谷歌向量数据空间技术对存储市场及AI价值链的重构深度分析

核心逻辑:谷歌TurboQuant等向量数据空间技术并非存储需求的“终结者”,而是AI推理成本曲线的“重塑者”。该技术通过极致压缩显存占用,将加速AI应用从“算力通胀”向“Token经济”转型,在此过程中,向量数据库将从辅助工具跃升为AI Token价值链中占比30%-40%的核心定价与调度中枢。本报告将结合最新市场数据、产业实践与政策导向,深入论证这一结构性变革。

一、 向量数据空间技术:存储市场的“伪利空”与“真重构”
近期谷歌发布的TurboQuant算法,基于PolarQuant(极坐标量化)与QJL(量化Johnson-Lindenstrauss纠偏)两项核心技术,实现了KV Cache(键值缓存)的3-bit无损压缩,将显存占用降低6倍,并在英伟达H100 GPU上实现注意力计算速度最高8倍的提升。这一突破引发美股存储板块(如美光科技、西部数据)当日下跌2%-6%的市场恐慌。然而,深入分析揭示其真实影响在于需求结构的迁移与总需求的放大,而非总量的萎缩。
首先,存储硬件正经历“杰文斯悖论”效应,表现为总量不减而结构分化。 TurboQuant主要作用于推理阶段的动态KV缓存,而非静态的模型权重存储。其核心是解决长上下文窗口带来的“内存墙”问题,通过算法优化降低单次推理的显存成本。然而,这并未消除存储需求,而是通过杰文斯悖论(Jevons Paradox)效应重构需求:单机存储需求下降,但AI应用门槛降低将导致部署规模指数级增长,总存储消耗量(TB级)仍将维持高位。富国银行分析师Andrew Rocha指出,该技术“直接压缩AI内存成本曲线”,但“实验室环境下的测试结果能否顺利转化为真实生产环境中的应用表现,仍存不确定性”。摩根士丹利进一步分析认为,TurboQuant仅作用于推理缓存,不影响训练所需的HBM(高带宽内存),其核心意义在于提升单GPU吞吐量,使相同硬件能支持更长的上下文或更大的批处理规模,从而激活更多受成本制约的应用场景。市场恐慌源于对高端显存(HBM)需求见顶的担忧,但技术实际推动存储需求从“极致高性能”向“高性价比、高密度”的通用存储迁移。存储市场的竞争焦点正从“卖颗粒”转向提供向量数据全生命周期管理的解决方案。
其次,向量数据空间技术实现了对传统存储架构的“降维打击”,其影响深远。 谷歌技术的关键在于其数据无感知(Data-Oblivious)特性,它无需预训练校准,通过高维空间旋转将向量压缩至信息论极限。这不仅是算法胜利,更确立了“向量”作为AI原生数据最小单位的地位。未来存储系统将不再以“文件”或“对象”为核心,而是以“向量空间”为基本架构,实现存算一体。这一变革对产业链产生直接影响:它将加速向量计算与存储的硬件协同。英伟达的GPU直连存储等新硬件架构,正推动向量数据库实现从“以DRAM为中心”到“以SSD为导向”的范式转变,旨在进一步提升检索性能并降低成本。这意味着,存储厂商必须从提供通用硬件,转向提供深度优化向量检索的智能存储解决方案,其价值将从介质本身向上游的数据处理与调度能力迁移。
产业实践印证了这一趋势。 国内领先的数据库厂商,如海量数据(603138),其核心产品Vastbase G100已前瞻性地整合了向量引擎能力,实现了关系型数据与向量数据的原生融合查询。这种“一库多模”的架构,正是应对未来向量数据空间成为主流存储范式的前瞻布局。其控股子公司数智引航发布的纯向量数据库VexDB,更是专注于高性能、多模态向量检索,支持百亿向量毫秒级查询,召回准确度稳定在99%以上,已在金融、医疗、安平等行业核心场景落地。这标志着产业界已从技术预研走向规模化应用,为向量数据空间的普及铺平了道路。
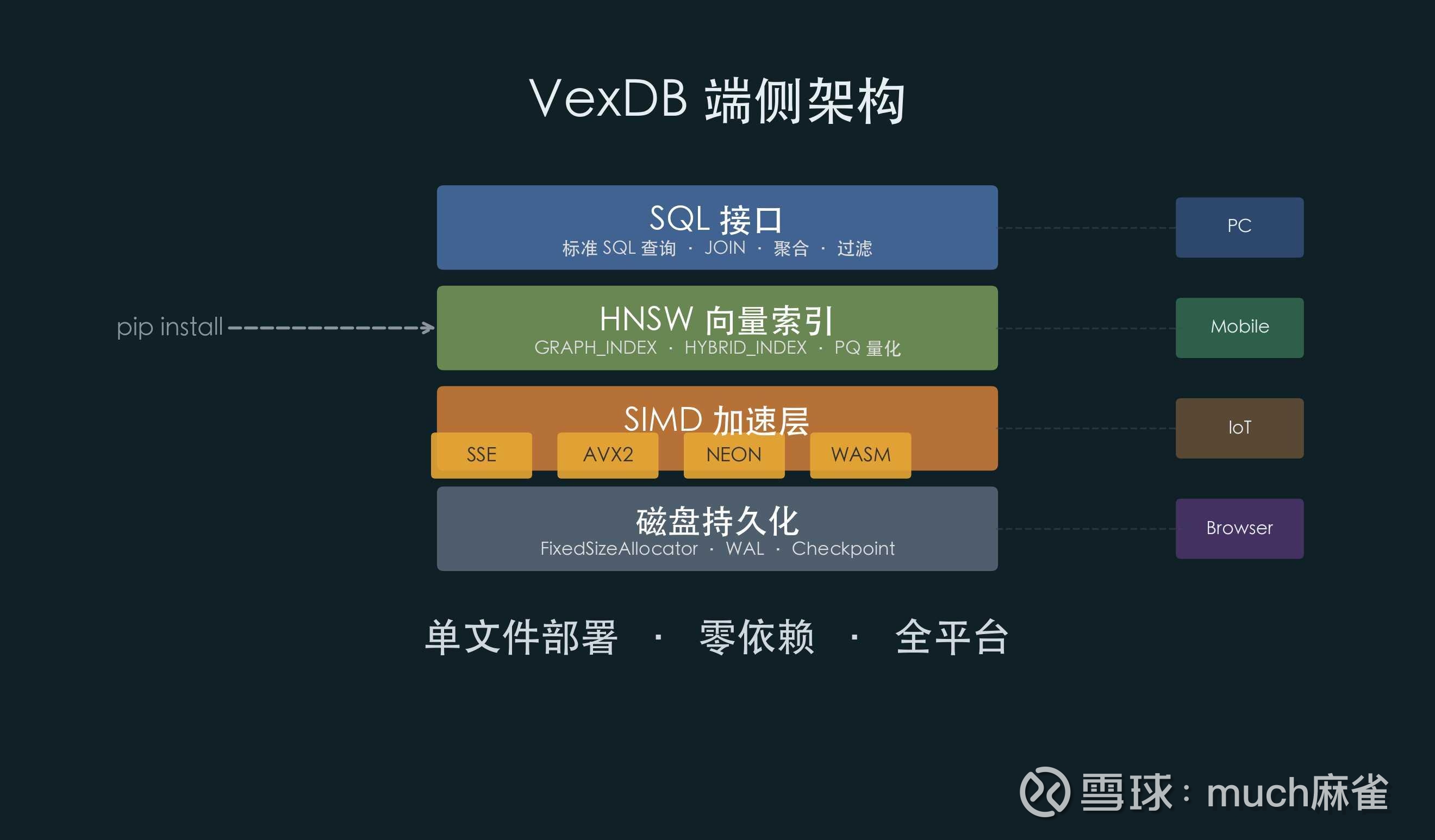
星环科技与英伟达的合作,则为“GPU-Native”向量数据库的演进提供了关键范式。 作为英伟达在全球范围内仅有的两家自研AI数据库一体机合作方之一,星环科技与英伟达中国团队的合作主要围绕“高性能计算重构”与“新一代存储架构适配”两个维度展开。其核心成果是深度重构了下一代AI原生数据库——认知数据库的计算引擎。在英伟达的支持下,该引擎深度应用了CUDA及RAPIDS等底层库函数,实现了从百级CPU线程向十万级GPU线程并发的跨越。根据最新测试数据,基于GPU加速的向量检索性能提升了20至200倍;在关系型数据库的标准TPC-DS测试中,分析性能提升了约20倍。这一合作的核心逻辑在于,通过将数据库索引从CPU内存或GPU显存卸载(offload)到闪存,并利用GPU直连SSD(GDS)技术,绕过CPU直接读取数据,实现数据从存储到GPU显存的“零拷贝”流动,从而彻底解决AI推理中GPU算力等待数据的瓶颈。这不仅是性能的飞跃,更是数据库架构从“CPU中心”转向“GPU中心”的根本性变革,为向量数据库处理海量、高并发AI请求奠定了硬件级基础。
二、 AI Agent与多模态浪潮:向量数据库需求的“超级放大器”与政策东风
2026年被业界公认为“AI Agent元年”,以开源项目OpenClaw(“龙虾”)为代表,AI正从“能说会道”的聊天模式,全面迈入“能办事落地”的主动执行新阶段。这一范式跃迁的核心标志是,模型能力评估标准从“参数越大越好”转变为“运行越高效越好”,工具调用、结构化输出、长上下文理解与复杂推理成为硬性要求。与此同时,多模态AI正从“拼接式”走向“原生全模态”,快手可灵AI等产品已实现“图生视频+主体参考”等复杂能力,将文字、图像、视频等多模态的输入与输出纳入同一模型框架。这两大趋势共同构成了向量数据库需求爆发的“超级放大器”。
AI Agent的爆发直接驱动了Token消耗量的指数级增长。 国家数据局局长刘烈宏在近期发布会上介绍,2026年3月中国日均Token调用量已突破140万亿,相比2024年初的1000亿增长了超千倍。这组数据被官方解读为“数据要素赋能人工智能创新发展已进入良性互动阶段”的标志。更为关键的是,AI Agent的任务复杂度远超传统对话。Anthropic实测数据显示,单个Agent的Token消耗量约为传统问答模式的4倍,而多Agent协作系统的消耗量则高达15倍。OpenRouter平台数据显示,多步骤推理和链式工具调用正在快速取代传统单轮交互。这种从“Prompt”到“长Agent”的交互范式跃迁,意味着AI系统需要持续运行、维护状态、并调用外部工具,其对长期记忆和上下文管理的需求呈非线性增长。
多模态技术的成熟,则从数据维度上极大丰富了向量数据库的处理对象与价值内涵。 传统的向量数据库主要处理文本嵌入(Embedding)。然而,随着原生多模态大模型的普及,图像、音频、视频乃至3D点云等非结构化数据,都需要被统一编码为高维向量进行存储、检索与关联分析。例如,在智能座舱场景中,AI助手需要同时理解用户的语音指令(音频向量)、车内摄像头捕捉的驾驶员状态(图像向量)以及导航地图信息(空间向量),并从中提取跨模态的语义关联。这要求向量数据库必须具备处理异构、高维、跨模态向量的能力,其技术门槛与价值密度同步提升。数智引航的VexDB产品正是瞄准了这一痛点,其设计初衷即为高效管理和释放非结构化数据价值,重塑AI应用边界。
国家层面的政策导向与可信数据空间的建设,为这一技术演进提供了强劲的“东风”与合规框架。 国家数据局已将2026年明确为“数据要素价值释放年”,并形成了数据要素市场化配置改革“5+3+1”工作体系,其中突出“数据赋能人工智能创新发展”这一重点。政策层面正大力推动高质量数据集建设,截至2025年底,全国已建成高质量数据集超10万个,总体量超890PB。这些数据集正是训练和驱动多模态AI Agent的“燃料”,而向量数据库则是高效组织、管理和调用这些“燃料”的“智能仓库”。在此背景下,太极可信数据空间作为国内数据要素流通的关键基础设施,其行业格局与战略意义凸显。太极股份的“可信数据空间平台V2.0”是国内首个通过中国信通院《数据空间平台能力专项测试》的产品,被纳入国家数据局《可信数据空间发展行动计划(2024–2028)》的重点支持方向。该平台融合了隐私计算、区块链、智能合约、分布式数字身份等多项关键技术,旨在构建安全、可信、高效的数据流通环境。根据赛迪发布的《2025可信数据空间建设与产业发展报告》,市场已形成“三类四级”的竞争格局,太极股份与中国电子云、零数科技、中国移动、浪潮云等一同位列“领导者象限”。其核心价值在于,为跨组织、跨域的数据协作提供了“可用不可见、可控可计量”的信任基础。某试点城市采用V2.0平台后,政务数据开放效率提升50%,企业数据协作成本降低35%。这为向量数据库在合规、安全的前提下,服务于更广泛的产业AI应用扫清了制度障碍,使其从技术工具升级为数据要素市场化流通的核心组件。
在此背景下,向量数据库的角色发生了根本性转变。它不再是简单的“外挂知识库”,而是进化为AI Agent的“海马体”与“工作记忆中枢”。一个典型的AI Agent长期记忆系统,如基于Mem0框架的架构,其核心正是向量数据库与图数据库的混合引擎。该系统通过向量数据库高效存储和检索对话历史、用户偏好等语义信息(情景记忆),同时利用图数据库构建实体间的复杂关系网络(语义记忆)。阿里云、腾讯云等厂商已推出基于PolarDB等数据库的一站式AI Agent长记忆解决方案,将向量检索、图关系推理与模型服务深度集成。
一个值得关注的颠覆性趋势是,以Supermemory团队为代表的研究正探索用“多智能体协作系统”完全替代传统向量检索。该方案在LongMemEval基准测试上达到了99%的准确率,其核心是用多个并行搜索Agent(如事实搜索、语境挖掘、时间线重建Agent)通过“认知理解”主动推理来回忆信息,而非依赖向量余弦计算的“数学相似度”。这套纯Agent架构理论上可以嵌入任何设备,包括机器人。这揭示了向量数据库未来可能面临的技术路径竞争:纯粹的向量相似性检索可能被更高级的、具备推理能力的Agentic检索所部分替代或增强。然而,这并非向量数据库的终结,而是其价值层级的跃升——从提供基础的相似性匹配服务,升级为支撑复杂Agentic记忆与推理系统的核心数据基础设施层。未来的向量数据库可能需要深度集成轻量级推理引擎,以支持更智能的检索策略。这也与北京数据智能实验室等前沿研究机构的方向不谋而合,该实验室由清华大学、海量数据与清华工研院联合共建,其三大核心研究方向之一便是“自主数据科学系统(Agentic Data Science System)”,旨在突破多模态数据的自动融合、编排、分析技术,打造AI数据科学系统。这预示着产业界与学术界正共同推动向量数据库向更智能、更自主的“AI原生数据库”演进。

三、 向量数据库在AI Token价值链的“中枢地位”前景:详实数据与深度逻辑论证
在AI从“内容生成”向“Agentic AI(智能体)”演进的2026年,Token(调用量)已成为核心计价单位。阿里巴巴集团CEO吴泳铭指出,Token“并不是IT预算,而是成为生产资料的一部分”。向量数据库在此爆炸式增长且结构剧变的价值链中,地位正发生根本性跃迁,其演进可清晰划分为三个阶段。
第一阶段(2023-2025):RAG辅助阶段。 此阶段核心驱动力是知识库扩展与防幻觉,向量数据库主要作为检索增强工具。其价值占比约为5%-10%,属于必要的成本项。2024年,向量数据库在智能搜索、RAG场景的应用占比已超过70%,标志着其作为大模型“外脑”的初步价值得到确认。
第二阶段(2026-2027):Agent记忆中枢与多模态枢纽阶段。 核心驱动力转向支持智能体的长上下文、多轮决策、状态持久化以及处理海量多模态数据。向量数据库的角色进化为记忆中枢(海马体)与多模态数据统一处理平台,成为Agent实现连续性、个性化与跨模态理解的必选项,价值占比跃升至20%-30%。全球向量数据库(VaaS)市场规模预计将从2024年的22亿美元增长至2031年的164亿美元,年复合增长率(CAGR)高达28.27%。在中国市场,这一趋势更为迅猛,2025年市场规模已突破80亿元,同比增速超120%,预计2026年将达到150-180亿元。
第三阶段(2028及以后):Token经济调度与价值分配中枢阶段。 核心驱动力是应对由AI Agent和多模态应用驱动的万亿级调用、实现全局成本最优与价值调度。此时,向量数据库将超越工具属性,成为Token流量调度、多模态理解与价值定价的核心引擎,占据价值链30%-40%的核心中枢地位。其价值不再仅源于存储与检索,更源于对AI计算资源的优化配置、对跨模态语义的统一理解,以及对Token价值的决定性影响。
支撑这一前景的,是少数人洞见的三大隐性逻辑。
逻辑一:从“成本中心”到“利润杠杆”的质变——效率即利润。 传统视角将向量数据库视为存储成本,但Agent时代其核心价值在于Token级调度效率。通过高精度向量检索,RAG可将大模型不必要的推理算力消耗降低30%-70%。在固定算力预算下,这意味着向量数据库的检索精度直接决定了可售Token数量。行业实测数据表明,将专用向量数据库(如Milvus)替代传统方案(如PostgreSQL pgvector),可使千万级向量查询延迟从2秒降至80毫秒(提升25倍),同时总体拥有成本(TCO)降低40%。因此,向量数据库正从一个成本项,质变为营收扩增器与核心利润杠杆。
逻辑二:向量数据库是应对“模型遗忘”与实现“多模态统一理解”的基石。 大模型固有的“灾难性遗忘”缺陷,使其难以持续记忆个性化信息。向量数据库作为永久、可追溯的外部记忆体,完美地弥补了这一短板。它能够存储用户画像、历史交互与工具调用结果,形成持续进化的用户状态向量。当AI进入多模态交互时代,向量数据库通过跨模态检索(融合文本、图像、音频、行为序列)构建了用户状态的完整向量化映射,成为比瞬时模型权重更稳定、更个性化的“数字灵魂”载体。Gartner预测,到2026年,超过30%的企业将采用向量数据库为其基础模型提供相关业务数据。这使其战略价值已远超单纯的数据存储。
逻辑三:Token定价的“隐形操盘手”与价值链占比的必然跃升。 未来的AI服务计价将日益精细化,按“有效Token”(即产生实际业务价值的调用)计价成为趋势。向量数据库通过召回质量、响应速度、多模态关联度与上下文理解深度,直接决定了单次调用的“有效利用率”和用户体验。低延迟、高精度的检索能极大减少模型“空转”与无效计算,从而显著提升单Token的ARPU(每用户平均收入)。在AI推理的总成本构成中,算力与电力是主要硬性成本,而向量数据库通过优化整体效率,实质上深度参与了最终Token的价值创造与分配。随着Token经济规模急剧膨胀——摩根大通预测中国AI推理Token消耗量在2025-2030年间将增长约370倍——作为关键效率优化与价值调度工具的向量数据库,其在整个价值链中的价值占比必然向30%-40% 的核心区间收敛。

四、 未来格局定论:向量数据库作为“AI的第四基础设施”
随着谷歌等巨头将向量技术基础设施化,向量数据库将不再是一个独立的软件品类,而是与算力(GPU)、模型(LLM)、网络(带宽)并列的第四大AI基础设施,其发展呈现三大明确趋势。
其一,与算力层的深度融合达到硬件级协同,并支撑Agentic计算范式。 向量数据库的核心索引算法(如HNSW、IVF)正与GPU、NVMe SSD等硬件深度结合,走向“近存计算”范式。例如,通过英伟达GPU的Tensor Core对向量运算进行加速,Milvus等数据库已可实现万亿向量级别的毫秒级搜索。这种硬件协同将使向量检索延迟进入微秒级,从而成为AI推理管道中不可或缺的“默认配置”,而非外挂的可选组件。同时,为应对Supermemory等纯Agent记忆方案的挑战,下一代向量数据库将深度集成轻量级推理与规划能力,从被动检索进化为具备初步认知能力的主动记忆管理系统。这正呼应了北京数据智能实验室关于“AI原生数据库”和“自主数据科学系统”的研究方向,旨在突破非结构化数据统一建模和语义推理分析技术,实现从结构化数据到非结构化智能管理的跨越。
其二,成为多模态AI时代的数据主权守门人与信创体系的核心。 在全球数据隐私与合规监管日益严格的背景下,向量数据库作为企业私有数据的“向量化封装层”与安全沙箱,将成为数据不出域前提下连接外部公有大模型与内部私有知识的唯一合规桥梁。国家数据局等六部委联合印发的《关于完善数据流通安全治理 更好促进数据要素市场化价值化的实施方案》等政策,正着力构建安全可控的数据流通治理体系。在中国信创(信息技术应用创新)领域,国产向量数据库(如海量数据的Vastbase G100、数智引航的VexDB)正与国产算力(如昇腾、海光)构成“硬件+软件+生态”的自主闭环,在政务、金融、央企等核心场景加速替代进口方案。其战略地位已堪比操作系统,是保障国家数据安全与产业自主可控的关键一环。与此同时,以华胜天成为代表的系统集成与算力服务商,正通过其“AI+算力+场景”战略,为企业提供从智算中心建设到AI应用落地的全栈服务。其推出的基于DeepSeek、华为昇腾等国产技术的智能体一体机方案,正是将向量数据库等AI基础设施与国产算力硬件、大模型进行深度融合打包交付的典型实践。而数据港等专业数据中心服务商,则通过提供高可靠、高能效的数据中心基础设施,为向量数据库及整个AI算力生态的稳定运行提供物理承载保障,构成了从底层算力设施到上层AI应用的全产业链支撑。
其三,技术边界持续扩展,从检索工具演化为AI原生数据平台与Agent记忆系统。 主流的向量数据库正迅速超越单一的相似性搜索功能,向支持标量与向量的混合复杂查询、统一处理多模态数据(文本、图像、音频、视频嵌入)的AI原生数据平台演进。更重要的是,它们正在成为构建AI Agent长期记忆系统的核心组件。通过结合图数据库(如Neo4j, Apache AGE)来存储实体关系,向量数据库能够为Agent提供不仅基于语义相似性,还能基于逻辑关联性的记忆检索,从而支撑更复杂的推理与规划任务。这标志着其正从“检索工具”进化为“承载智能体记忆、知识与状态的统一数据智能底座”。正如北京数据智能实验室所聚焦的“可信数据空间”研究方向,旨在突破高质量数据集构建、数据价值评估与安全可信流通方法,这正是未来向量数据库作为数据要素流通核心枢纽所必须攻克的技术堡垒。

观点:谷歌的TurboQuant向量数据空间技术不仅是一项压缩算法,更吹响了AI数据架构范式革命的号角。它非但不会扼杀存储市场,反而会通过催生面向向量计算的智能存储新生态,彻底淘汰“裸存储”的旧有商业模式。在即将到来的、由AI Agent与多模态应用驱动的AI Token经济体系中,向量数据库将凭借其记忆持久化、多模态统一理解、流量高效调度与价值定价四位一体的核心能力,占据价值链的核心权重。根据QYResearch的预测,其全球市场将以28.27%的复合年增长率迈向2031年的164亿美元,成为比模型本身更持久、更确定的复利资产与数字基石。面对Agentic检索等新兴技术的挑战,向量数据库的进化方向不是被取代,而是升维——从数学相似性的提供者,进化为支撑智能体认知与决策的记忆与理解基础设施。在国家数据要素市场化改革与“人工智能+”行动的双重驱动下,以海量数据Vastbase、数智引航VexDB为代表的国产向量数据库,正依托产学研协同(如与清华大学共建的数据智能北京市重点实验室)加速技术攻坚与产业落地,有望在构建自主可控的AI数据底座征程中,扮演不可或缺的关键角色。而星环科技与英伟达在GPU-Native数据库上的深度合作、太极股份在可信数据空间领域的领导者地位,以及华胜天成、数据港等企业在算力基础设施与场景化落地上的布局,共同勾勒出一幅从底层硬件、数据流通平台到上层应用服务的完整AI基础设施产业图谱,预示着向量数据库将在其中发挥承上启下的核心枢纽作用。