寒武纪发布HNLPU架构,开辟大模型时代的算力破局之路


中科院计算所与寒武纪团队发表于ASPLOS2026的重量级论文《Hardwired-NeuronsLanguageProcessingUnitsasGeneral-PurposeCognitiveSubstrates》,提出的了HNLPU(硬连线神经语言处理单元)架构。
这篇文章主要介绍了寒武纪与中科院计算所团队发布的最新架构——HNLPU硬连线神经语言处理单元,但是与较早之前寒武纪发布的HNLPU(Heterogeneous Native Local Processing Unit,异构原生局部处理单元)有所不同。
二者有关联,但是也有不一样,不要搞混了。前者是科研探索,后者是商业应用考虑。
现在一起讨论,重点以后者异构原生局部处理单元为主。HNLPU为了应对大模型(LLM)时代的算力挑战,针对其思元(MLU)系列芯片进行的重大架构升级。
一、文章核心内容分析
这篇文章重点解读了在面对大模型算力需求(如千亿、万亿参数规模)时,如何通过底层架构的重构来解决当前AI芯片普遍存在的“内存墙”和“通信墙”问题。
文章主要涵盖了以下几个要点:
架构演进。从早期的NPU演进到如今针对大模型优化的HNLPU。
异构计算增强。强调了在处理大模型时,不仅仅需要张量(Tensor)运算,还需要强大的标量和向量处理能力来应对复杂的算力组合。
内存与带宽优化。介绍了HNLPU如何提升对HBM3/3e的支持以及片上缓存的效率。
互联技术:提到了思元系列配套的MLU-Link技术,旨在实现超大规模集群的高效互联。
二、HNLPU架构
HNLPU(异构原生局部处理单元)是寒武纪在AI芯片领域“硬碰硬”对抗国际巨头(如NVIDIA)的关键武器。我们可以从以下几个维度进行评价:
1.核心设计思想——从“通用”向“大模型原生”转变
优势——传统的NPU强于卷积神经网络(CNN),但在处理基于Transformer的大模型时,很多非矩阵运算会成为瓶颈。HNLPU(异构原生局部处理单元)通过“异构原生”设计,强化了标量和向量处理单元。
评价:这反映了寒武纪对当前技术趋势的精准把握。它不再只是一个“矩阵乘法加速器”,而是一个能完整、高效运行整个大模型推理/训练流水线的处理器。
2.解决“内存墙”挑战
技术亮点——HNLPU大幅提升了访存带宽。在大模型推理(Inference)中,瓶颈往往不在于算力(TFLOPS),而在于数据读写速度(MemoryBound)。
评价:通过优化访存层次结构和指令集,显著提高了有效算力利用率。这意味着在同样的峰值算力下,HNLPU在跑Llama3或GPT系列模型时,实际产出(Tokens/sec)会更高。
3.算子融合与指令集优化
优势——HNLPU引入了更灵活的指令集,支持更高维度的算子融合。
评价:这能有效减少数据在内存和核心之间的往返次数(Round-trip),大幅降低延迟。对于实时性要求高的对话式AI应用,这是至关重要的。
4.生态与软件栈(Neuware)
优势——硬件的强大需要软件来释放。配套的Neuware软件栈对HNLPU做了深度适配,支持PyTorch、TensorFlow等主流框架。
评价:虽然比起NVIDIA的CUDA生态仍有差距,但寒武纪和中科院计算所团队通过提供“魔法棒”般的自动化迁移工具,极大地降低了开发者从CUDA迁移到MLU的成本。
5.集群互联
评价:单卡性能再强也跑不动万亿模型。MLU-Link的存在是为了对标NVIDIA的NVLink。文章强调这一技术,说明HNLPU的目标不仅是单卡加速,而是构建超大规模算力集群,这是进入“大模型俱乐部”的入场券。
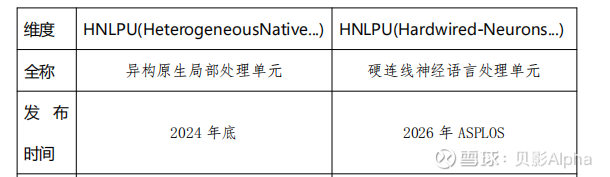
三、两个HNLPU的区别
1.HNLPU(异构原生局部处理单元)
它的核心逻辑不是“固化权重”,而是“优化搬运”。
异构化。芯片内部同时拥有处理矩阵的Tensor核心、处理向量的Vector核心和处理逻辑的Scalar核心。它们像一个精密的瑞士军刀,分工协作。
原生化。硬件电路在设计时就考虑到了大模型的数学特性(比如Transformer的注意力机制),不需要绕弯路去模拟。
(ps:有个说法是把模型焊在电路上,是特指硬连线神经语言处理单元)
局部流转数据。强调数据在芯片内部的高效流转,尽量减少去昂贵的外部显存(HBM)里“搬货”的次数。
2.HNLPU(硬连线神经语言处理单元)“硬连线(Hardwired)”
.........
3.HNLPU(异构原生局部处理单元)并不是一个“死板”的硬件,而是一个“极度聪明”的灵活架构
.........
4.两个HNLPU的全方位对比表格