砺算GPU的真实概况

一、GPU技术壁垒:全栈自研的稀缺性#东芯股份# #市值5000亿!寒武纪再创新高#
1. IP核研发的全球格局
顶尖玩家仅6家:全球具备全栈GPU IP核设计能力的企业仅英伟达、AMD、英特尔、高通、ARM、Imagination(IMG)及砺算科技。其中:
高性能图形GPU:英伟达(Ampere/Ada架构)、AMD(RDNA架构)、砺算(TrueGPU天图架构) 具备完整渲染管线与顶点处理能力,可支持4K游戏、实时光追等复杂场景。
低功耗领域:高通(Adreno)、ARM(Mali)、IMG(B系列)专注于移动端精简架构,性能受限。
- 技术断层明显:华为(马良GPU)基于IMG旧架构魔改,寒武纪、沐曦等国产厂商依赖授权IP或聚焦专用计算(如AI训练),缺乏图形渲染管线自主权,导致游戏兼容性与驱动优化不足。
2. 渲染管线与顶点算法的技术门槛
- 图形管线复杂性:现代GPU需完整实现顶点着色、光栅化、纹理贴图、输出合并等固定+可编程管线,并支持DX12/Vulkan等先进API。英伟达凭借CUDA生态(编译器、驱动、库)形成闭环,而国产厂商中仅砺算通过自研软件栈实现DX12完整支持。
- 顶点驱动算法瓶颈:高精度实时渲染依赖并行顶点处理能力(如每秒亿级三角形生成),需专用硬件单元(如Tessellator)与高带宽显存(砺算7G106显存带宽384GB/s,景嘉微仅89.6GB/s)。
二、国产GPU破局者:砺算的核心优势
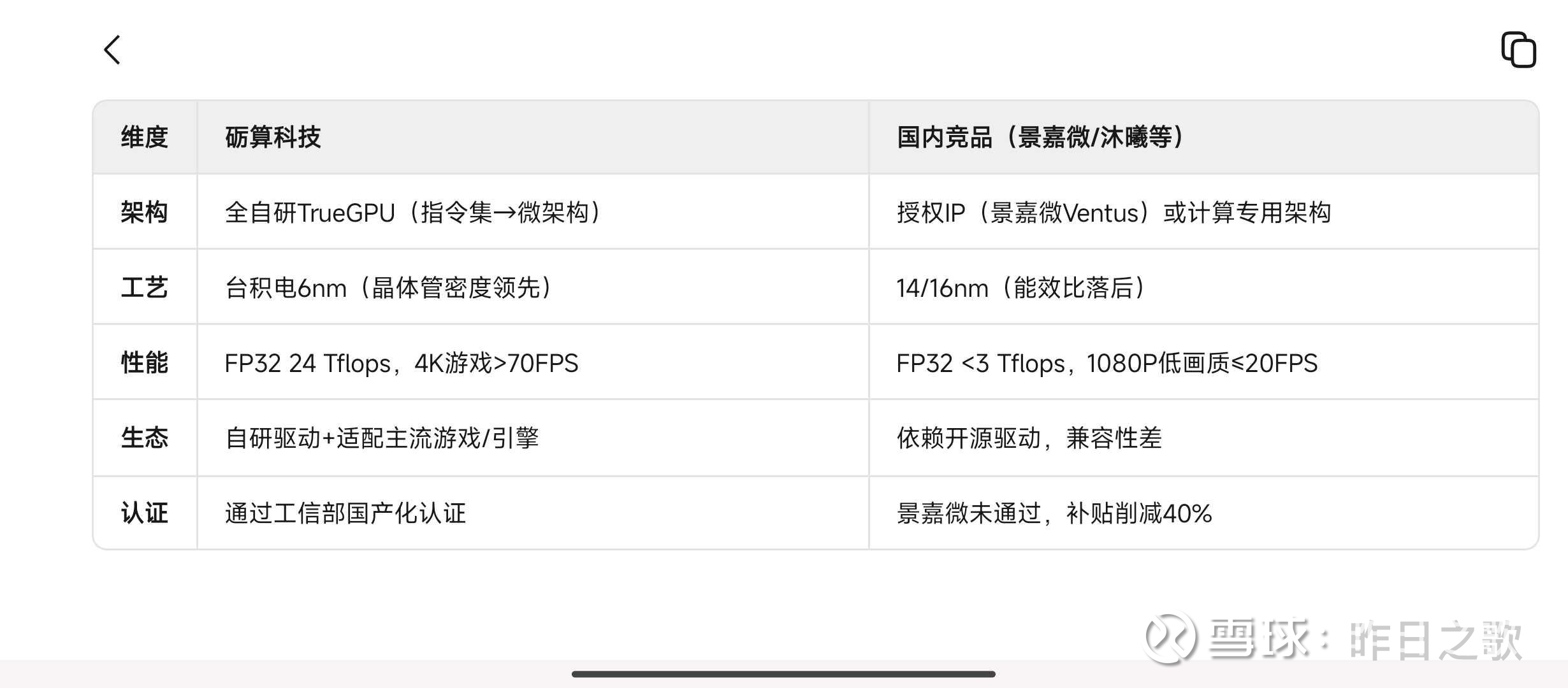
维度 砺算科技 国内竞品(景嘉微/沐曦等)
架构 全自研TrueGPU(指令集→微架构) 授权IP(景嘉微Ventus)或计算专用架构
工艺 台积电6nm(晶体管密度领先) 14/16nm(能效比落后)
性能 FP32 24 Tflops,4K游戏>70FPS FP32 <3 Tflops,1080P低画质≤20FPS
生态 自研驱动+适配主流游戏/引擎 依赖开源驱动,兼容性差
认证 通过工信部国产化认证 景嘉微未通过,补贴削减40%
- 技术自主性验证:砺算7G106实测支持《黑神话:悟空》4K高画质渲染,性能达RTX 4060级别,而景嘉微同场景帧率仅17 FPS,凸显图形管线能力代差。
- AI与图形融合:砺算在Llama3训练效率(7240 samples/sec)接近RTX 3090,证明其通用计算架构可同时支撑图形与AI场景,突破国产GPU“专用化”局限。
三、国产替代路径:政策与消费市场的双轮驱动
1. 政策端强制替代
- 安全审查加码:英特尔/英伟达芯片因“安全后门”问题被排除于政府、国企、高校采购清单,2025年国产GPU在信创市场渗透率已超35%。
- 千亿替代空间:中国GPU市场规模2025年达1200亿元,其中消费级(PC/游戏)占比40%,此前几乎被海外垄断,现为砺算等企业打开窗口。
2. 消费市场反馈闭环的关键性
- 失败案例警示:摩尔线程消费卡因IP授权性能不足(无法通过工信部认证)且缺乏游戏厂商适配,退出消费市场,证明IP魔改模式不可持续。
- 砺算的破局点:通过消费端真实场景(如4K游戏、AIPC)积累用户数据→驱动驱动优化→反哺架构迭代,形成“技术-市场”正循环。若送测量产顺利,有望复制京东方从替代者到全球龙头的路径。
四、东芯股份的投资逻辑:低估值的黄金赛道入口
- 股权价值重估:东芯持有砺算37.87%股权,若未来和美国冲突进一步升温,砺算取得国内和反美、中立国家的GPU市场70%份额(年销400万张卡),股权价值约1.9万亿亿元(现东芯市值仅四百亿元)。
- 爆发力催化剂:
1. 量产倒计时:2025年8月送样→9月量产,订单已超1亿元(政府智算中心+AIPC厂商)。
2. 国产替代加速度:美国限制高端AI芯片出口,国产算力缺口扩大,政策订单向砺算等自研企业倾斜。
结论:技术稀缺性与市场错配的机遇
砺算作为全球唯六、中国唯一的高性能图形GPU全栈自研企业,其IP核设计能力已突破“卡脖子”环节。而东芯股份凭借37.87%持股成为稀缺投资通道,现股价未反映砺算量产及国产替代预期。一旦技术验证通过,消费市场反哺生态的飞轮启动,估值重构空间远超当前市场认知。