
针对国内外AI进展以及H20说一下 0731(再删就不写H20了)
说实话最近美股业绩报密集 而且基本都是新高+惊喜超预期
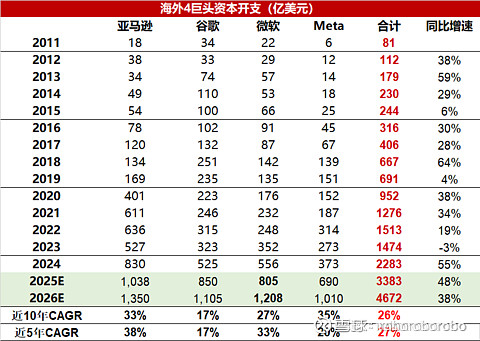
连同csp的capex也是 这个图就挺好的 其中还没有包络现在
风格激进堪比微软的oracle和杠杆猛猛加单的coreweave
1 今天比较惹人争议的主要是H20&国产算力的问题
我就来说说自己的观点
首先上 不是第一第二次了
去年也是 前年也有也谈过 所以大家基本上看到国资背景的主体采购N卡(节点里面有肯定不算 因为节点里面的卡肯定是民企的 当然也有YD这种特殊的)
最典型的就是三大运营商 如果自己拆三大运营商公开的capex几乎清一色是全体国产芯片 opex里面才会有一些租赁n卡的内容
而最早些时候甚至要求建设ai数据中心里面国产卡的含量要超过XX%百分比来着(现在倒是没有那么严格了)
这次约谈 我个人的理解是:谈判的筹码+怕钓鱼执法后不发货(交名单写用处各种)
但是个人觉得即使炒股 也要尊重现实(就好比国产现在真的没有办法大规模大规模流片 满足大厂级别的流片规模 大家也知道我是很想推和爱国产GPU和算力的 并且每周几乎更新 也希望国产算力有BETA 但是客观来说 也必须尊重现实 现在就是商业性价比+流片效率+互联集群 根本没法跟H20比)
而现实就是台积电最近两周最大的变化就是NV加钱紧急加单了
主要加的是以前做外的wafer bank
分别包络H200和H100 h20的片 大概可以每片切30~35颗左右
经过筛选只要最高的 差不多是30~35颗中 品质最好的15颗做H20-nvlink的 5颗做H20-pcie版本的
然后8月初直接送到韩国的amkor去和hbm封装成成品 再测试 差不多快的话 由于是加急件 15~30天就可以做成模组了
这个单子是加急的 是nv特地加钱给台积电下的 nv还想用vera cpu的产能去转换成H20的前道去加单20~30W以上 目前台积电由于产能紧缺没有受理(vera cpu 转移到 矽品 做类似于cowosl的FOCoS-Bridge)
一般来说台积电前道-成品 tapein到out 需要5~6个月
但是台积电有一个特例 就是有加钱的加急件 根据加钱等级的不同 最快可以让5~6个月的tape out时间缩短到3~4个月左右
而目前这批库存的wafer bank的H20不需要前道 只要筛选+切片严选即可 最快15天~1个月就可以做成模组 只要bis许可没问题 直接发给卖家
据我所知基本都是国内的互联网大厂 Z A T B 团 拼 米基本都有
ZAT来说都是之前定的 新增的并不是太多 但是基本都加了一些 之前取消后重新交付 差不多是20W+22W+10~20W的级别
总共根据台积电库存+可能的新流片情况来说 基本复合我之前说的就是库存50W片成品 waferbank筛选大概30~40W 新流片30W片左右(台积电还没受理)
如果完全顺利的话 最终应该是有110~120W片的H20的订单
我们来说说为啥大厂还愿意采购H20
上次我聊到过 自从B200顺利出产之后 H系列的租赁价格都下降了
因为B200效率太逆天了 300W出头的价格(H200 210W左右)
基本效率是H200的2~3倍起步(跟别说GB200了) 那商业效率摆在这边 说实话不选B200还复购H20的意义何在?
主要是现在国内的大部分模型或者应用公司基本都是的需求都是后训练的人类反馈强化学习(主要就是蒸馏+微调)除了头部的互联网公司自己做闭源或者开源的前训练之外 大部分的小公司的策略都是拿现成的开源模型做HFRL的后训练 所以需要的算力基本上都是推理reasoning算力
所以实际上国产算力做reasoning算力肯定是没问题的 无非就是效率和迁移的问题 效率无非就是组网效率 几百张卡一般来非要跟pcie版本的nv来说 区别不大 迁移无非就是适配cuda或者Triton这些说实话很方便 迁移差点的无非就是闭源的某H
那H20最强大的地方还是千张卡万张卡以上的组网效率+迁移工程成本
那基本上H20大规模组网由于价格优惠HBM高(141GB版本) 甚至比H100的推理效率还高20%
而现在B40的4卡 nvlink900GB 测试4卡模组已经交到了大厂手里 基本属于持平多一些H20的情况
这样显得实际上H20的性价比优势仍然满足(但是肯定比不上B30的NVLINK5+hbm的版本 但是这版有没有 得看8月中下旬了)
所以这也是H20为啥大厂还是愿意采购+nv在台积电加了急单的原因
而且说实话H20只卖芯片模组 组装全靠国内服务器厂 跟配套的光模块交换机毫无关系 这些都是国内的大厂自己采购的国产品牌 跟我们供海外的品牌基本毫无关系可言
我非常希望国产算力有beta 但是说实话 如果真的后续禁止了 对国产反而不是什么好事 对海外链反而没什么影响(目前H20只可能是筹码谈判博弈play中的一环)
目前Z和A都会在8月15号之前拿华东和华北区的aidc指标(今天Z还开一早开了AH大会 虽然没有给明确的capex提升 但是说了很多类似于明年某个和某个细分要做到全球第一的梯队和份额这类的内容)
目前公司都在询标和准备招标 基本两家有个600~1.1GW的询标+招标的量 其实这对国产算力的催化很大 但是如果买不到H20 大概率大厂都会把份额放在国外去询标+招标(当然国产芯片有个好处就是功耗贼高 如果H20 1W卡是13mw 那国产卡或者H基本就是26~30mw起步了 需要的aidc数量和电力基本翻倍 柴发这种也是翻倍起步了-Alexander Wang分析过)
比如今年Z海外时500mw 明年大概率就是1GW起步 A也差不多 今年应该是300mw 明年预测也是500mw起步 为啥 因为海外没那么多卡的限制(出海的话基本也是国内招标光模块交换机柴发 柴发出海如果走海南还能免税。。。现在全球紧缺柴发主要是)
而且大家有一个点总是忽略的 就是云业务的增长 国内差不多同比应该是20~50%的增长 由于大厂愿意投CAPEX和ai业务景气 但是实际上 海外云业务的增长更夸张 基本都是50%~100%起步 这得益于我们有很多出海的企业的ai需要(大概占比60%)以及服务海外企业的需求(占比40%)打个比方来说欧洲和南美 虽然基数确实比较低 但是需求来的非常猛 以后中国出海的aidc部分增长会非常快 这点是大家以往忽略的
2 海外这部分具体大家可以多看看业绩会的分析
由于真要写 分析一些一大堆耽误大家时间
我还是更新一下台积电最近的update吧
2.1目前NV最新的update
主要就是B300继续加单 100W颗左右 主要时间差不多是明年的Q1 主要是GB300的生命周期会比大家想象中的更长久
之前我有写道:“Q3的B300流片上调到了150W颗 Q4还是120W颗左右 26年Q1是110W颗左右
其中给了比较好的指引是鸿海和纬创的板卡模组产能预定情况(也就是说板卡就是做GB系列的)
板卡产能目前Q3 鸿海是27W 纬创16W(也就是86W颗GB300=1W2000台GB300Rack量)
Q4 鸿海是25W 纬创20W(也就是90W颗GB300=1W2500台GB300Rack量)
明年Q1 鸿海是22W 纬创20W (也就是84W颗GB300=1W1600台GB300Rack量)
目前看订单 GB300至少有个将近4W的rack量”
那差不多GB300还要增加个1W2000台左右 整个GB300的可见度差不多提高到了5W2台左右
2.2 明年的rubin rubin 单die还是比较顺利的 4xhbm4+io的配置良率已经比较高了 今年主要还是做个几百片测试为主 rubin的生命周期大概从明年Q2开始 分别为rubin 单die 双die 和rubin ulrea 菱形4die这几个版本 对应72 144 288这类奇怪的命名
今天正好看完了rubin 144的ppt(主流rack版本) 有非常多new design 非常多非常多
没法截图 记了很多参数在手机上 比如 cx9首次用液冷端口连接器 4个ospf口 液冷cage
4x800G= 1.6Tx2 124 mcio mcpm
2runbin=4 cx9 4x200 x 4
bianca board=210x365mm mgx spec=210X378mm 2.7mm thin(料号ds-7409 dgn&ds 7409 dxg)
gpu1800w cpu 500w
hscc power train 1.4kw
power ph ftom 144ph per gpu to 2.3kw
busbar 50v pcie6 awg34 还有电源线啥的
连接器有4家供应商 aph-ultrapass te-catapuly lux-omini x&omini stack molrx-cx2-DS
对应数量16 16 16 64 32(容我花几天功夫全部过一遍)
2.3 鸿海的GB300 是微软先做量产 meta的还在做NPI测试打样 其他客户就是oracle 和hpe 其中oracle比较多 差不多9月份大规模量产 GB300相比GB200的普通版本没有什么改动 只有CSP定制版本的GB300有各自相应的改动
2.4 B300这边差不多是8月中开始量产 之前B200是官方版本和超威版本卖的还不错 主要是dell不知道为什么搞了9680L这个液冷板本出了一些奇怪问题 现在B300转成9780的风冷版本 目前看预订量比较多4000台+(8卡)
2.5 博通的加单 谷歌的业绩会大家也看到了 capex也增加了不少 V6p的继续加单 差不多是2W片wafer 50W颗芯片 对应1.6T也是100W以上加单 正好也对应上了
2.6 CPO的进展 台积电这边进展还是老样子 但是多了一些新的2个代号为cpo的新内容
博通帮meta做mtia 有一颗mtia-cpo代号的asic 明年下半年的案子 大概率是通信asic 明年年底 会投测试片
amd ualink-cpo交换机 适配mi4系列 通信asic 明年2季度量产
2.7 关于cowop 台积电目前是观望态度 主要怕sub精密度要求太高 良率会有问题 nv要求做测试板 年初有欣兴之类的送过样品 之前苹果的产品做过cowop 找的台湾华通 soic+cowop(不需要基板 直接在pcb上)目前还早 nv的要求更高 同事谷歌和meta也提出过类似的要求打样
差不多这些内容 写的多 大家觉得看的烦 这周就更新到这里
持续看好ai的景气度 同时希望秋水共长天一色 国产国内都有好的转机吧
ai应用我真的不想讨论 因为我的结论跟以前一样 我大概率只相信这个时代有花钱在算力上ai-infra云能力 或者能做独有数据的大厂才能做出来像样的应用或者agent 然后大部分公司通过to b的形式用大厂的应用和agent去开发自己的应用生态 我觉得才比较合理
毕竟现在是商业化社会 什么都讲究商业化+效率 不是为了硬推行而推行 但是将来的未来一定属于国产算力
永远喜欢AI 大家共勉