多模态AI,最正宗的10家公司

兰板套利
· 江苏
多模态 AI:开启智能新时代
在人工智能飞速发展的当下,多模态 AI 已成为引领行业变革的关键力量。简单来说,多模态 AI 是指能够同时处理和理解多种类型数据(如文本、图像、音频、视频等)的人工智能技术 ,就像人类能通过视觉、听觉、触觉等多种感官全方位感知世界一样,多模态 AI 打破了单一数据类型的限制,让机器能够从多个维度理解和处理信息,极大地拓展了人工智能的应用边界和能力范畴。
从发展历程来看,多模态 AI 的崛起绝非偶然。早期的人工智能大多局限于单模态处理,比如计算机视觉专注于图像识别,自然语言处理聚焦于文本理解。但随着深度学习技术的不断突破,以及大数据和强大算力的支持,多模态 AI 开始崭露头角。OpenAI 的 GPT-4V、谷歌的 Gemini 等多模态大模型的发布,更是引发了全球范围内的广泛关注和研究热潮,标志着多模态 AI 进入了一个全新的发展阶段。
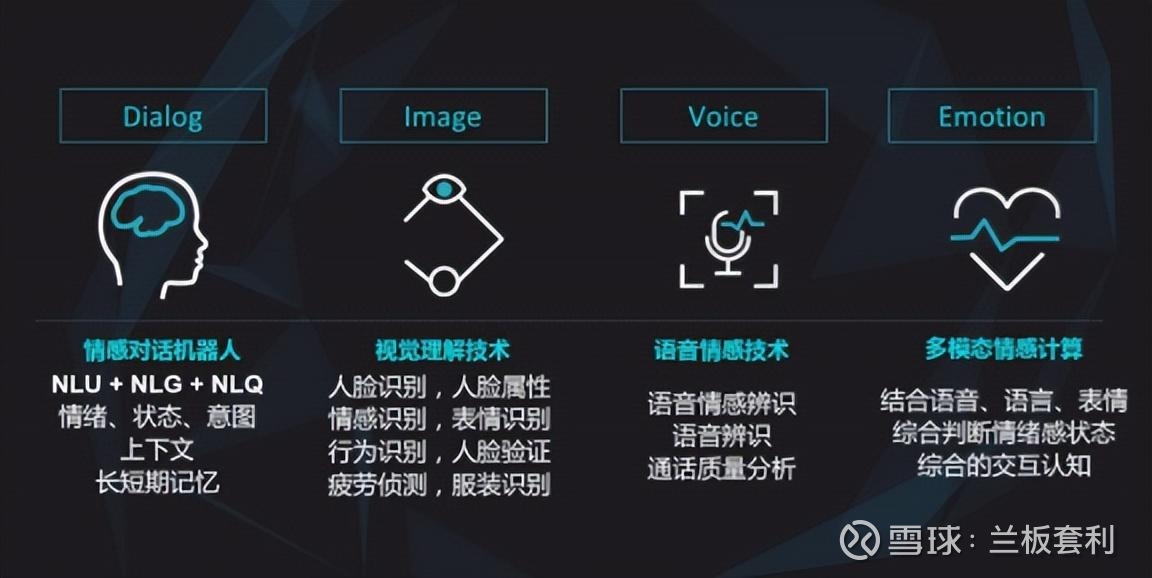
如今,多模态 AI 的应用
点击查看全文