字节Seedance2.0的惊艳——看2026年算力“铲子股”的确定性

这两天试用了字节跳动新出的 Seedance 2.0,效果确实炸裂,未来的创作门槛会被大幅拉低。但有一个细节耐人寻味:非常吃算力。
这让我想到了谷歌的视频生成模型(Veo),我一天只能用三次。为什么限制次数?不是谷歌小气,而是目前的单位生成成本太高了。
结论很简单: 视频生成的算力消耗是指数级的。如果说文生图是“吃肉”,文生视频就是“吞金”。应用越强,对算力的饥渴就越严重。
下面我给几个基础的数据论证。
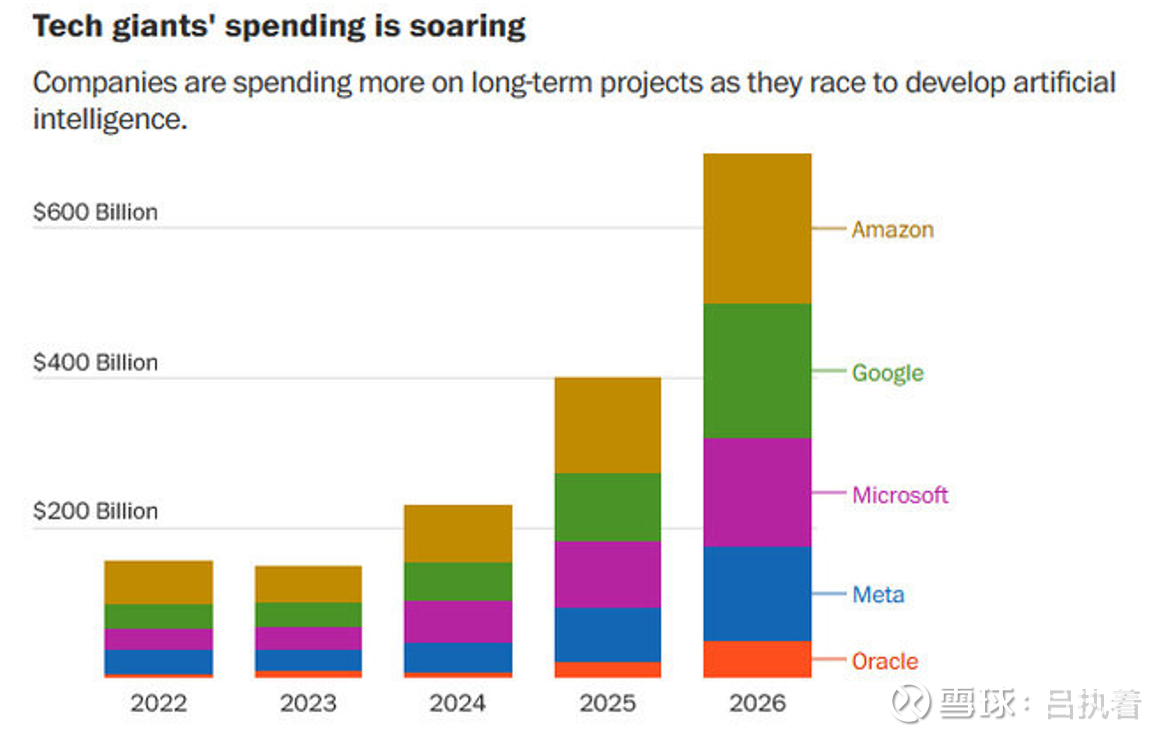
一:巨头的军备竞赛(CapEx War)
很多人担心AI是泡沫,但看看我贴的这张图(美国科技巨头资本开支预测),逻辑就很硬:
注意看 2026年 的柱状图,这几家的总支出将冲击 6000亿美元 级别。
这笔钱去哪了?绝大部分都砸向了AI基础设施(数据中心、服务器、网络设备)。
目前很多人担心,是左脚踩右脚上天,但是在维度更高的决策上,世界顶级巨头几万亿的投入,对标的是AI的工业革命3.0大基建,这方面,我们也需要持续密切的跟踪。
二:推理侧爆发倒逼基建狂飙
2023-2024是“训练侧”在买卡,而随着Seedance 2.0、Sora、Veo这类杀手级应用的落地,2025-2026将迎来“推理侧”的指数级爆发。
视频生成的算力消耗是指数级的,而非线性的。
从“画皮”到“画骨”: 早期的AI(如文生图)只需要生成一张静态图片。而Seedance 2.0 这种级别的视频模型,不仅要生成每秒24-60帧的画面,还要保证这些帧之间的时间连续性(不闪烁、物体不变形)、物理规律的合理性(重力、光影)以及长镜头的逻辑性。
推理解析成本: 训练模型(Training)虽然昂贵,但那是一次性的;而用户每生成一次视频(Inference),后台的GPU集群就需要进行海量的矩阵运算。
谷歌的“算账”: 谷歌给你限制一天3次,正是因为目前的单位生成成本太高了。在商业模式跑通之前,即使是地主家(Google)也没有余粮无限量供应这种高昂的算力资源。
所以应用越强,对算力的消耗越恐怖。Seedance 2.0 效果越好,说明它背后的参数量越大,对推理算力的需求就越像个无底洞。
只要巨头还在为了争夺AI入口而打仗(看图里的支出斜率),它们就必须无上限地堆算力。这就回到了那个最朴素的逻辑:淘金热里,不管谁挖到金子,卖铲子的人稳赚。
三:“光”的逻辑
在这个逻辑下,我看好 2026年的光模块(涨了十倍再发文看好是不是特别蠢?),这里,其实还是跟着头部大厂的决策走的,在去年年初deepseek横空出世,用了更少的算力,出来更强的性能,一时间似乎算力过剩的言论遍地都是,目前其实全部被证伪了,人家也是一直用英伟达悄悄训练,而且算力非常非常缺,回过头看,那是一次绝佳的上车机会。
当GPU集群从万卡迈向十万卡,互联带宽(光模块)是最大的瓶颈。800G向1.6T切换的周期里,量价齐升的逻辑依然坚挺。
这就好比我之前研究CXO的逻辑:不管药(大模型)最后是谁跑出来,作为卖水人(基础设施),业绩的确定性来源于行业的资本开支。看着即梦2.0生成的视频,再看看这张Capex图表,我觉得2026年的AI投资的路径也很清晰:拥抱算力基建,拥抱确定性。
最近光模块因为可插拔以及CPO的路径,头部出了非常漂亮的业绩,然后股价连着暴跌一周,正好给了我比较多的上车机会,如果有人感兴趣,后续我们可以详细来拆解一下这个路径的问题,至少目前从头部厂商选择来看,可插拔,已经过渡的NPO封装,还是主流趋势,未来CPO会不会统一?我觉得不可能,就好比CART的成本是极其高昂的,头部也一定会做体内通用疗法,疗效我可以略微降低一点,但一定要把成本打下来。