LPU(语言处理单元):AI界“春晚”来咯!AI推理时代的专用处理器突破算力瓶颈

2026年3月16日-3月19日,英伟达计划在GTC大会上发布整合Groq技术的LPU推理芯片,这标志着AI算力需求结构正从“训练优先”向“推理优先”深刻转变。

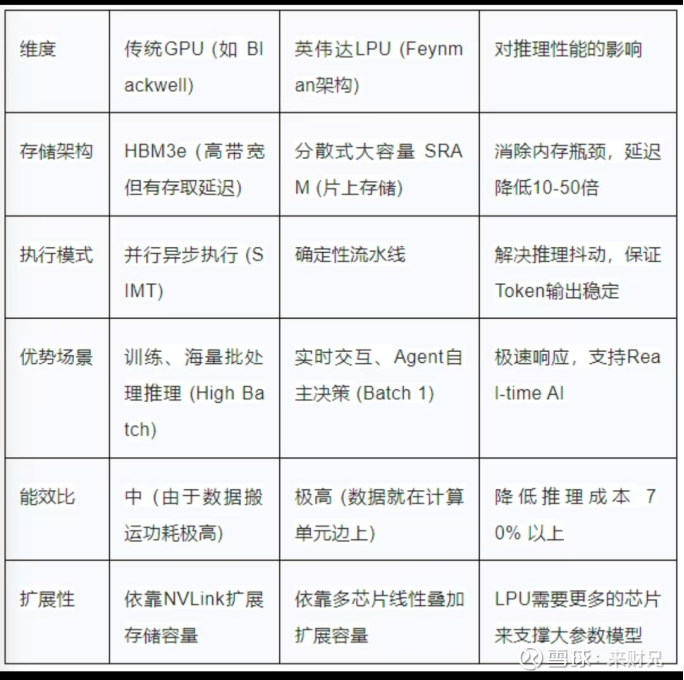
技术层面:LPU通过片上SRAM存储模型权重(230MB提供80TB/s带宽)、编译时静态调度架构和分布式推理策略,在Llama2-70B模型推理任务中可实现比H100 GPU快约10倍的速度提升,成本约为GPU的十分之一。
市场层面:随着Agent应用爆发,推理侧需求已超过训练侧。预测显示,到2032年训练成本占大型云计算公司数据中心支出的比例将从目前的40%以上降至14%左右。英伟达斥资200亿美元获得Groq核心技术授权,将其定位为“下一个Mellanox”。
产业链层面:LPU采用52层M9级覆铜板+Q布方案,单芯片PCB价值量约3000元,单柜PCB价值量达45-70万元。这一规格跃升推动PCB产业链从用量到单价迎来倍数级增长,并向上游特种材料及精密加工环节扩散。
PCB产业链在电子布(菲利华、中材科技)、树脂(东材科技)、CCL(生益科技)、PCB制造(胜宏科技、沪电股份)、钻针(鼎泰高科)、加工设备(大族数控)等环节迎来重大机遇。
一、引言
1.1 背景
2026年2月,英伟达在2026财年第四季度财报电话会议上详细阐述了对Groq的整合计划,并表示将在3月16日开幕的GTC 2026大会上推出整合Groq LPU技术的全新AI推理芯片系统。这款被英伟达首席执行官黄仁勋称为“世界从未见过”的全新系统,专为加速AI模型的查询响应而设计。
这一战略布局的背景是AI产业竞争重心的根本性转移。此前行业处于以参数堆砌为核心的“训练军备竞赛”阶段,而如今已集体转向模型落地、智能体普及的“应用绞杀赛”。客户关心的核心指标,从“能否训练出最强大模型”急转为“每个Token的推理成本是多少”。
1.2 意义
LPU的推出对AI算力市场和相关产业链具有多重意义:
对AI产业:标志着AI行业正从“规模竞赛期”转向“效率价值兑换期”,推理侧需求大于训练侧需求已成为普遍共识,将推动AI推理硬件向细分化、高效化演进。
对英伟达:这是其在面临市场、客户与技术“三重围剿”下的战略突围,通过引入新架构,英伟达试图在AI产业演进的下一阶段继续巩固市场统治地位。
对PCB产业链:LPU的高规格要求直接催生量价齐升、工艺升级、材料革新、集中度提升的深远影响,为PCB行业打开全新的市场规模空间。
二、LPU的技术架构
2.1 LPU的定义与定位
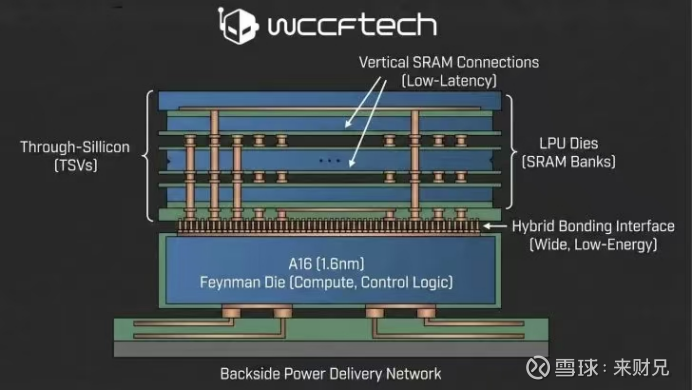
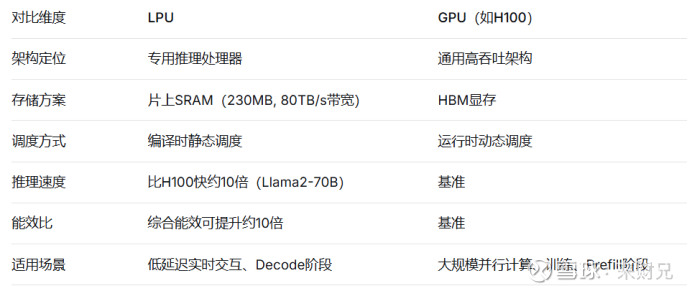
LPU(Language Processing Unit,语言处理单元)是一种专为AI推理,特别是低延迟实时交互(如对话)设计的专用处理器。其核心设计理念是通过“编译器驱动”的静态调度实现确定性执行,并依赖高速片上SRAM来消除内存瓶颈。

与追求通用计算能力的GPU不同,LPU针对语言模型推理的确定性与低延迟特性进行了专门优化,其结构性优势主要体现在低时延或具有人机交互属性的代理AI场景。

2.2 核心技术特点
2.2.1 片上SRAM存储模型权重
LPU采用高密度片上SRAM(静态随机存取存储器)来存储模型参数,将数据“贴着算力跑”,极大缩短数据路径。230MB的片上SRAM可提供高达80TB/s的内存带宽,从架构层面降低延迟与能耗。
这与GPU形成鲜明对比:GPU通常将大量模型参数存放在外部HBM(高带宽内存)中,计算核心与内存之间需要进行频繁数据搬运,影响模型推理的时效性。
2.2.2 编译时静态调度架构
LPU采用“编译器驱动”的静态调度实现确定性执行,将整个计算和芯片间通信的步骤精确规划到时钟周期,形成稳定的“静态时序”,从而保证稳定的高吞吐量。
相比之下,GPU以运行时动态调度为基础,在执行哲学上存在根本差异。GroqWare采用以编译器静态调度为核心的执行模型,而CUDA则以运行时动态调度为基础。

2.2.3 分布式推理策略
针对片上SRAM容量有限的客观约束,LPU采用分布式推理策略:建立千卡互联集群,每张卡仅存储并计算模型的一小部分,最后聚合输出,从而更好地适配低延迟推理场景。
2.3 LPU与GPU的性能对比
2.4 PD分离架构与异构协同
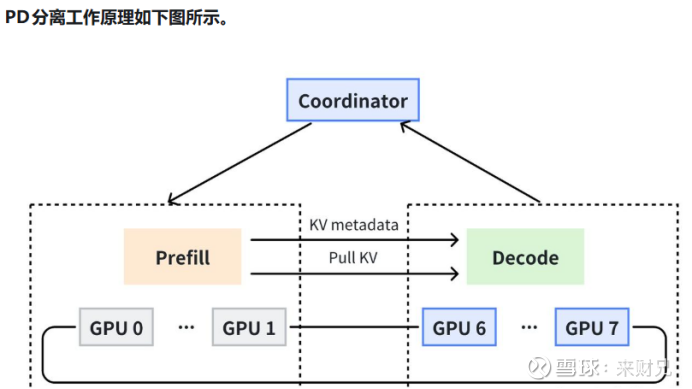
大模型推理主要分为两个计算过程:
预填充(Prefill)阶段:处理用户输入,是计算密集型任务
解码(Decode)阶段:逐token生成输出结果,是内存密集型任务
真正影响用户推理体验的关键在于Decode阶段的生成速度与延迟。针对这一特点,英伟达于2025年9月提出PD分离式部署(Prefill-Decode Disaggregation)技术,将LLM推理拆分为两个阶段并分别优化。
未来的推理架构很可能是GPU与LPU的异构协同:
GPU:凭借强大的并行能力和大显存,依然是模型训练和处理大量上下文(Prefill阶段)的核心
LPU:在要求即时响应的文本逐词生成(Decode阶段)中发挥优势,适合高并发的在线推理服务
三、市场背景与战略布局
3.1 推理时代的市场转变
随着Agent应用爆发,全球算力需求结构正发生明显变化,市场重心从训练转向推理。据彭博社预测,2025年训练成本占大型云计算公司数据中心支出的40%以上,但到2032年,这一比例将降至14%左右。IDC同样指出,到2028年,中国非GPU服务器的市场规模占比将逼近50%。
英伟达CEO黄仁勋表示,“AI推理计算将增长超过10亿倍”。市场普遍认为,AI推理的市场规模将是AI训练的3倍至5倍。
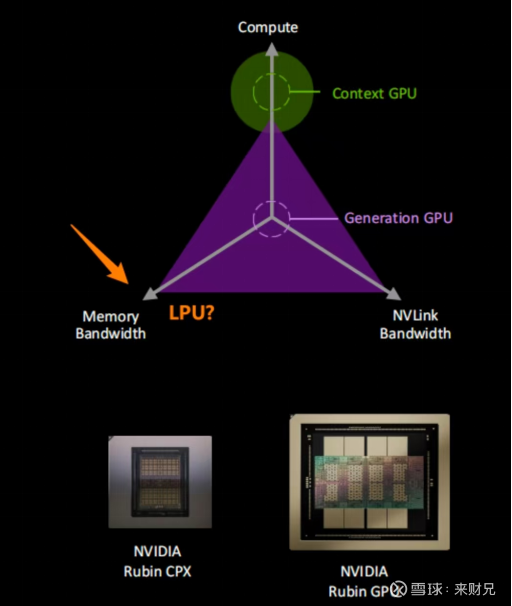
3.2 英伟达的Groq整合计划
2025年底,英伟达斥资约200亿美元现金,完成了对Groq核心技术授权及其核心团队的收购,吸纳了包括创始人Jonathan Ross在内的高管团队。Jonathan Ross被誉为“谷歌TPU之父”。

黄仁勋将此次收购与2020年收购Mellanox相提并论,暗示Groq将在英伟达的AI版图中发挥革命性的基础作用。核心战略在于:快速获取LPU这一“推理利器”,并将其作为“加速器”,深度整合进英伟达的CUDA+TensorRT-LLM全栈软件生态。
3.3 市场竞争格局
多家头部模型厂商已开始分散风险,与不同芯片供应商达成合作:
OpenAI:与Cerebras签署数十亿美元推理优化芯片订单;同时签署使用亚马逊Trainium芯片的重大协议
Anthropic:与谷歌签订210亿美元TPU合作协议
Meta:与AMD达成大规模推理芯片合作;英伟达本月宣布扩大与Meta的合作,进行首次大规模的纯CPU部署
在中国市场,国产模型也正加速转向本土算力方案。DeepSeek将其最新模型V4的早期访问权限优先适配昇腾、寒武纪等国产计算平台,而非英伟达或AMD。据Bernstein Research预测,到2026年,华为在中国AI芯片市场份额可能达到50%,而英伟达份额或降至个位数。
四、对PCB产业链的详细影响
4.1 PCB用量与价值的倍数增长
LPU的高规格要求直接催生PCB产业链的革命性变化。由于单颗LPU的230MB SRAM存在容量瓶颈,运行大规模模型需要数百颗LPU串联。
用量测算:
相较于Rubin单柜采用8颗至32颗GPU芯片,LPU单柜采用256颗芯片
单柜内256颗芯片的PCB用量面积提升50%至9.2平方米
电子布用量接近翻倍达到1037平方米
价值量测算:
传统8卡GPU所用PCB为20层至24层
英伟达Rubin所用PCB为40层至78层
LPU采用52层M9级覆铜板+Q布的增强方案
单颗LPU芯片所用PCB价值量约3000元,是传统方案的5倍至10倍
单柜PCB总价值量(包括计算板、背板)达到45万至70万元
4.2 材料体系的全面升级
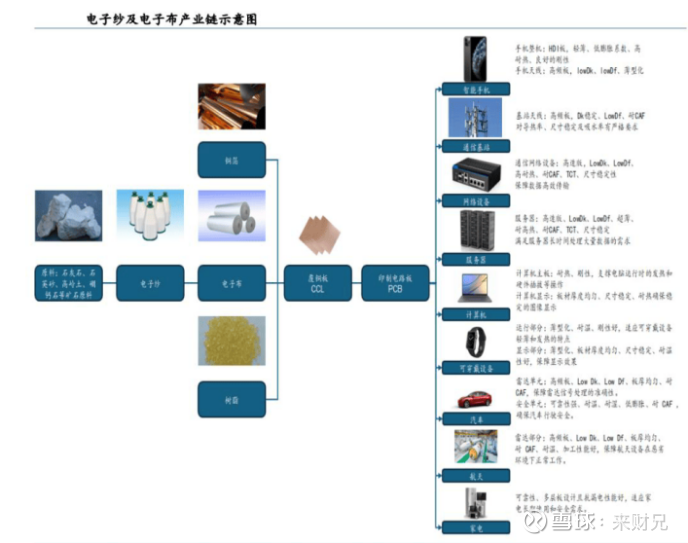
4.2.1 电子布:Q布成M9标配
石英布(Q布)成为M9基材的标配,其信号损耗仅为普通电子布的1/100,且受热不膨胀,是满足224Gbps高速信号传输的关键材料。Q布的市场价值约为普通电子布的10倍,需求放量直接推高行业产值。
玻纤布价值量占到覆铜板成本约30%。据产业调研,目前电子布供应紧张态势预计将持续至2027年下半年,基板交期已拉长至半年。
4.2.2 树脂:向BCB体系升级
M9等级基材对高频高速树脂的损耗因子、吸水率等指标要求大幅提升,推动树脂体系从传统PPO向BCB(苯并环丁烯)升级。BCB树脂单价高达300万-1000万元/吨,是传统树脂的6-20倍。
4.2.3 铜箔:HVLP技术壁垒高
HVLP系列技术壁垒极高,核心工艺及后处理设备依赖日本进口,扩产周期长达12-18个月。2026-2028年HVLP-4供需缺口预计达24%、40%、36%。
4.3 加工设备与耗材的新需求
52层高多层板和M9/Q布的硬材料特性,使得PCB加工难度大幅提升:
钻针环节:由于M9材料硬度高,钻针寿命从传统500孔降至100孔,消耗量显著增加。预计PCB钻针将呈现供不应求及产品涨价的高景气度局面。
激光设备环节:超快激光钻孔技术成为加工M9/Q布等难加工材料的刚需。同时,GPU+LPU的异构架构对封装技术和精度要求较高,预计在PCB电子装联环节对高精度装联设备的需求量将进一步提升。
4.4 先进封装要求提升
英伟达有望利用3D堆叠技术,将Groq的LPU单元直接堆叠在GPU主芯片之上,通过多芯片协同弥补SRAM容量不足,同时保持低延迟优势,实现通用计算与专用推理在物理层面的深度融合。

GPU+LPU的异构架构对封装技术和精度要求较高,预计将推动CoWoS、SoIC等先进封装技术的需求激增。
五、产业链梳理
5.1 上游核心材料
5.1.1 电子布
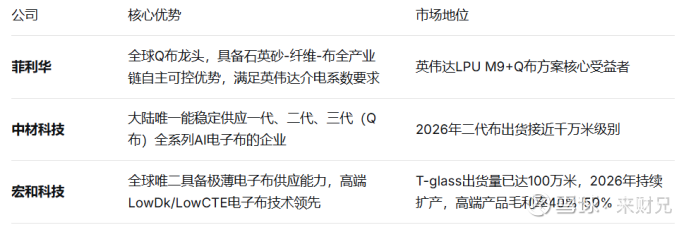
5.1.2 树脂

5.1.3 SRAM

5.2 中游CCL/PCB及设备

5.2.1 CCL

5.2.2 PCB

5.2.3 设备与耗材

5.3 下游系统集成与配套设施

以下是网传的NV供货:(强调是网传)

六、行业趋势与投资机遇
6.1 产业高景气度持续
AI产业快速发展,带动PCB市场需求持续旺盛,涨价成为行业关键词:
2024年3月以来:CCL、粘合胶片、电子布开启价格上涨模式,涨价5%-15%
2025年第四季度:生益科技、建滔集团开启第二轮涨价,普通FR-4板涨价8%-10%,高速高频板涨价10%-15%
2026年3月:日本Resonac上调CCL及粘合胶片价格30%,预计将传导至高端制造环节
2026年至今电子布涨价速度也是让人震惊!
展望PCB产业的需求及价格趋势,高盛认为AI驱动产业进入超级周期,带动PCB量价齐升,涨价将贯穿2026年至2027年,高端产品的供需缺口持续。
6.2 市场规模预测
咨询机构Prismark预计,2024年至2028年全球PCB行业产值仍将以5.4%的年复合增长率成长,到2028年预计超过900亿美元。其中,HDI板2027年市场规模有望达到145.8亿美元,2023年至2028年CAGR达6.2%,高于行业平均增速。
AI带动高速材料量价齐升,M9级CCL、石英电子布等核心材料供给缺口还在扩大。
6.3 国产替代机遇
英伟达高端芯片在中国市场的缺位,为华为昇腾、海光、沐曦、摩尔线程等国产算力企业提供了练兵场与试错空间。DeepSeek等领先模型公司与国产芯片的深度合作,是构建自主软硬协同生态的关键一步。
国产算力的机会,或将首先出现在对尖端制程依赖相对较低、更强调软件优化和行业理解的推理侧,以及政务、金融、工业等特定行业的模型落地中。
七、全文汇总
LPU的出现反映了AI计算架构向领域专用化发展的必然趋势。通过深入分析语言模型的计算特征并据此优化硬件设计,能够在推理任务上实现显著的性能提升。英伟达将Groq LPU整合进自身AI芯片体系,展现了专用推理芯片在生成式AI推理计算中的战略重要性。
随着AI应用落地及规模快速增长,专用AI推理芯片的市场将快速扩张,为上游核心材料、中游制造加工、下游系统集成等环节带来全新的市场空间。
LPU ——万通智控:“芯”驭未来,双轮驱动,LPU商业化启航$万通智控(SZ300643)$ 智微智能:LPU架构横空出世,锚定“智能经济”新形态,打造AI推理算力稀缺标的$智微智能(SZ001339)$
风险提示:以上内容基于公开资料整理(部分为网传资料),本文所提到的观点仅代表个人的意见,所涉及标的不作推荐,本文仅为静态整理,不构成动态投资建议,据此买卖,风险自负。