即梦——砺算专业卡真正的舞台

当字节跳动旗下的即梦 AI火爆全网,我们不仅看到了视频文娱行业被颠覆的可能,更让我们重新审视 GPU 的价值。它不再是游戏玩家的专属,也不仅是 AI 大模型训练的工具,而是视频创作全链路的核心生产力。过去东芯的股民更多看到砺算的展示都是在游戏层面,毕竟打个黑猴大家都看得懂,你能玩别人家显卡玩不了,很容易就普及开来了。但如果认为砺算显卡的功能仅仅停留在打黑猴,那就太小看这帮奋斗了30年的图形显卡OG了。
不少用户通过这几天的使用都感慨,即梦 “挺费钱”,即便是财大气粗的字节跳动,也只提供了三次免费体验。这背后的原因很简单:它所消耗的算力,不仅仅是通用计算算力,还需要图形管线的算力。
与当前主流的大语言模型不同,即梦这类 AI 视频生成工具,其核心是对连续帧进行高维时空建模。这不仅需要处理海量的像素数据,更要保证光影、运镜、人物一致性等视觉效果的真实可信。这种对图形渲染和物理规律的深度模拟,所消耗的算力,远超当前所有文本大模型。这也解释了为什么很多Asic芯片、纯 GPGPU(通用计算 GPU)无法完全胜任即梦的工作。这些芯片虽然在 AI 训练和推理中表现出色,但它们剥离了图形管线,缺乏处理复杂视觉效果的能力。对于个人工作者而言,即梦做出的视频通常是5s或15s,在视频生成完之后,还需要导入AE或PR等其他专业视频软件剪辑或添加特效,这个过程中90%以上的操作,都依赖图形管线的实时硬加速。如果图形管线性能不足,整个编辑过程会寸步难行,哪怕最终导出算力再高,也无法提升核心工作效率。
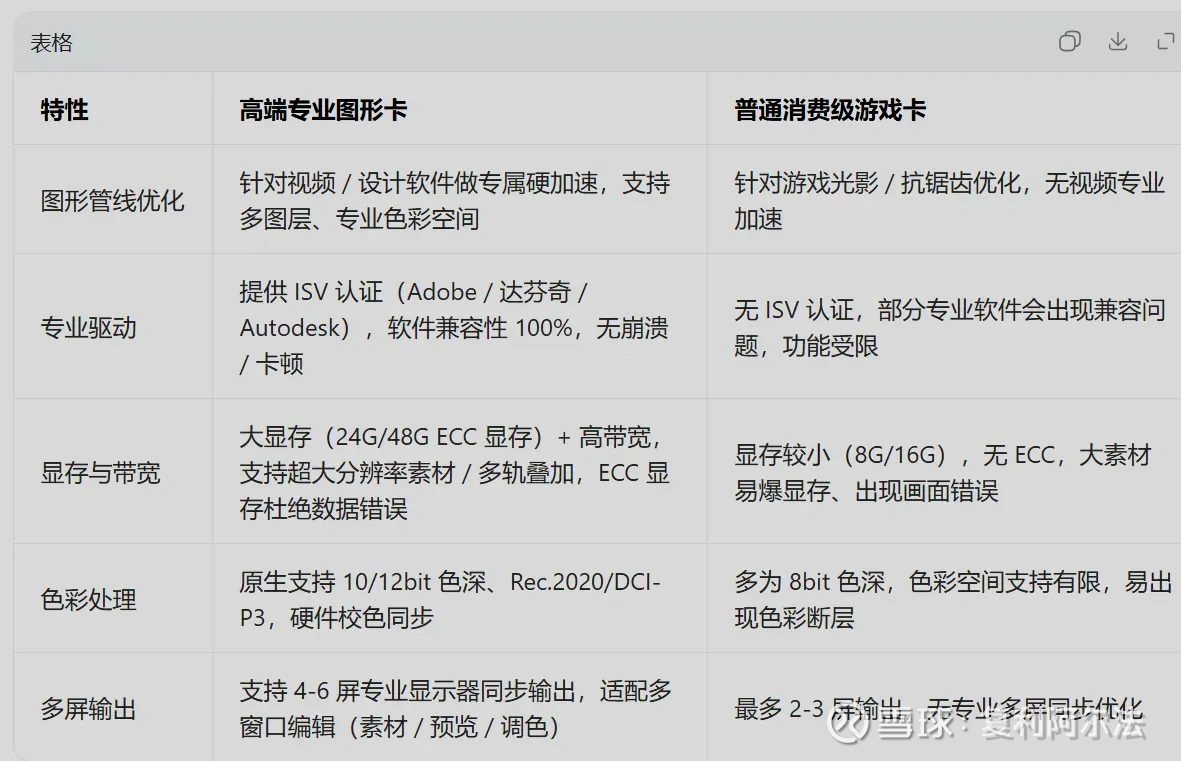
在过去,专业图形 GPU(如 NVIDIA RTX A 系列、AMD Radeon Pro)更多被视为影视后期、工业设计等领域的 “幕后英雄”。它们凭借强大的图形管线、大显存和专业驱动,支撑着实时预览、多轨合成和复杂特效渲染。
而即梦的出现,将专业图形 GPU 推到了舞台中央。它的价值体现在三个层面:
生成端的算力底座:即梦在云端的大规模部署,依赖的是具备完整图形能力的专业 GPU 集群。这些 GPU 不仅能提供强大的 AI 算力,更能通过图形管线实时渲染出电影级的视觉效果,确保生成视频的质感。当然这一过程ASIC和GPGPU也能胜任,并不是说缺了图形能力就不能生成。
编辑端的流畅保障:在即梦生成视频后,用户往往需要在 AE、PR 等专业软件中进行二次创作。这一过程极度依赖显卡的图形管线性能和显存容量。一张 24GB 显存的 RTX A5000,能比 16GB 的 RTX 4080 更稳定地处理多层 4K 素材和复杂特效,避免预览卡顿和软件崩溃。
超分端的体验升级:为了让即梦生成的 1080p 视频在高清播放时更清晰,用户会使用 VSR 等 AI 超分工具。这一过程虽然主要依赖 AI 算力,但也需要图形 GPU 的硬件加速单元(如 NVENC)来保证实时性和画质。
可以通过以下这张图来厘清各个环节显卡的负载情况。
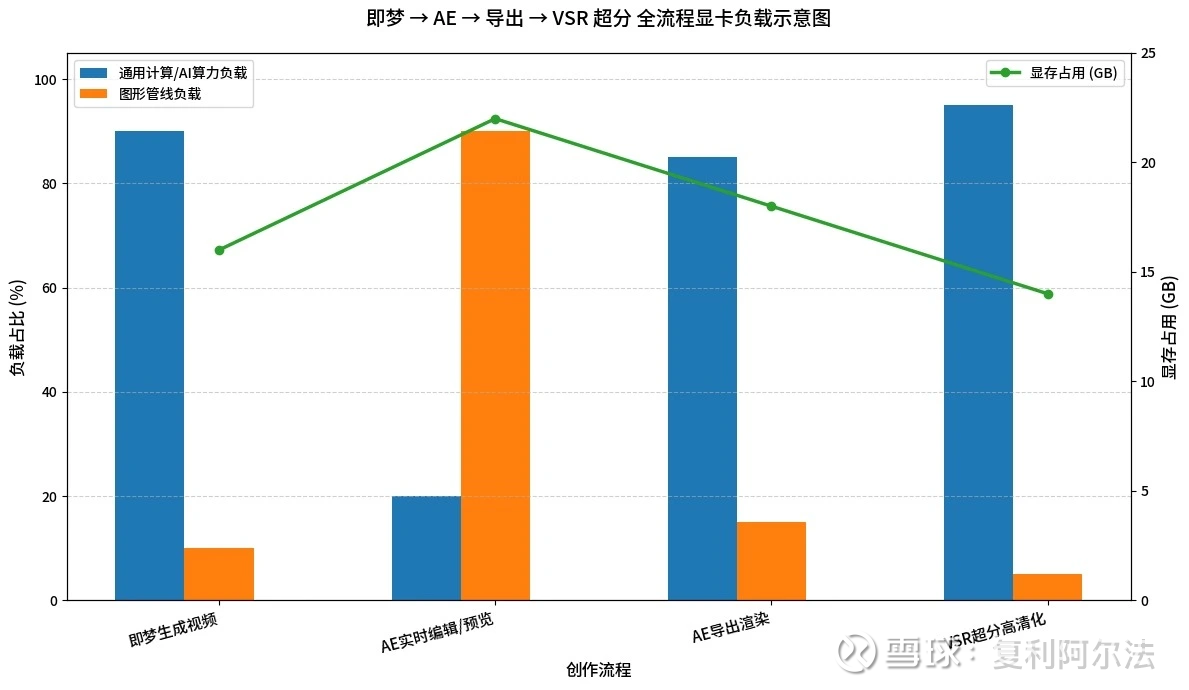
说回砺算,很多人可能还是不理解,为什么砺算同一个core要分两种规格,其核心就在关键变量显存上。对于消费卡普通用户而言,我买来就是电脑日常使用,玩几个3A游戏就可以了,如果画面卡顿,那我调低分辨率和特效就行。但专业卡的用户就不一样了,在导出4K高清视频的时候,大显存是必不可少的条件,如果显存不够,是根本没法导出视频的。而英伟达的专业卡动辄数万,所以对于个人视频工作者来说,高显存的7G105就是性价比的不二之选。
当 AI 从文本走向多模态,未来的算力竞争,将不再是单纯的 FP32 或 INT8 算力比拼,而是图形管线、显存带宽、AI 加速单元三者融合的综合实力较量,这意味着硬件选择的逻辑正在重构。即梦让我们意识到,在 AI 的下一个时代,图形计算才是真正的星辰大海。$东芯股份(SH688110)$