迎接国产算力的架构创新红利时代

闷得而蜜
· 广东
英伟达首席科学家在一次学术会议上,分享了一组数据,Nvidia的GPU算力,在过去十年,性能提升了1000倍。
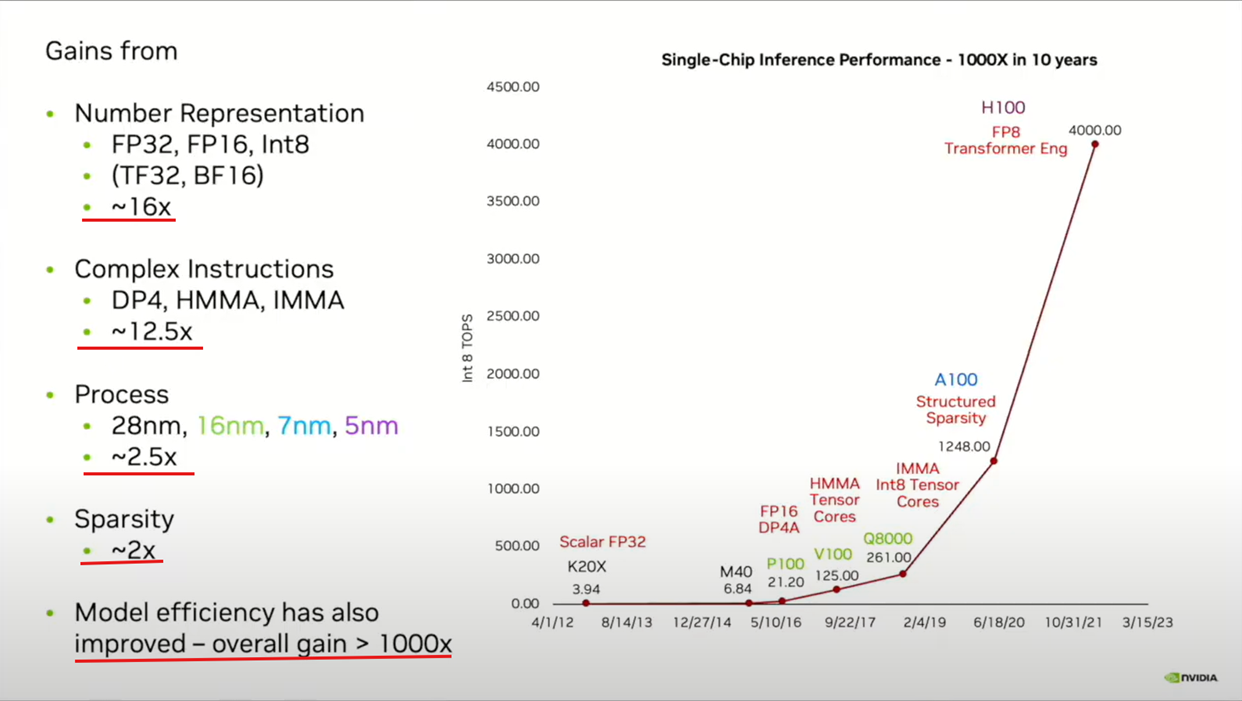
和多数人直觉不同:工艺红利(process)仅带来 2.5 倍收益,而架构创新才是核心 —— 数据精度(16 倍)× 指令集(12.5 倍)× 算法模型(2 倍),足足撑起 400 倍增益。
架构创新潜力巨大,而我国才刚起步。
对国产算力而言,虽难享工艺红利,但明年大概率迎来一波架构红利爆发。这个架构的总设计师是DeepSeek:

这波创新的核心框架由 DeepSeek 搭建:以 MoE 混合专家模型、FP8/4 低精度算子为基础,搭配 UB-MESH 架构与 CPO 技术,将推动国产 AI 算力实现指数级非线性跃迁—— 10~50倍提升。从华为 Atlas SuperPOD,到阿里平头哥、寒武纪思元,都会跟进这条路径 。
今年初 DeepSeek 已经做出示范:算法 - 软件 - 硬件联合优化,藏着巨大潜力。寒武纪拿到定增支持后,资金底气足了,更能放开手脚突破。
半导体工艺是根基,是电子产业的明珠,但性能提升是 0.5 倍、0.5 倍的线性慢爬;
架构创新 + 算法软硬件优化,核心是人才,但性能提升是 10 倍 ×10 倍的指数级跃升。
八仙过海各显神通,国产算力正迎来架构创新的红利期,值得期待。
坚定看多国产算力,坚定看多国产算力产业链。