崩溃的工作流护城河:聚合理论的终章

原推作者:Nicolas Bustamante
界面的护城河正在瓦解。每一家建立在复杂工作流之上的垂直领域软件公司,都即将以惨痛的方式领悟到这一点。
几十年来,软件公司之所以能获得溢价,不仅是因为其数据,还因为其界面。专门的键盘快捷键、Excel 集成、工作流自动化。用户花费数年时间来精通这些系统。公司围绕特定工具构建了硬编码的业务流程。切换工具意味着巨大的生产力损失。
界面“曾是”产品本身。
我一年没用过 Google 了。LLM 对话框就是我的浏览器。很快,知识工作者也将不再使用专门的软件界面。LLM 对话框将成为他们通往一切的界面。
这并非渐进式的改变。这是 Ben Thompson 聚合理论的终章。
本文包含:
- 为什么聚合理论为供应商留下了一项关键资产:他们的界面
- 垂直软件如何建立在工作流复杂性而非数据之上的帝国
- 为什么 LLMs 会完全吸收界面层
- 当界面被商品化,竞争将演变为 API 对 API 的对决
- 估值框架:残酷的数学逻辑
- 谁赢,谁输,以及接下来的趋势
聚合理论:不彻底的革命
本·汤普森(Ben Thompson)的框架重塑了我们对互联网经济的思考方式。
价值链曾是简单的:供应商 → 分发者 → 消费者。
在互联网时代之前,高昂的分销成本为分销商创造了杠杆。电视网络控制着播出的内容。报纸决定了哪些报道重要。零售商选择了哪些产品能上架。
随后,分发成本降至零。交易成本紧随其后。权力从分发者转移到了一种新物种:聚合者。
汤普森(Thompson)指出了这一良性循环:
更好的用户体验 → 更多的用户 → 更多的供应商 → 更好的用户体验。
聚合者通过掌控消费者关系获胜,将供应商商品化,直到他们变得可以互换。
Web 2.0 聚合层级堆栈
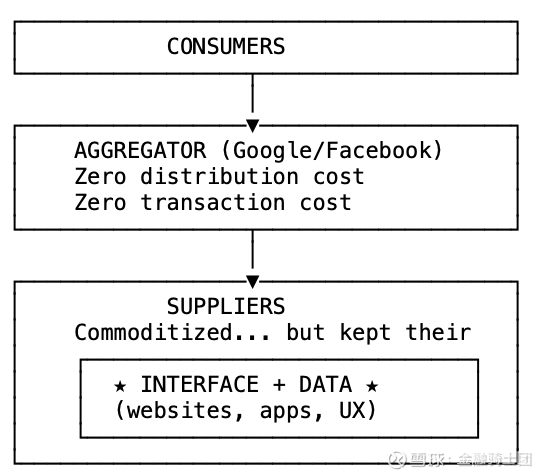
但供应商保留了两项关键资产:他们的界面和数据。
界面护城河:为何商品化曾存在上限
Web 2.0 聚合的悖论是结构性的。
这为商品化设定了一个硬性上限:
- 发现:商品化(由 Google 掌控)
- 界面:受保护(由供应商掌控)
- 数据:受保护(由供应商掌控)
界面层之所以重要,有四个原因:
- 品牌持久性:用户看到的是《纽约时报》,而不仅仅是“一个新闻来源”。品牌资产在聚合效应中得以幸存。
- 用户体验差异化:供应商可以在设计、速度和功能上进行竞争。更好的界面意味着更高的转化率。
- 转换成本:用户养成了肌肉记忆和工作流习惯。学习一套新系统存在切实的摩擦力。
- 变现控制权:供应商拥有自己的转化漏斗。他们控制着付费墙、结账环节以及订阅流程。
垂直软件是一个完美的案例研究。金融数据终端、法律研究平台、医疗数据库、房地产分析、招聘工具。它们提取的数据大多是商品化的或可授权的。然而,它们却能获得溢价。
为什么?因为界面就是护城河。
垂直软件中的界面护城河
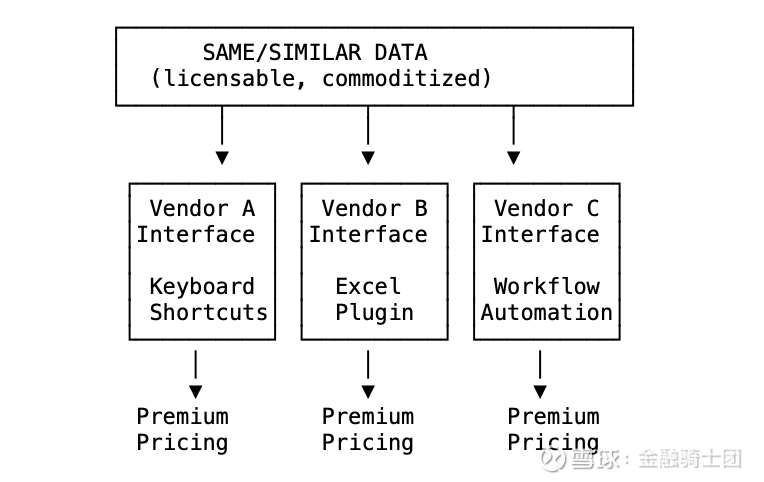
同样的数据。不同的界面。溢价。
知识工作者花费多年时间学习专业界面。这种肌肉记忆是真实存在的。他们支付费用不是为了数据,而是为了不必重新学习一套他们已经花了十年时间才掌握的工作流程。
公司围绕特定的插件构建了硬编码的模型和流程。更换供应商意味着重建工作流、重新培训团队,并承担过渡期间出错的风险。
转换成本不在于数据,而在于界面。
这就是为什么垂直软件的交易价格能达到市盈率的 20 到 30 倍。市场相信界面是具有防御性的。
但现在还是这样吗?
LLMs:终极聚合器
LLMs 不仅仅是聚合供应商。它们还吸收了界面本身。
当 LLMs 将界面商品化后,还剩下什么?只剩下数据。到那时,就是 API 对阵 API。纯粹的商品化竞争。
三层结构的崩塌:

结构性变化:
可见性的崩塌
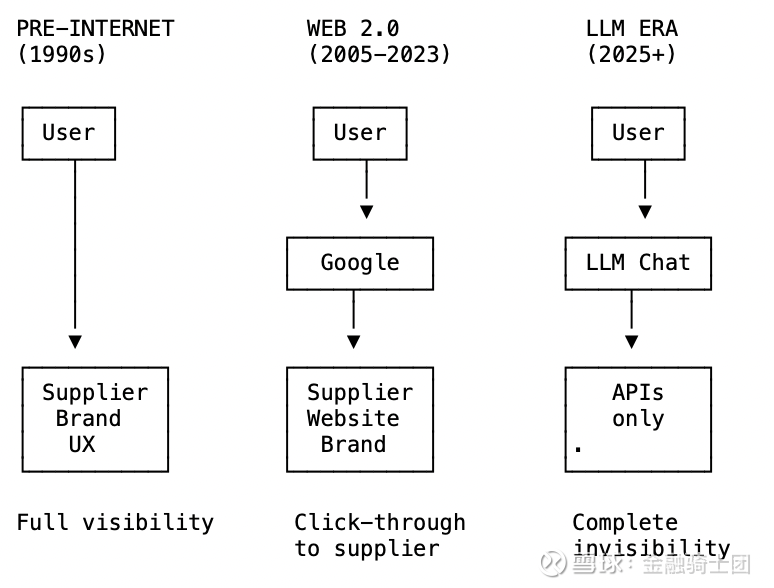
- 用户永远看不到供应商的品牌
- 用户永远无法体验到供应商的 UX
- 用户不知道信息的来源
- 整个互联网变成了一个后端数据库
现在考虑一个使用 LLM 聊天的知识工作者:
“帮我找出所有市值超过 10 亿美元、市盈率低于 30 倍、且营收同比增长超过 20% 的软件公司。”
“为排名前 5 的公司建立 DCF 模型。”
“对折现率进行敏感性分析。”
用户从未接触过任何专业界面。他们不知道(也不在乎)LLM 查询了哪个数据提供商。LLM 自动找到了覆盖范围足够且价格最便宜的数据源。
这是彻底的商品化。不仅是发现环节的商品化,而是整个供应商体验的商品化。
当界面被商品化后,剩下的就只有 API 与 API 之间的竞争。
隐形供应商的经济学
当界面消失时,定价权会发生怎样的变化:
旧模式(垂直软件):
- 1-2.5 万美元/席位/年
- 带有年度涨幅条款的多年度合同
- 95% 以上的留存率,因为切换软件意味着需要重新培训
- 毛利率 >80%
新模式:
- 数据授权费(每条查询仅需几分钱)
- 无用户锁定(LLM 可以瞬间切换数据源)
- 利润空间被压缩至商品化水平
- 留存纯粹基于数据质量和覆盖范围
现实是残酷的。
如果一家垂直软件公司的界面占据了其价值的 60%,而 LLMs 完全消除了界面的价值,那么剩下的就只有纯粹的数据价值。如果这些数据不是专有的,如果它可以被授权或复制,那么就一无所有了。
价值分解
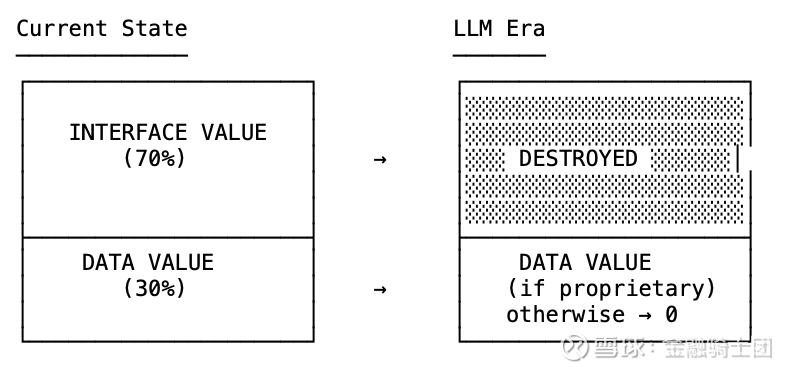
如果你没有私有数据,那你的麻烦就大了。
这是聚合理论推演至其逻辑终点的必然结果。
以金融数据软件为例。那些依靠复杂的交互界面建立起商业帝国的公司,正眼睁睁地看着自己的护城河消散。一家市值 200 亿美元、却并无真正专有数据的公司,一旦 LLMs 吸收了其界面价值,其估值就应降至 50 亿到 80 亿美元。这不是看空,这是数学。
同样的逻辑适用于所有由界面构成护城河的领域:
- 金融数据:那些针对基本同质化的数据源、仅凭界面就每年收取 1.2 万至 2.4 万美元费用的终端。当 LLM 可以直接查询相同的数据时,界面的溢价便不复存在。
- 法律研究:这些平台对基于大多属于公共领域的判例法界面收取高昂费用。当 LLM 能做得更好时,那些专业的搜索和引用工具就变得毫无价值了。
- 医学数据库:向医生收取临床决策支持工具费用的即时诊疗建议。这正是 LLMs 所擅长的。
- 房地产分析:通过专业工作流工具访问的综合数据库。LLMs 通过 API 查询相同的数据,消除了工作流的锁定效应。
- 招聘:每年收费 1 万美元以上的搜索和外联工具。当 LLM 能够查询职业网络并起草个性化外联内容时,界面的价值就消失了。
- 唯一的幸存者:拥有无法被复制或授权的真正专有数据的公司。
从软件到 API:新的供应商技术栈
如果界面变得无关紧要,供应商需要什么?
旧的技术栈:
- 前端框架 (React, Vue)
- 设计系统 (组件库)
- 用户体验研究 (用户测试、A/B 测试)
- 品牌营销 (差异化)
- SEO 优化(Google 搜索发现)
新一代技术栈:
- 清晰、结构化的数据(Markdown、JSON)
- API/MCP 端点(机器可访问性)
- 数据质量监控(准确性、新鲜度)
仅此而已。所有软件都将变成 API。
如今,一家餐厅会投资建设一个精美的网站,配备视差滚动效果、专业的食物摄影、集成的预订系统、评论管理以及本地 SEO。这一切都是为了吸引人类点击“立即预订”。
在 LLM 时代,一家餐厅需要的是:
这就是 LLM 所需的一切。那个价值 5 万美元的网站变成了一个文本文件和一个 API 端点。
垂直软件精美的界面变成了:
MCP 端点:/query 参数:{filters, fields, format} 返回:[结构化数据]
无需学习快捷键。无需安装插件。无需构建界面。只有数据,通过 API 即可访问。
MCP:完成聚合的协议
传统的 REST API 存在结构性限制,从而保留了转换成本:
- 要求精确字段名称的刚性模式
- 人类必须阅读的大量文档
- 为每项服务定制的集成
- 没有对话上下文的无状态交互
这形成了一道护城河:集成成本。即便数据已经商品化,切换 API 的成本依然不容小觑。必须有人编写新代码、测试边缘情况,并以不同的方式处理错误。
MCP 改变了这一点。
模型上下文协议(Model Context Protocol)消除了集成摩擦:

当在不同数据源之间切换无需任何集成工作时,唯一的差异化因素就只剩下数据的质量、覆盖范围和价格。
这是真正的商品化竞争。
切换成本的崩溃

新的聚合框架
针对 LLM 时代重新构建汤普森模型:
聚合理论的演进
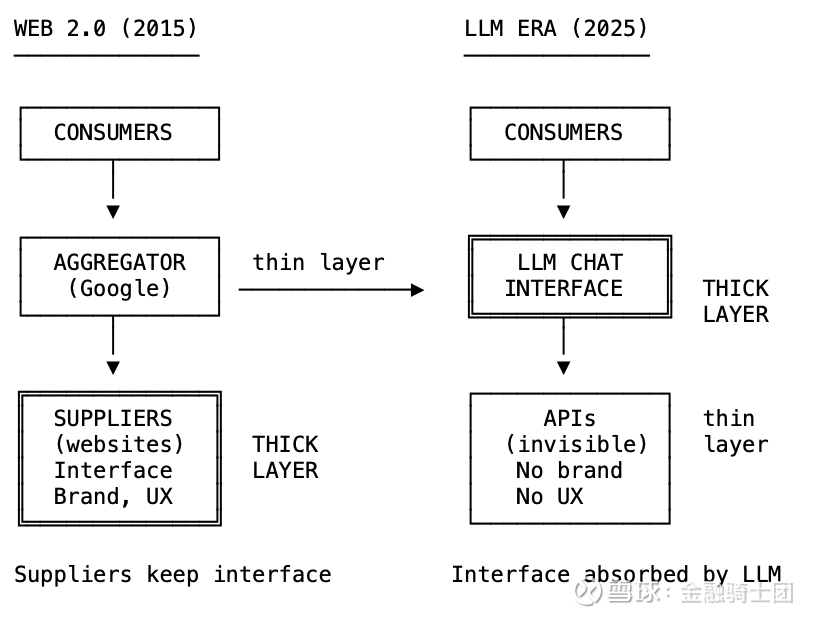
原始聚合理论(2015年):
供应商 → [聚合者] → 消费者
聚合者(如 Google/Facebook)实现了零分销成本和零交易成本,并将供应商商品化。但供应商保留了他们的界面和数据。
LLM 聚合理论 (2025):
API → [LLM 聊天] → 消费者
LLM 实现了零分发成本、零交易成本以及零界面成本。供应商完全隐形化。剩下的只是 API 与 API 之间的竞争。
聚合层变得越来越厚,而供应商层则变得越来越薄。
在 Web 2.0 时代,Google 是一个薄薄的路由层。它将你引导至供应商,一旦你点击进入,供应商就拥有了你的注意力。供应商掌握着客户关系,拥有交互界面,并完成最终转化。
在 LLM 时代,对话框占据了你所有的交互。供应商变成了隐形的基础设施。你不知道信息来自何处,无法体验他们的品牌,也永远看不到他们的界面。
2020 年的垂直软件:掌控工作流的产品。
2030 年的垂直软件:供 LLM 调用的 API。
护城河从来不是数据,而是知识工作者每天在这些界面中停留 10 小时。而现在,那个界面存在于 LLM 的对话框之中。
胜者与败者:一个框架
新价值矩阵
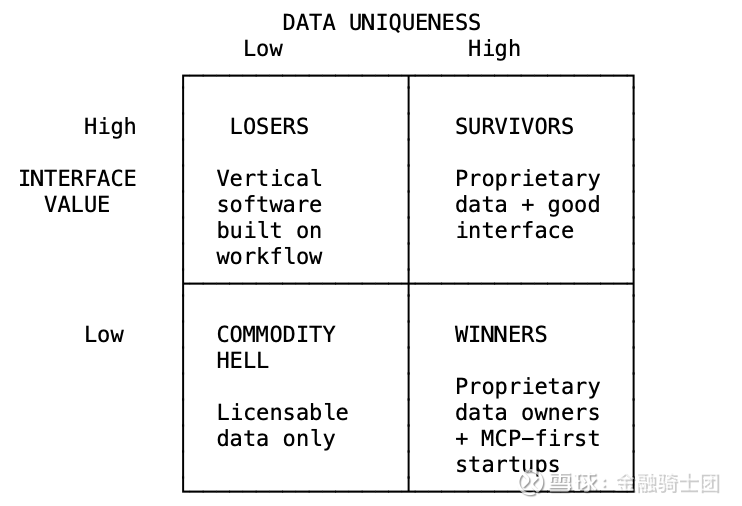
赢家:
LLM 聊天界面所有者:谁拥有聊天界面,谁就拥有用户关系。OpenAI 拥有 ChatGPT。Anthropic 拥有 Claude。微软拥有 Copilot。谷歌拥有 Gemini。它们夺取了垂直软件所失去的界面价值。它们是新一代的聚合者。
专有数据所有者:拥有真正独特、不可复制数据的公司。关键测试标准:这些数据是否可以被授权或抓取?如果可以,则不具备防御性;如果不可以,你就能生存。
MCP 优先的初创公司:为智能体而非人类而构建的公司。没有需要保护的遗留界面,没有需要维护的美观 UI。只有通过 MCP 端点提供的、可供 LLMs 查询的干净数据。由于没有需要回收的界面投资成本,它们可以在价格上击败现有的老牌企业。
输家:
界面护城河型业务:任何以“工作流”为价值核心的垂直软件。支撑溢价的界面变得毫无价值。一家估值 200 亿美元但没有专有数据的公司,其估值将缩水至 50-80 亿美元。
传统聚合者(可能):谷歌和 Meta 使供应商商品化。现在 LLMs 可能会使这些聚合者商品化。但这里有一个微妙之处:只有当他们未能掌控 LLM 聊天层时,这种情况才会发生。谷歌拥有 Gemini 和极强的分发能力。Meta 拥有 Llama。竞赛已经开始。如果他们赢得了聊天界面,他们就依然是聚合者;如果输了,他们就会沦为被商品化的对象。
内容创作者:当 AI 生成个性化内容时,UGC 平台将失去关联性。创作者经济发生反转:AI 内容无限化,大多数应用场景不再需要人类创作者。
UI/UX 行业:当 LLM 对话成为唯一界面时,精美的界面将变得无关紧要。每年数千亿美元投入到前端开发中……是为了什么?Figma(非常棒的产品!)估值下降了 90%。
对估值的影响
对界面业务重新定价的框架很简单:
业务中界面与数据的占比各是多少?大多数垂直软件 60-80% 是界面,20-40% 是数据。当 LLMs 吸收了界面,那部分价值就会蒸发。
数据是否真正具有专有性?如果数据可以被授权、抓取或复制,那么护城河就不复存在。剩下的只是纯粹的大宗商品化竞争。
这不是看空,这是数学。
市场尚未将此因素计入定价,因为 LLM 的能力尚新(大规模应用不足 2 年),MCP 的采用尚处于早期(不足 1 年),企业买家决策缓慢(合同期通常为 3-5 年),且既有企业仍处于否认状态。
但在我看来,重新定价即将到来。
聚合理论的终章
聚合的弧光
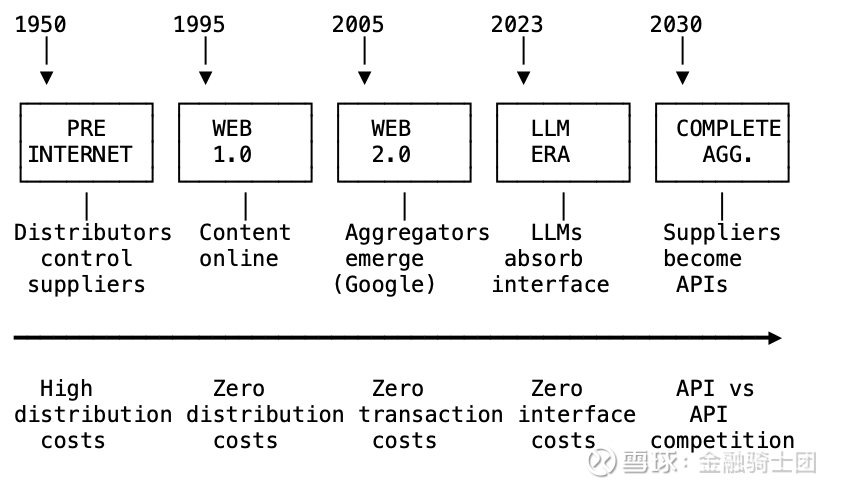
互联网经济的发展弧线:
前互联网时代(1950-1995):分销商控制供应商。高昂的分销成本产生了杠杆作用。
Web 1.0(1995-2005):分销成本骤降。内容进入网络,但仍处于孤岛状态。
Web 2.0(2005-2023):交易成本骤降。聚合者出现。供应商被商品化,但保留了各自的界面。
LLM 时代(2023 年至今):界面成本骤降。LLMs 完成了最终的聚合。供应商变成了 API。这是 API 与 API 之间的对决,谁没有私有数据,谁就会输。
汤普森(Thompson)说对的地方在于:供应商将被商品化。用户体验将变得至关重要。赢家通吃的动态将会显现。
汤普森未能预见的地方在于:界面本身将被吸收。供应商将变得隐形。聚合者将“成为”体验本身,而不仅仅是通往体验的路径。所有软件都将变成 API。
在 LLM 时代,互联网变成了一个数据库。结构化数据输入,自然语言输出。没有网站,没有界面,没有品牌。只有为 AI 提供数据的 API。
对于一个花了十年时间构建精美界面的人来说,这是一种苦乐参半的感觉。所有那些精心设计的交互、像素级的布局、工作流的优化……都过时了。
聚合理论告诉我们,供应商将被商品化。LLMs 正在完成这项工作。
界面护城河已死。剩下的只有数据。如果你的数据不是私有的,那么你的业务也不是。