星环科技能成为中国的Databricks吗?

殊途同归的愿景与大相径庭的现实#星环科技# $星环科技-U(SH688031)$
在全球企业级基础软件的宏大版图中,数据管理与人工智能的融合已成为不可逆转的时代洪流。这一趋势的核心产物便是“湖仓一体”(Lakehouse)架构——一种试图终结数据湖与数据仓库长达十年分治局面的革命性范式。在大洋彼岸的美国,Databricks 凭借其作为 Apache Spark 创始团队的嫡系血统,依托公有云的无限弹性,确立了全球数据智能领域的霸主地位,估值一度突破 1000 亿美元,被视为云计算时代的“新甲骨文” 。而在太平洋西岸的中国,星环科技(Transwarp Technology) 作为国产基础软件的领军者,常被资本市场与业界观察家冠以“中国的 Databricks”之名 。这一类比不仅承载了对中国本土诞生世界级基础软件巨头的期许,也隐含了对其技术路径与商业潜力的高度对标。
从技术基因、架构演进、AI 战略、生态构建及商业模型等维度,对星环科技与Databricks 进行全景式、显微镜级的深度对比研究。分析显示,尽管两者在“统一数据分析”、“湖仓一体”及“AI 基础设施化”的战略愿景上高度重合,但受限于中美两国截然不同的IT基础设施环境、数据监管政策及商业付费习惯,两者实际上走上了两条平行的进化路径。Databricks 成为了云原生的通用效用设施,而星环科技则进化为适应中国私有化部署、强调自主可控与软硬解耦的“数据操作系统”。“中国的 Databricks”这一称谓,既是对星环科技技术实力的认可,也掩盖了其为适应中国本土环境而被迫进行的深刻异化。
1. 基因与起源:学院派颠覆与工业界改良
一家技术企业的终局往往深植于其起源的基因之中。Databricks 与星环科技均诞生于大数据技术从蛮荒走向成熟的 2013 年,但孕育它们的土壤——加州伯克利的学术实验室与英特尔的亚太研发中心——决定了它们截然不同的早期轨迹与核心气质。
1.1 Databricks:云端火花的燎原之势
Databricks 的故事始于加州大学伯克利分校的 AMPLab。2009 年,Matei Zaharia 及其团队为了解决 Hadoop MapReduce 在迭代计算(如机器学习)上的性能瓶颈,开发了 Apache Spark。Spark 的内存计算模型将数据处理速度提升了 100 倍,迅速成为了大数据领域的新宠。
然而,Databricks 的成立并非仅仅是为了商业化 Spark,而是基于一个极其前瞻性的赌注:公有云将成为大数据的终极归宿。在 2013 年,当绝大多数企业还在采购服务器搭建本地 Hadoop 集群时,Databricks 的创始团队便决定跳过本地部署软件(On-Premise Software)的泥潭,直接构建基于云的托管平台。这一决策在当时显得激进甚至冒险,但事后证明是其甩开 Cloudera、Hortonworks 等竞争对手的关键胜负手 。
Databricks 的基因是**“云原生”与“开源社区”**。它不依赖于硬件销售,也不受限于客户的数据中心架构。通过将 Spark 捐赠给 Apache 基金会,Databricks 成功将底层计算引擎商品化,从而构建了一个庞大的全球开发者生态。这种“开源引流、云端变现”的模式,使其能够以极低的边际成本服务全球数万家客户,专注于解决数据工程中最具挑战性的规模化与协作问题。
1.2 星环科技:巨头阴影下的突围与重构
与 Databricks 的学院派背景不同,星环科技的创始团队源自英特尔(Intel)数据中心软件部。创始人孙元浩曾任英特尔亚太区研发总监,负责 Hadoop 在英特尔架构上的优化 。这意味着星环科技从诞生的第一天起,就带有浓厚的**“企业级硬件优化”与“替代传统数据库”**的基因。
2013 年前后的中国 IT 市场,正处于“去 IOE”(IBM、Oracle、EMC)浪潮的前夜。随着互联网业务的爆发,传统的关系型数据库难以支撑海量数据,而开源的 Hadoop 虽然扩展性强,但稳定性差、SQL 支持弱,难以满足金融、电信等核心行业的严苛要求。星环科技看到了这一巨大的市场真空:中国企业需要的不是一个纯粹的计算引擎,而是一个能够平滑替代 Oracle、稳定运行在国产廉价硬件上的大数据平台 。
因此,星环科技的发展路径是一条艰难的**“工业级改良”**之路。它没有选择完全依赖开源社区,而是基于 Hadoop/Spark 内核进行了大量的重写与改造。为了满足中国企业对复杂报表和事务处理的需求,星环科技投入重兵研发了能够高度兼容 Oracle PL/SQL 的编译器,这在当时被认为是“不可能完成的任务”。如果说 Databricks 是为了创造一个新的云端分析市场,那么星环科技则是为了在存量市场中虎口夺食,用分布式技术重构传统的企业数据中心。
1.3 战略定位的初始分野
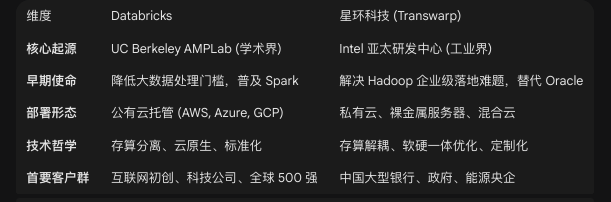
这种基因上的差异,解释了为何 Databricks 能够成为全球通用的技术栈,而星环科技则演变成了一个高度适应中国本土环境的“全能型”平台。
2. 架构之争:云端湖仓 vs. 数据云操作系统
“湖仓一体”(Lakehouse)是两家公司目前共同的技术叙事核心。然而,剖析其底层架构可以发现,虽然终点相同,但通往终点的路径却因基础设施环境的不同而大相径庭。
2.1 Databricks:基于对象存储的开放式湖仓
Databricks 的架构哲学是**“开放”与“解耦”**。它建立在公有云厂商(如 AWS S3、Azure Blob Storage)提供的廉价对象存储之上,自身并不持有数据,而是提供计算能力与元数据管理。
2.1.1 Delta Lake:赋予数据湖以事务能力
Databricks 架构的基石是 Delta Lake。在 Delta Lake 出现之前,数据湖(Data Lake)往往沦为“数据沼泽”,因为缺乏事务保障,写入失败会导致数据损坏,且难以支持并发读写。Delta Lake 创造性地在 Parquet 文件之上引入了一个事务日志(Delta Log) 10。
技术机制: Delta Log 记录了每一次对数据的操作(如插入、删除、更新)。读取数据时,引擎首先查阅日志,确定哪些 Parquet 文件是有效的。这使得 Databricks 能够在廉价的对象存储上实现 ACID 事务、时间旅行(Time Travel)和模式强制(Schema Enforcement)。
战略意义: Delta Lake 采用开放格式,意味着客户的数据实际上只是存储在自己 S3 桶里的文件,不被 Databricks 锁定。这种“数据主权”在云时代极具吸引力,也是 Databricks 对抗 Snowflake 等封闭数仓的核心武器。
2.1.2 Photon 引擎:向量化计算的极致
为了解决 Java 虚拟机(JVM)在处理大规模数据时的性能瓶颈,Databricks 研发了 Photon 引擎 12。
技术突破: Photon 是一个完全用 C++ 重写的向量化查询引擎。它利用现代 CPU 的 SIMD(单指令多数据)指令集,能够以极高的并行度处理数据。Photon 的引入,标志着 Spark 生态从“纯 Java/Scala”向“底层硬件加速”的转型,使其查询性能足以匹敌甚至超越传统的 MPP 数据仓库。
2.1.3 Unity Catalog:统一治理的神经中枢
随着数据资产的爆炸式增长,治理成为难题。Unity Catalog 是 Databricks 的统一治理层,它不仅管理表(Tables),还管理文件(Files)、模型(Models)和仪表盘(Dashboards)。它是 Databricks 实现“数据智能”的关键,使得 AI 模型能够理解数据的血缘关系和安全策略 13。
2.2 星环科技:多模态融合的“数据云”架构
与 Databricks 依赖公有云对象存储不同,星环科技面对的是中国企业复杂的私有数据中心环境。这里可能没有 S3,只有裸金属服务器和各种异构存储设备。因此,星环科技必须构建一套完整的**“数据操作系统”**。
2.2.1 TDDMS:自主研发的分布式数据管理系统
星环科技架构的核心是 TDDMS(Transwarp Distributed Data Management System)。这是一个抽象的存储层,能够屏蔽底层硬件的差异 。
多模型统一: 这是星环科技最显著的架构特征。TDDMS 支持 10 种不同的数据模型,包括关系型数据、图数据、时空数据、文档数据等。与之对应,星环科技开发了多个专用的数据库引擎(如关系型数据库 ArgoDB、图数据库 StellarDB、向量数据库 Hippo),它们共享同一个底层存储管理系统。
技术优势: Databricks 如果要处理图数据,通常需要集成第三方工具(如 Neo4j)。而在星环的架构中,图计算引擎可以直接读取存储层的数据,无需进行昂贵的数据搬迁(ETL)。这种**“多模一架构”**(Multi-Model One Architecture)极大地简化了企业技术栈的复杂度,非常适合希望“一站式”解决所有数据问题的中国大型国企。
2.2.2 存算解耦的本土化实践
虽然 Databricks 天生就是存算分离的,但星环科技花费了数年时间将原本存算耦合的 Hadoop 架构改造为存算解耦(Disaggregated Storage and Compute)架构 17。
TDC(Transwarp Data Cloud): 星环科技基于 Kubernetes 构建了 TDC 平台,实现了类似公有云的弹性伸缩能力。在私有云环境中,TDC 可以动态地调度计算资源,让不同的租户(如银行的不同部门)共享计算集群,同时通过 TDDMS 访问共享存储。这使得星环科技能够在私有云中提供类 AWS 的体验。
2.2.3 极致的 SQL 兼容性:Inceptor
星环科技的 Inceptor 引擎在 SQL 兼容性上走得比 Databricks 更远。
Oracle 替代者: Inceptor 不仅支持 ANSI SQL,还提供了对 Oracle PL/SQL 和 IBM DB2 SQL 的高度兼容 。它拥有完整的分布式事务处理能力,支持存储过程、触发器等复杂数据库特性。这使得星环科技能够承接那些从 Oracle 迁移出来的核心交易与分析混合负载(HTAP),而这部分市场是 Databricks 难以触及的。
2.3 架构对比总结:适应性进化的结果
架构组件Databricks Lakehouse星环科技 TDH / TDC基础设施依赖强依赖公有云 (Cloud Native)硬件中立,支持裸金属/私有云/混合云存储层技术对象存储 + Delta Lake (开放格式)TDDMS + 专用存储格式 (Holodesk)计算引擎Photon (C++), Spark (JVM)Nucleon, Inceptor (Java/C++ 混合)核心优势弹性伸缩,开放生态,即开即用多模态融合,Oracle 兼容,自主可控数据模型支持主要是结构化表 + 非结构化文件原生支持图、向量、时空、文档等 10+ 模型部署复杂度低 (全托管 SaaS)高 (需部署整套 PaaS 平台)
深度洞察: 架构的差异反映了两者服务对象的不同。Databricks 是**“敏捷的云端瑞士军刀”,适合追求速度和创新的团队;星环科技是“重装的本地数据航母”**,适合需要极高稳定性、合规性和多业务融合的大型机构。
3. 性能巅峰对决:TPC-DS 与基准测试的较量
在基础软件领域,性能就是话语权。TPC-DS 作为数据库领域最权威、最复杂的决策支持基准测试,成为了两家公司证明技术实力的角斗场。
3.1 星环科技的“破局”时刻
2019 年,星环科技成为了全球首个通过 TPC-DS 基准测试并经过官方审计的数据库厂商 7。这一成就具有里程碑意义。
技术挑战: TPC-DS 包含 99 个极度复杂的 SQL 查询,涉及大量的多表关联、嵌套子查询和窗口函数。在星环之前,大多数基于 Hadoop/Spark 的系统都无法完整运行这 99 个查询,更不用说通过性能测试了。
星环的解法: 星环科技并没有直接使用开源 Spark 的 SQL 引擎,而是自研了 SQL 编译器。它引入了基于代价的优化器(CBO),并针对 TPC-DS 的特征进行了深度的算子优化。此外,星环采用了自研的列式存储格式 Holodesk,它利用 SSD 进行加速,极大地提升了 I/O 吞吐量 。
市场影响: 这张“世界第一”的证书,成为了星环科技敲开中国大型银行大门的金钥匙,证明了国产软件在复杂分析能力上已经超越了当时的开源水平。
3.2 Databricks 的“光子”反击
Databricks 在早期并未急于参与 TPC-DS 打榜,而是专注于易用性。但随着 Snowflake 的崛起,性能之争愈演愈烈。2021 年,Databricks 利用 Photon 引擎 打破了 TPC-DS 的世界纪录 。
降维打击: Databricks 的测试结果显示,Photon 引擎在 100TB 级别的数据量下,性能不仅超越了传统的 Hadoop 体系,也大幅领先于 Snowflake。其优势在于 C++ 带来的指令级并行和对 CPU 缓存的极致利用。
持续演进: 最新的基准测试显示,Amazon EMR 上的 Spark(优化版)比开源版本快 4.5 倍,而 Databricks 的 Photon 往往能提供更进一步的性能提升 。
对比分析: 星环科技的 TPC-DS 胜利证明了其SQL 语法的完备性和复杂逻辑处理能力,这对于替代 Oracle 至关重要。Databricks 的 TPC-DS 胜利则证明了其**裸算力(Raw Compute Power)**的强大,这对于云端的大规模数据处理至关重要。两者的胜利分别解决了“能不能做”和“做得有多快”的问题。
4. AI 战略的交汇:数据智能与“AI x Data”
随着 ChatGPT 引爆全球 AI 热潮,两家公司都迅速调整战略,试图成为企业构建生成式 AI 应用的首选基础设施。
4.1 Databricks:数据智能平台(Data Intelligence Platform)
Databricks 的 AI 战略非常激进且清晰:让数据平台直接拥有理解和生成数据的能力。
收购 MosaicML: 2023 年,Databricks 斥资 13 亿美元收购 MosaicML。这一举措补齐了其在**大模型训练(LLM Training)**上的短板。现在,Databricks 允许企业利用自己的数据,在自家的云环境中低成本地预训练或微调大模型,而无需将数据泄露给 OpenAI 。
LakehouseIQ: 这是一个基于生成式 AI 的知识引擎。它通过扫描 Unity Catalog 中的元数据、查询日志和文档,自动学习企业的“业务术语”。这使得非技术人员可以用自然语言提问(如“上季度的 churn rate 是多少?”),系统能准确理解并生成 SQL 查询。
向量检索集成: Databricks 将向量数据库功能直接集成到了平台中,支持 RAG(检索增强生成)应用,无需外挂 Pinecone 或 Milvus 等专用向量库 13。
4.2 星环科技:“AI x Data”与知识工程
星环科技的 AI 战略则更加侧重于**“全流程工具链”与“知识治理”**,提出了“AI x Data = Future”的公式 。
Sophon 平台: 这是一个覆盖数据科学全生命周期的平台。最新的 Sophon LLMOps 模块提供了从大模型微调、评估到部署的流水线。它内置了“模型铸造厂”(Model Foundry),支持 Llama、ChatGLM、Baichuan 等主流开源模型的快速接入 。
知识中台(Knowledge Hub): 这是星环科技针对中国市场痛点推出的杀手级产品。中国企业的数据往往质量较差、非结构化程度高(大量的 PDF、Word 文档)。星环科技的知识中台结合了 Hippo 向量数据库 和 StellarDB 图数据库,能够自动化地从文档中提取知识,构建知识图谱,并结合大模型进行精准的问答 。
独特优势: 相比 Databricks 侧重于“计算”,星环科技更侧重于“知识工程”。它提供的不仅仅是工具,更是一套将杂乱数据转化为高质量语料的方法论和工具集,这对于缺乏 AI 人才的传统企业尤为重要。
4.3 商业化模式的差异
Databricks: 卖算力。用户训练模型、调用向量检索都会消耗 DBU(Databricks Units),直接拉动云资源消费。
星环科技: 卖解决方案。在“信创”背景下,星环科技往往需要打包软硬件,甚至提供实施服务,帮助客户搭建私有的企业级大模型应用。这使得其 AI 业务更重,但也更具粘性。
5. 生态系统与“信创”护城河
生态系统的构建方式,是区分一家“全球化软件公司”与“区域性软件巨头”的关键。
5.1 Databricks:全球标准的制定者
Databricks 成功的秘诀在于**“标准控制权”**。通过掌控 Spark、Delta Lake 和 MLflow 这三大开源项目,Databricks 事实上定义了全球数据工程的标准。
网络效应: 全球数百万数据工程师以掌握 Spark 为荣。所有的 BI 工具(Tableau, PowerBI)、ETL 工具(dbt, Fivetran)都优先支持 Databricks。这种生态吸力使得客户很难完全脱离 Databricks 体系。
开放核心(Open Core): Databricks 的商业模式是“开源引流,云端增值”。它不靠卖软件授权赚钱,而是靠提供比开源版本更好用、更快的托管服务赚钱。
5.2 星环科技:自主可控的“信创”长城
由于地缘政治原因,星环科技无法像 Databricks 那样依赖全球开源社区。相反,它构建了一条基于**“信创”(信息技术应用创新)**的护城河。
代码自主率: 星环科技强调其核心产品的代码自主研发率超过 99% 9。在 Oracle 和 Cloudera 等外企逐渐退出中国核心市场的背景下,这一点至关重要。政府、军工、金融等关键行业必须采购“无后门”、“非黑盒”的软件。
国产硬件生态: 这是 Databricks 完全无法企及的领域。星环科技投入了巨大的资源进行软硬适配,支持华为鲲鹏(ARM 架构)、海光(x86 架构)、飞腾等国产 CPU,以及麒麟、统信等国产操作系统 。
技术壁垒: 在异构的国产硬件上跑通复杂的大数据平台是一个巨大的工程挑战。Databricks 的代码是为通用的 Intel/AMD/NVIDIA 芯片优化的,如果强制移植到国产芯片上,性能会大打折扣。星环科技在这一领域的深耕,使其在国产化替代项目中具有垄断性优势。
6. 财务透视:云泥之别的商业现实
抛开技术光环,从财务数据看,星环科技与 Databricks 并不在一个量级。这是中美软件市场付费能力与商业模式差异的直接体现。
6.1 Databricks:SaaS 经济的典范
营收规模: Databricks 的年化收入(ARR)已突破 40 亿美元,年增长率超过 50% 。
估值逻辑: 1000 亿美元的估值基于其超高的净收入留存率(NDR > 140%)。这意味着老客户不仅续费,而且每年会多花 40% 的钱。这是一种极具复利效应的商业模式。
现金流: 公司已实现运营现金流转正,具备了随时 IPO 的财务健康度 24。
6.2 星环科技:转型期的阵痛
营收规模: 星环科技的年营收约为 4-5 亿元人民币(约 7000 万美元),仅为 Databricks 的 1.5% 左右 。
盈利挑战: 公司长期处于亏损状态,2024 年净亏损甚至接近营收总额。这主要归因于极高的研发投入(占比 > 70%)以维持庞大的产品线,以及高昂的销售费用 。
商业模式困境: 中国企业习惯于“项目制”采购,而非订阅制。这意味着星环科技每做一单生意都要重新投入销售和实施成本,难以形成 SaaS 的飞轮效应。此外,大客户(银行、政府)的议价能力强,回款周期长,导致公司应收账款压力巨大。
深度洞察: 财务数据的悬殊并非单纯是公司能力的差异,更是市场土壤的差异。Databricks 生长在付费意愿强、标准化程度高的美国 SaaS 土壤;星环科技生长在定制化要求高、竞争激烈且正处于“国产化阵痛期”的中国土壤。
7. 结论:平行宇宙中的双子星
回到最初的问题:星环科技是中国的 Databricks 吗?
从产品愿景来看,是的。
两者都坚定地信仰“湖仓一体”,都致力于统一数据与 AI,都试图成为企业数字化的底层操作系统。星环科技在技术栈的完整度和前瞻性上,确实是中国市场上最接近 Databricks 的存在,甚至在多模态数据支持和 SQL 兼容性上有所超越。
Databricks 是一家全球化的公有云公用事业公司,它像水厂一样提供标准化的数据算力。星环科技是一家深耕本土的私有云基础设施承建商,它像建筑公司一样为客户构建固若金汤的数据堡垒。
星环科技不应被简单视为 Databricks 的模仿者。它是**“后全球化时代”**的产物。在数据主权日益重要、技术供应链脱钩的今天,星环科技代表了中国建立独立自主数字基础设施的决心。它可能永远无法获得 Databricks 那样令人咋舌的财务回报,但它在中国数字经济版图中的战略地位,或许比单纯的市值数字更为沉重。
对于投资者和行业观察者而言,看 Databricks 看的是AI 对云支出的拉动;看星环科技,看的是信创替代的渗透率与中国企业数字化转型的深水区突围。
看到这里的小伙伴 点个赞、加个关注再走吧![]()