Deepseek V3.1版本发布,必然引发国产算力热潮,而且明确支持下一代国产算力芯片FP8计算规格

快兔充电
· 浙江
Deepseek V3.1版本发布,
必然引发国产算力热潮,
而且明确支持下一代国产算力芯片FP8计算规格
也就是所有计算的参数规格从上一代的FP16,16位浮点降为8位浮点格式
而且这8位浮点数据,储存是8位整数的形式,也就是储存运算的时候是int8格式,8位整数
真正需要浮点运算的时候用显卡的乘法矩阵流水线,乘一个浮点的位数,就变成了FP8规格
用最简易的乘法
把整个模型的数据规格从fp16,也就是十六位浮点小数,降为最低的int8,也就是8位整数的格式
这对算力芯片数据的储存和运算算力的需求下降了起码一个量级以上
简直是天才的设计
只有完全自研显卡核心以及完全自研指令集的研发团队才能紧跟时代的发展脚步
英伟达能否跟上是另外一个问题了
因为他作为一个美国公司,对国内这些国产人工智能大模型的变化没有那么敏感,
如果技术进步没有那么紧密的话
很可能被紧密结合的国产算力芯片给狠狠甩下

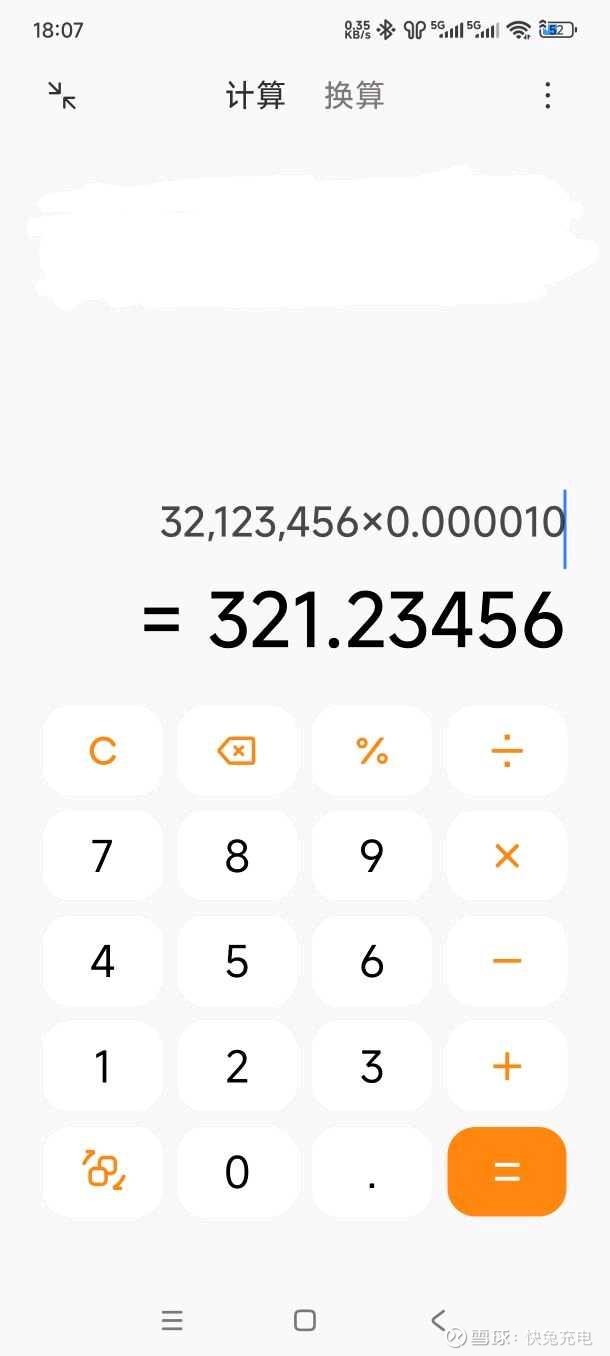
用计算器简单演示一下8位整数如何变成8位浮点原理
说白了就是前一个8位整数储存数据,后一个8位整数储存小数点位置
两者相乘以后就变成了8位浮点


deepseek3.1用的是8位整数的数据规格,很可能显存需求降到到原来的1/8,
原先H20之所以是刚需,因为它有自带96g的显存,
8卡的一体机正好可以带动满血版的671B的DeepSeek
降到原先1/8以后,很可能国产的12g显存的显卡做出来的8卡机就能跑满血版的deepseek,
绝对利好砺算,利好东芯
更何况东芯的砺算科技准备推出的是24gb的显卡
如果12gb的显卡八卡机都能运行
8卡24gb的显卡是必然能运行满血版的8位deepseek3.1
砺算的绝对大利好
