看完GTC2026,持有八年的我反而有点悲观

我刚看完老黄今年 GTC 的 Keynote。
说实话,英伟达这家公司本身没让我感到意外。这次 GTC 发布的东西,跟我之前的判断基本吻合,没有什么特别惊喜的地方。英伟达很强,这一点大家都知道,我也一直很清楚。
真正让我不太舒服的是另一件事。
老黄在台上说了"1 万亿美金",底下坐着的开发者和厂商都很兴奋,网上的分析文章也是一片叫好。但我看着这些反应,反而觉得有点不对劲——大家的预期真的已经被撑到这个地步了吗?从 5000 亿到 1 万亿,连眉头都不皱一下?
到了这个阶段,我感觉数字和现实之间有一些东西开始对不上了。而我担心的,从来不是英伟达这家公司——是英伟达之外的那些因素。
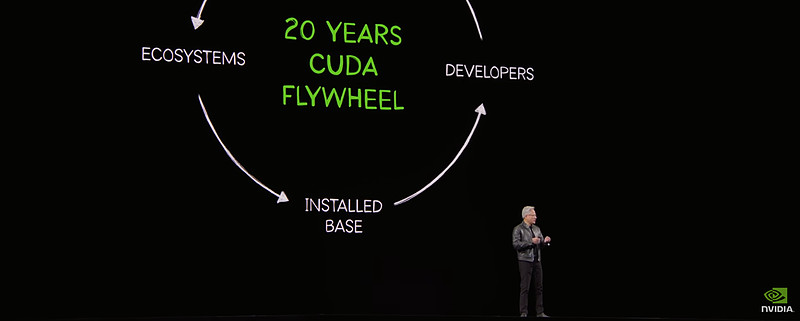
CUDA 二十年
今年 GTC 有一个很特殊的节点——CUDA 二十周年。老黄开场花了将近十分钟讲 CUDA 的演进,他自己说真正难以复制的壁垒就是底层的安装基数。然后他讲了那个飞轮效应:安装基数吸引开发者,开发者用 CUDA 做出突破——比如深度学习——突破催生新市场,新市场带来更多公司和用户,安装基数继续膨胀。他说六年前出货的 Ampere 架构,现在在云上的租用价格反而在涨——因为 CUDA 生态让它的应用场景越来越多,生命周期越来越长。这就是飞轮在转的证据。
看到这里我挺感慨的。我当年就是因为花了两年研究 CUDA,想通了这个飞轮逻辑,才敢在 2018 年买入英伟达。要不是先看懂了 CUDA,我大概率会像错过谷歌那次一样,眼睁睁看着股价涨上去然后后悔。
二十年了,从当年没多少人理解,到今天成了英伟达一切的基座。这个过程真的不容易。建议各位球友去看一下老黄 Keynote 开头讲 CUDA 那段,对理解英伟达这家公司非常有帮助。CUDA 的具体分析我之前的文章已经写得比较透了,这里就不再展开。
Extreme Co-design:不是在设计芯片,是在设计整个 AI 基建
关于 Extreme Co-design,我之前也写过一篇深度分析。这次让我印象最深的不是概念本身,而是老黄思考问题的那个维度变了。
你去看他在台上讲话的方式,你会发现他不是在讲某一颗芯片有多快——不管是 GPU、CPU、DPU 还是这次新出的 LPU,他也不是在讲某一个机架或者某一个 Pod 有多强。他是直接站在整个 AI Infrastructure 的维度上来做设计的。
这次 Vera Rubin 平台一共整合了七颗不同的芯片,从 CPU 到 GPU 到网络交换到存储加速再到这次新加入的 Groq LPU,组成了五个机架级系统。但在老黄的眼里,这些不是七颗独立的芯片加五个独立的机架——这就是一台超级计算机。他把整个平台当作一个整体来做 Co-design,每一颗芯片从设计的第一天起就是为了跟其他六颗配合工作而存在的。
举个例子。虚拟 AI 工厂这件事,英伟达 Omniverse 做数字孪生早就不是一天两天了。但这次老黄把它直接用在了 AI 工厂的建设流程上——几百亿美金的数据中心,在真正动工之前,先在虚拟世界里跑完整的仿真。把所有可能的问题提前找出来,调整参数,优化布局。等到现实中真正建起来之后,实施过程中产生的真实数据又会反过来增强数字孪生模型,让虚拟世界里的仿真更准确。这种虚实之间不断循环增强的思路,对于动辄几百亿美金的投入来说,价值太大了。
还有一张图我印象非常深。老黄自己说,这是"本场最重要的一张图",以后全世界所有 AI 工厂的 CEO 都会盯着这张图研究。图上画的是在同等功耗条件下,每一代芯片能提供的 token 吞吐量和生成速度。他把 token 服务按质量分成了四档:Free、High、Premium、Ultra。从 Hopper 到 Blackwell 再到 Vera Rubin,每一代芯片都在把曲线往右上方推——意味着同样的电费,能产出更多、更快的 token。最顶上那个 Ultra 档,也就是万亿参数模型、百万 token 上下文、每秒上千 token 生成速度的那个级别,只有 Vera Rubin 加上 Groq LPX 才够得着。
老黄讲这张图的言下之意很清楚:未来模型厂商可以在不同的档位上定价,越高端的 token 利润越大。他是把模型的商业模式、算力的经济学、基础设施的效率、数据中心的功耗全部绑在一起,统一来思考。
老黄就是这么想问题的——从头到尾一通设计,不留死角。也只有做到这个程度,英伟达才能保证每年一代的架构迭代。而且这种迭代已经不只是芯片级的了,它是整个 Infra 层面和 Model 层面在同时推进。如果各位球友看过我之前写的 AI 五层蛋糕那篇文章,就能理解——必须把五层统一来看,才能从全局上做提升。只盯着芯片一层,永远看不到全貌。
连 Semi-Analysis 都管英伟达叫"推理之王",老黄在台上听到这个评价的时候笑得很得意。说实话,这个称号没给错。
Groq 收购:最让我震惊的不是技术,是这家公司的消化能力
关于推理这块,网上分析文章已经铺天盖地了,技术细节我就不赘述。我想讲个不一样的角度。
去年圣诞节前夕,英伟达花了 200 亿美金收购 Groq 的 LPU 技术和核心团队。收购大公司的人都知道,一般的流程是这样的:收购完成之后,先花半年做团队整合,再花半年磨合文化,中间大概率还会出各种内部矛盾。一年以后能推出第一个 demo 产品就已经算快了。
但英伟达呢?三个月不到,Groq 3 LPU 不仅做成了产品,而且老黄在台上说的是——"我们已经在量产了"。不是 demo,不是 roadmap 上的一个方块,是量产中的产品。
我说实话,我没想到能这么快。
256 颗 LPU 装进一个 LPX 机架里,跟旁边的 Vera Rubin NVL72 搭配工作。两种芯片各取所长——GPU 擅长的是计算密集的 prefill 阶段,就是处理你输入的那段 prompt;LPU 擅长的是带宽敏感的 decode 阶段,就是一个 token 一个 token 往外吐答案的那个过程。LPU 的内存容量虽然比 GPU 小得多,但带宽快了好几倍,所以做 decode 的时候速度极快。老黄说这两种芯片组合之后,万亿参数模型的每瓦推理吞吐量提升了 35 倍。
从圣诞节前签约到三个月后量产,这个速度在行业里基本没有先例。而且这才是收购后的第一个作品,下一代做更深度的整合之后,性能提升会更大。这一点体现了英伟达这家公司的文化——不管是战略眼光还是落地能力,在整个行业里确实是独一档的。
做 ASIC 推理芯片的那些投资人,恐怕亏了不少
由 Groq 这个话题,多讲一个投资视角。
去年甚至更早之前,有不少专门做 ASIC 推理芯片的厂商在挑战英伟达。逻辑很简单——GPU 太通用了,做一个专门针对推理优化的芯片,在特定场景下可以比 GPU 快很多。一级市场的投资人也买单了,融资金额和估值都给得非常高。
我不是说不应该尝试,这种探索本身是有价值的。但现在回过头来看,我一直不看好 ASIC 做 AI 推理的核心原因没变——ASIC 和特定模型的绑定太深了。
做个 demo 没问题。但想想老黄讲的那个现实:一个数据中心的投入是几百亿美金。在一个砸了这么多钱的数据中心里面,你会用一种跟某个特定模型强绑定的 ASIC 芯片来做加速吗?万一这个芯片跟新版模型不兼容,或者运行过程中出了什么问题导致数据中心停机,哪怕只停几个小时,造成的损失可能比芯片本身贵得多。更不用说,模型一直在迭代——今天跑得飞快的 ASIC,明天模型架构一换,可能直接就用不了了。
英伟达的 GPU 通过 CUDA 生态天然具备这种灵活性,模型怎么换,CUDA 都能接得住。而现在英伟达又把专用推理芯片收进了自己的体系,跟 GPU 形成互补——这一下把那些独立做 ASIC 推理芯片的公司的空间挤得非常窄了。
一级市场投了不少这类项目,我估计大部分亏了不少钱。
这件事为什么重要?因为它不是个案。在 AI 最疯狂的那段时间,一级市场投了很多类似的高估值项目,不只是 ASIC,还有很多其他方向,基本都是血本无归。如果做投资的人持续亏钱、资金链开始出问题,我觉得这轮 AI 革命的裂缝就会开始出现。
等下讲到万亿美金的时候,就会理解我为什么把这两件事串在一起讲。
一万亿美金——大家都很兴奋,但钱从哪来?
老黄今年给了一个数字。他说去年站在同样的位置,看到了大概 5000 亿美金的高确信度需求和采购订单。而今年,站在这里,他看到了至少 1 万亿美金,到 2027 年。
他还开了个玩笑——"我知道你们为什么没什么反应,因为你们去年都创了收入纪录"。台下的供应商和开发者都笑了,气氛很好,大家很兴奋。
但我笑不太出来。
不是因为我不信老黄的判断力——这个人的战略眼光在整个行业里是顶级的。我打问号的不是他的判断,而是这个数字背后的融资结构能不能撑住。
现在 AI 基建的增长主要靠大公司拉动。但大公司光靠自己的现金流已经不够了,它们在发债、在做私募信贷。$CoreWeave(CRWV)$ 这样的 Neo Cloud 更加激进——融资,用设备做抵押,再贷款,再建基础设施,循环往复。这本质上就是一个高杠杆游戏。美国的宏观数据也不好看,失业率和通胀都还在那里摆着。英伟达、Oracle、OpenAI 三者之间的关联交易也让不少人不放心——老黄在台上多多少少回避了这个话题。
1 万亿美金放在全球范围来看,跟很多国家全年的 GDP 是一个量级的。这不是某一家公司能扛的事,需要整个生态的融资链条都是健康的。
然后是我觉得最值得深想的一点。
之前大家拼命往 AI 基建里砸钱,背后有一个很大的驱动力——AGI。Meta 砸几百亿,$谷歌A(GOOGL)$ 砸几百亿,心里想的都是"万一 AGI 出来了呢"。那种对 AGI 的狂热追逐,让大家愿意为巨大的不确定性买单。
但这种狂热,我感觉在松动。
大家慢慢发现,AGI 可能还是挺遥远的事。不是一两个模型突破就能到的,至少还需要两到三个模型层面的重大 breakthrough,加上很多其他方面的支撑。这不是一两年内能实现的事。
应用端确实有东西在落地——Agent 来了,各种 AI 工具在普及。但 Agent 和 AGI 是两回事。Agent 能做的事跟 AGI 那种"什么都能干"的愿景比起来,差距还是很大的。当 AGI 不再是那个终极的诱惑,大家对万亿美金级别基建的热情还剩多少?
还记得前面讲的那些 ASIC 投资人亏钱的事吗?那不是个案。AI 最疯狂的时候,一级市场投了很多类似的项目,很多已经血本无归。如果一级市场持续失血,资金链出了问题,那不只是某几家创业公司倒闭的事——整个 AI 基建的融资结构都会受到冲击。
英伟达的护城河再深,也是建在整个生态上面的。地基如果松了,城墙再高也会晃。
宏观这块我最近确实一直在想,准备去做一些整体配置的调整。但几个 thesis 目前还不算特别清晰,等想得更明白了,改天再写一篇细说。
NemoClaw 和 Agent OS——方向我认同,但我还没完全想透
最后聊一个我觉得值得长期关注、但我自己坦率说还没完全消化的东西。
英伟达这次推出了 NemoClaw,它是 OpenClaw 的 NVIDIA Reference Implementation。简单说,就是英伟达帮 OpenClaw 做了一个企业级的版本,主打安全和易用。
老黄给 OpenClaw 的定位非常高。他直接叫它 Agent OS——Agent 时代的操作系统。他说这东西跟 HTTP 是一个级别的,跟当年的 Windows 开启个人电脑时代也是一个级别的。他说现在全世界所有公司的 CEO 可能都在想自己公司的 OpenClaw Strategy。
从开放生态和目前的采用速度来看,我觉得这个方向是对的,很 make sense。
提一嘴,我之前写过一篇关于自己用 OpenClaw "养虾"的文章,后来因为各种原因被限流了,就先藏起来了。当时 OpenClaw 还叫 ClawdBot 的时候我就开始研究了,那时候我就判断这种东西肯定会有公司来做更易用的 Pre-packaged 版本,同时解决安全和隐私的问题。现在英伟达推出 NemoClaw,发展方向跟我当时的判断一致。
但说实话,什么叫 Agent OS,这件事我现在也还在理解和消化中。我能感觉到它的重要性,也确实看到了一些未来的苗头,但如果你问我对它有多深的独到理解,我现在还给不出来。这块需要时间去观察和研究,等我有了比较成熟的、跟别人不一样的看法,再来跟球友分享。我不想说一些网上到处能搜到的泛泛之谈,那没意义。
如果有球友对那篇"养虾"经历感兴趣,评论区说一声,我想办法改一改重新放出来。
写在最后
说说看完这场 GTC 之后最真实的感受。
英伟达的护城河不用多说了。CUDA 飞轮转了二十年,到今天整个行业都绕不开它。这次 Groq 收购从签约到量产只用了三个月,这种执行力在行业里基本没有先例。AI 基建一时半会也停不了,这个时代确实还在大规模投入的阶段。
但我不是因为英伟达不够强而悲观。
我是看着台下那些人兴奋的样子,看着网上那些"Token 之王""AI 春晚"的标题,心里觉得有什么东西对不上。当所有人都在欢呼万亿美金的时候,谁在认真想这些钱到底从哪来、能不能持续?当 AGI 的叙事慢慢没那么性感了,当一级市场的钱在持续失血,当整个生态的融资越来越依赖高杠杆——万亿美金的基建真的能按老黄说的节奏落地吗?
作为一个持有了八年的人,我现在想的不是"要不要卖"。我想的是——如果外部环境恶化,我现在的持仓结构能不能让我睡好觉?
这可能是接下来几个月我要认真想清楚的事。宏观这块最近一直在研究,等 thesis 更清晰了,改天再写一篇细说。
利益相关声明: 本人持有$英伟达(NVDA)$ 多年,文中观点基于个人持仓视角,存在利益相关。
免责声明: 本文仅为个人投资思考记录,不构成任何投资建议。投资有风险,入市需谨慎。每个人的风险承受能力和投资目标不同,请基于自身情况独立判断。