更佳的可维护性,而 AI 操作员的开机时间则缩短了 1.3 倍,首次令牌获取时间也得到了显著提升。
CPO 如何实现性能、功率和可靠性突破
共封装光学器件的优势显而易见:
3.5 倍功率效率:通过消除可插拔收发器并将光学器件直接集成到交换机 ASIC 封装中,即使网络密度飙升,每个端口所需的功率也会大幅下降。
10 倍更高的弹性:更少的离散有源元件和易发生故障的收发器的移除提高了正常运行时间和运行可靠性。
1.3 倍更快的运营时间:简化的装配和维护意味着加速部署和快速扩展 AI 工厂。
该交换机系统实现了业界领先的带宽(高达 409.6 Tb/s 和 512 个 800 Gb/s 端口),并采用高效液冷技术,可应对高密度、高功率环境。图 5(下图)展示了 NVIDIA Quantum-X Photonics Q3450 以及 Spectrum-X Photonics 的两个版本——单 ASIC SN6810 和集成光纤重组的四 ASIC SN6800。
这些产品共同支撑着网络架构的变革,满足了人工智能工作负载带来的持续带宽和超低延迟需求。尖端光学组件与强大的系统集成合作伙伴强强联手,打造出针对当前和未来扩展需求而优化的结构。随着超大规模数据中心对更快部署速度和坚不可摧的可靠性的需求不断增长,CPO 从创新走向了必需。

图 5. NVIDIA Quantum-X 和 Spectrum-X Photonics 交换机系统
这将如何引领人工智能的下一个时代
NVIDIA Quantum-X 和 Spectrum-X 光子交换机标志着网络向专为满足大规模 AI 的持续需求而构建的转变。通过消除传统电气和可插拔架构的瓶颈,这些一体封装的光学系统可提供现代 AI 工厂所需的性能、能效和可靠性。NVIDIA Quantum-X InfiniBand 交换机预计将于 2026 年初投入商用,Spectrum-X 以太网交换机预计将于 2026 年下半年投入商用,NVIDIA 正在为代理 AI 时代的优化网络树立标杆。