国内科研团队推出OmniXtreme,助机器人突破运动极限

【紫月投研】近年来,全球人行机器人技术突飞猛进,并在多个领域加速推广,业内对于人形机器人在运动极限方面的关注尤甚。为突破传统限制,近日北京通用人工智能研究院(以下简称“通研院”)发布并开源了新一代人形机器人通用运动框架OmniXtreme(通极)。该框架让机器人能够通过一套统一策略完成包括后空翻、托马斯全旋、武术踢击等在内的多种高动态动作,并在真实机器人上实现了超过90%的成功率。该成果一经发布,便在人形机器人圈子内引起了广泛讨论,毕竟这一新的人形机器人通用运动框架可以让人行机器人学习并泛化不同类型的极限动作,为其未来在更多复杂场景应用推广提供了更多可能。具体来看:
1、机器人要挑战连续高难度动作,现全球范围内普遍面临泛化壁垒(generality barrier)。
从全球范围来看,让机器人像人类一样灵活运动,这是全球机器人研究领域孜孜不倦的核心追求。毕竟,机器人(人形机器人)大规模实现商业化,除了“大脑”要变得足够聪明,能够通过交互理解任务,做好任务执行规划,更需要具备强大的任务执行能力。而任务执行能力的关键,就是要求机器人(人形机器人)能够突破传统极限,执行一系列高难度的动作。
目前,让机器人(人形机器人)模仿单个人类高难度动作(比如模仿运动员实施一个后空翻动作,或者模仿人类执行一个侧空翻动作)已能做到非常精准。但是,一旦让机器人(人形机器人)学习或模仿几十个风格迥异、动态复杂的高难度动作,其学习效果就会大打折扣(机器人的控制器一下子变得“笨拙”起来,并在最具挑战性的动作上频频失败)。

机器人(人形机器人)之所以在风格迥异、动态复杂的连续高难度动作学习过程中出现失败,这主要受制于机器人控制领域长期面临的一个困境—泛化壁垒(generality barrier)。即当动作库的规模和多样性增加时,传统的统一强化学习策略往往会遭遇性能崩溃,这在高动态动作的物理部署中尤为明显。这种崩溃源于两个相互叠加的瓶颈:仿真环境中的学习瓶颈(多动作优化的梯度干扰)以及物理执行瓶颈(真实世界复杂的驱动约束)。
为克服造成机器人泛化壁垒问题的两大核心因素,近年来全球各大机器人(人形机器人)科研机构一直在努力探索。在这一大的时代背景下,通研院(由北京市政府、科技部、教育部支持,朱松纯教授于2020年创建并担任院长,联合北京大学、清华大学等单位共建,系一家非营利性新型研究机构,致力于研发具备自主认知与决策能力、符合人类情感、伦理与道德观念的通用智能体)于2024年联合宇树科技共建具身智能与人形机器人联合实验室,后于2025年4月的中关村论坛上正式推出“通智大脑”,并与宇树科技、乐聚机器人等头部机器人企业组成“通智大脑联盟”,共同推进新一代的人形机器人控制体系研发。
2、北京通用人工智能研究院专注机器人控制领域研究,创造性地推出了OmniXtreme。
为了从根本上解决人形机器人在仿真环境中的学习瓶颈(多动作优化的梯度干扰)以及物理执行瓶颈(真实世界复杂的驱动约束)问题,通研院研究团队提出了OmniXtreme(通极) 框架。该框架将动作技能的学习与物理驱动的微调进行了巧妙的解耦,分为“基于流的可扩展预训练”与“驱动感知的残差后训练”这两个核心阶段。其中:
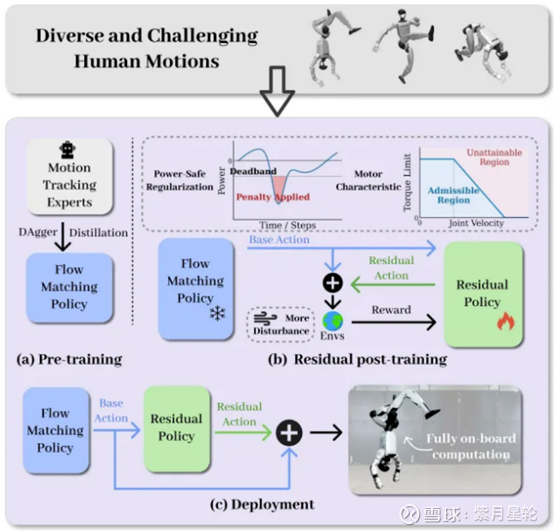
在基于流的可扩展预训练阶段,研究团队的目标是赋予模型极高的表示容量,使其能够掌握大量异构的极限动作,同时避免传统多动作强化学习中常见的保守化平均倾向。研究人员首先整合了LAFAN1、AMASS、MimicKit等多个高质量动作数据集,并将其重定向至宇树G1 人形机器人上。针对机器人(人形机器人)动作库里面的高难度参考动作,团队利用PPO算法训练了一系列专家策略。随后,研究团队采用了基于数据集聚合 (DAgger) 的知识蒸馏技术,将这些专家策略的行为统一融合到一个基于流匹配的生成式策略中。
在驱动感知的残差后训练阶段,为了实现平滑的“从仿真到现实”的迁移,研究团队冻结了预训练的基础策略,并在其之上训练了一个轻量级的MLP残差策略。该残差策略无需重新学习动作跟踪,主要负责输出修正动作以对抗真实的硬件约束。为了让残差策略真正理解物理世界的差异,研究团队在训练环境中引入了三个层面的深度建模:
一是激进的域随机化,研究团队将初始姿态噪声、外力干扰幅度、角速度等常见域随机化参数的范围大幅提升了最高50%,并将终止阈值放宽了1.5倍(例如将躯干方向误差容忍度从 0.8弧度放宽至1.2弧度)。这种设计给予了残差策略充足的探索空间,使其能够学会在大偏差状态下进行极限挽救,极大地增强了系统的鲁棒性。
二是功率安全驱动正则化,在执行后空翻等高动态动作时,机器人会产生巨大的瞬态制动负载。常规的强化学习管线通常缺乏对此类负载的约束,从而极易在真实硬件上触发过流保护或热应力宕机。研究团队创新性地引入了针对机械功率的惩罚机制,其核心在于计算关节扭矩与角速度的乘积,即瞬时机械功率 P=τ・ω。
三是驱动感知的扭矩与速度约束,单纯的扭矩截断往往会忽略由反电动势引起的与速度相关的物理限制。研究团队将真实的电机运行包络线直接集成到仿真器中,定义了随关节速度幅值单调递减的容许扭矩函数,同时还通过非线性摩擦项对执行器级别的内部损耗进行建模。
3、OmniXtreme基于全新的架构和建模设计,在全方位挑战极限测试中表现非常亮眼。
为了全面评估OmniXtreme的可扩展性与鲁棒性,通研院研究团队不仅使用了标准的 LAFAN1动作库,还精心挑选了约60个极具挑战性的动作,构建了XtremeMotion评估集。这些动作包含了极高的角速度、频繁的接触切换以及严苛的时序约束。从OmniXtreme的仿真及实测情况来看,其在全方位的挑战极限测试中表现出了良好的效果:
在可扩展的高保真跟踪能力方面,相比传统的“从头训练多动作强化学习”基线模型以及“专家到统一MLP蒸馏”基线模型,OmniXtreme在仿真环境下的所有指标上均对基线模型实现了超越(面对难度激增的XtremeMotion数据集,传统方法的跟踪误差显著增加,而OmniXtreme依旧维持了极低的运动学误差和极高的成功率),在现实世界的任务执行成功率方面亦实现了显著提升(研究团队选取了XtremeMotion中24个不同的高动态动作,共计进行了157次物理测试,OmniXtreme斩获了91.08%的整体平均成功率)。

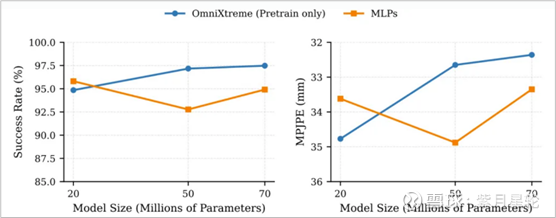
在模型规模的Scaling Law方面,研究团队对比了不同参数规模(20M、50M、70M)的模型表现。相比传统的MLP策略(其在扩大参数量后很快就陷入性能饱和,跟踪精度提升极其有限),OmniXtreme基于流匹配的生成式策略完美契合了Scaling Law。随着参数量向70M迈进,OmniXtreme的跟踪精度与鲁棒性呈现出显著且稳定的线性增长。这表明,OmniXtreme的生成式预训练为人形机器人控制系统提供了一条切实可行的能力扩张和进化路径。
总体来看,OmniXtreme通过一种新的训练路径(不再为每个动作单独训练策略,而是通过生成式模型与强化学习结合的方式,让机器人掌握一整类极限运动能力),显著提升了机器人(人形机器人)在复杂任务方面的执行能力,且表现出显著的泛化特征。
【紫月锐评】当前,全球人形机器人技术快速迭代,已经迈过从0-1的最关键阶段,并在各方的共同推动下加快从1-100的演化进程。从人形机器人的技术发展路径和产业化关键促进要素来看,在人形机器人后续应用场景大规模推广的过程中,有两大方向一直备受各界关注(一是娱乐与极限运动方向,其对机器人的要求集中在挑战更高难度的动作,例如跑酷、复杂环境运动等;二是真实的生活服务方向,其对专业服务场景的流程嵌入要求较高,同时也需要机器人能够配合执行一些精细化、复杂化的任务)。未来,随着OmniXtreme等新技术持续取得突破,当人形机器人在运动能力、感知能力和自主决策能力方面逐渐融合,其在下游各应用场景的渗透将持续加快,也将对AI大模型(代表企业Minimax、科大讯飞等)、控制器(代表企业拓普集团、三花智控等)、电机(代表企业昊志机电、鼎智科技等)、机器人本体(代表企业埃斯顿、禾川科技等)等产业链上下游带来更多新的投资机会。