企业大规模AI Coding落地:如何控制大模型成本?


随着碧桂园服务在智慧社区、增值等业务场景中全面引入 AI 能力,新业务团队已将大语言模型深度融入日常开发流程——从架构设计到需求编写、从代码生成到自动化测试,AI 正在成为每一位开发者的“第二双手”。然而,伴随 AI 调用量的快速增长,一个现实问题逐渐浮现:大模型消耗的成本正变得不可控。
以碧桂园服务的三个核心项目(充电桩平台架构重构、下载中心需求开发、消息中心技术开发实践)为例:新业务团队在实际推进中发现,月度 AI API 费用合计已超过 $1,400。更值得警惕的是,其中超过 60% 的 Token 消耗属于浪费:重复粘贴的编码规范、一刀切使用最贵模型、全量数据塞入提示词、失控的上下文膨胀……
面对这一挑战,新业务团队率先启动了 AI API 成本治理专项,系统性地梳理了 Token 消耗的全链路痛点,并提出了“Context → Rules → Skill → MCP → Agent”五层协同优化方案。经过在三个项目中的实践验证,月度 API 成本从 $1,400 降至 $166,降幅达 88%,年度节省超过 $14,800。
核心成果包括:三个项目合计月度成本降低 88%($1,400 → $166),Token 有效利用率从不足 40% 提升至 85%+,开发效率同步提升 3-4 倍。
*以下内容来自碧桂园服务新业务研发团队

要解决成本问题,首先需要搞清楚钱花在了哪里。研发团队对三个项目的 Token 消耗做了详细的审计分析,发现了五个主要的成本痛点。
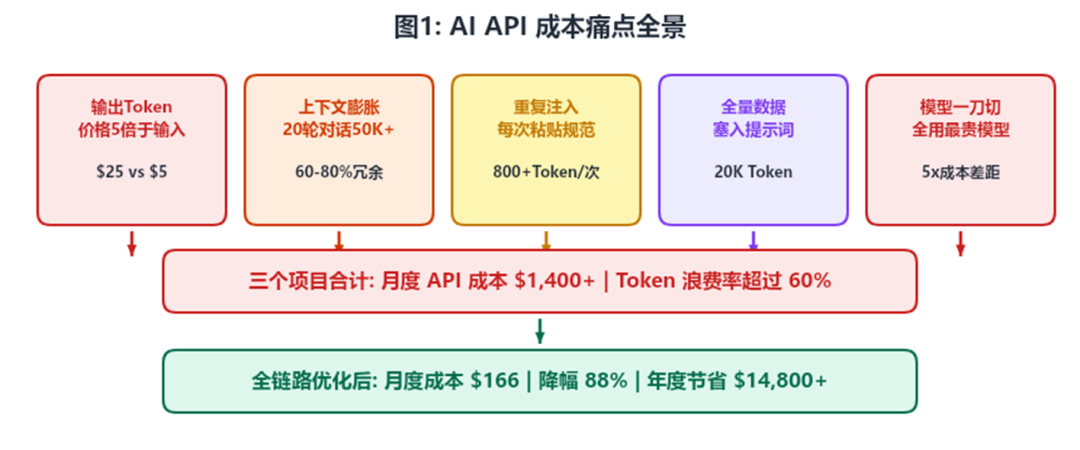
|1.1 输出 Token 是“隐形杀手”
Claude 所有模型的输出 Token 价格均为输入的 5 倍(例如 Opus 4.6:输入 $5/MTok,输出 $25/MTok)。很多开发者不了解这一定价结构,导致大量请求产生了远超必要的冗长输出,成本被无形放大。
|1.2 上下文无限膨胀
在多轮对话的开发场景中,上下文会随着对话轮次快速累积。一个 20 轮的需求讨论可以轻松达到 50,000+ Token,其中 60-80% 是冗余的历史记录。每一轮对话都在为之前的冗余内容“买单”。
|1.3 重复规范反复粘贴
项目编码规范、技术栈约定、API 设计原则……这些静态内容在每次新会话时都需要手动粘贴注入。以 800 Token 的编码规范为例,日均 4,000 次调用意味着每天白白消耗 320 万 Token 在重复内容上。
|1.4 全量数据一次性注入
当 AI 需要理解数据库结构或查询业务数据时,传统做法是将 20,000+ Token 的数据一股脑塞入提示词。实际上 AI 每次只需要其中 5% 的相关数据,95% 都是浪费。
|1.5 模型选择“一刀切”
项目编码规范、技术栈约定、API 设计原则……这些静态内容在每次新会话时都需要手动粘贴注入。以 800 Token 的编码规范为例,日均 4,000 次调用意味着每天白白消耗 320 万 Token 在重复内容上。
三个项目最初全部使用最昂贵的 Opus 4.6 模型。但实际分析发现,70% 以上的任务(需求模板填充、接口文档生成、代码注释补全等)属于结构化写作,中等模型 Sonnet 4.6 完全胜任,甚至简单分类任务 Haiku 4.5 就够了。
如下表所示,三个模型之间存在巨大的价格差异:
模型输入价格($/MTok)输出价格($/MTok)缓存读取($/MTok)适用场景Opus 4.6$5$25$0.50复杂推理/架构设计Sonnet 4.6$3$15$0.30通用开发/需求编写Haiku 4.5$1$5$0.10分类/格式化/路由

定位到五大痛点后,研发团队并没有“头痛医头”地逐个修补,而是从工程架构层面设计了一套完整的优化体系。这套体系的核心是五个概念的协同联动:Context(上下文)→ Rules(规则持久化)→ Skill(工作流封装)→ MCP(按需数据获取)→ Agent(自动编排)。
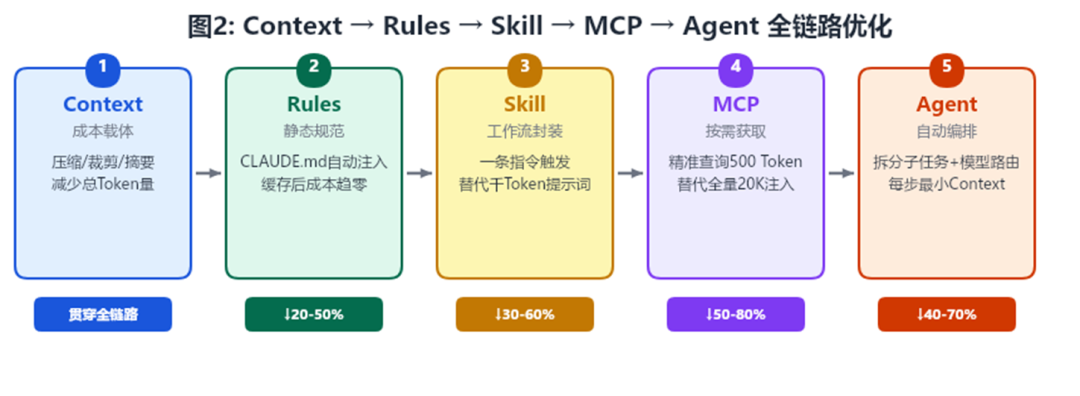
|2.1 提示词压缩:
从源头减少 Token(节省 30-50%)
提示词压缩是投入产出比最高的优化策略——零成本、无需基础设施改动,每次调用都能受益。核心思路是用更少的 Token 传达相同的信息。
实战案例:充电桩项目将 3,500 Token 的系统提示词(含完整架构规范、编码标准、需求模板)压缩为 1,200 Token 的结构化格式,减少 66%。
优化前(286 Token):你是一个专业的客服人员。当用户向你提问时,你需要仔细分析用户的问题,然后提供详细、全面且准确的回答。请确保你的回答包含足够的细节……
优化后(97 Token):角色:客服人员 规则:准确简洁 | 不确定时如实说明 | 超出范围建议寻求专业帮助 格式:直接回答 + 后续建议
压缩技巧:删除填充词(“请你”、“你需要”)、使用结构化格式(YAML/键值对)替代自然语言段落、合并冗余指令、善用缩写。
|2.2 Rules 持久化规范:
让静态规范免费加载(节省 20-50%)
Rules 机制通过 CLAUDE.md 文件将项目规范、编码约定等信息持久化存储,每次会话自动加载,无需手动粘贴。结合提示词缓存(读取成本仅为正常价格的 10%),静态规范的加载成本趋近于零。
实战效果:
充电桩项目将架构规范和代码风格指南写入 CLAUDE.md(约 1,500 Token),配合缓存,日均命中率 96%,读取成本仅为正常的 10%。
将编码规范、命名约定、架构原则写入 CLAUDE.md,自动注入每次会话分层设置规则:全局 Rules + 项目 Rules + 模块 Rules规则内容天然是静态的,完美适配提示词缓存——加载成本趋近于零
|2.3 提示词缓存:
重复内容一次付费(节省最高 90%)
提示词缓存允许在多次 API 调用之间缓存频繁使用的上下文内容。首次写入缓存多付 25%,此后 5 分钟内读取价格仅为正常价格的 10%。对于高频调用场景,这是最具影响力的成本节省功能。
使用场景未使用缓存使用缓存节省比例日调用1K次, 2K系统提示(Opus)$10.00/天$1.00/天90%日调用1万次, 2K系统提示(Sonnet)$60.00/天$6.00/天90%日调用5万次, 4K系统提示(Haiku)$200.00/天$20.00/天90%
|2.4 模型智能路由:
把合适的模型给合适的任务(节省 80%)
并非所有任务都需要最强大的模型。通过一个轻量级分类器(Haiku 4.5,每次约 $0.0003)分析请求复杂度,将任务路由到最合适的模型:
简单任务(分类/格式化/路由,约 60%请求)→ Haiku 4.5中等任务(通用问答/内容摘要,约 30%请求)→ Sonnet 4.6复杂任务(架构设计/Agent 编排,约 10%请求)→ Opus 4.6
下载中心实践:70% 的 PRD 模板填充和用户故事格式化路由到 Sonnet 4.6,仅 30% 的复杂需求分析保留 Opus 4.6,整体成本降低 70%+。
|2.5 Skill 封装:
一键触发替代上千Token提示词(节省30-60%)
Skill 是预定义的领域知识包,将特定任务的提示词、工作流和最佳实践封装为可复用模块。一条触发指令替代上千 Token 的详细提示词。
实战效果:下载中心将“PRD 生成”和“用户故事拆分”封装为 Skill,触发指令仅 200 Token,替代手写 1,500 Token 的详细提示词,团队统一复用。
|2.6 MCP 按需获取:
精准查询替代全量注入(节省 50-80%)
MCP(Model Context Protocol)通过标准协议连接外部数据源,让 AI 按需查询而非全量加载。用 500 Token 的精准查询结果替代 20,000 Token 的完整数据注入。
消息中心实践:通过 MCP 按需读取待测源码文件(~800 Token),替代注入完整代码库(~50,000 Token),输入 Token 减少 90%+。MCP 工具定义本身仅 200-500 Token,缓存后几乎零成本。
|2.7 Agent 自动编排:
拆分子任务最小化 Context(节省 40-70%)
Agent 是整条链路的“指挥官”,自动加载 Rules、调用 Skill、通过 MCP 获取数据,并将复杂任务拆分为多个子任务——每个子任务仅携带最小必要 Context。
下载中心实战:一个预估 80,000+ Token 的“新增管理员模块”需求,Agent 拆分为 4 个子任务,每个仅需 3,000-5,000 Token 上下文,实际总消耗约 18,000 Token,Context 压缩 78%。
|2.8 输出约束与批处理:
双管齐下降低输出成本
输出 Token 价格是输入的 5 倍,必须严控。使用 max_tokens 参数设置上限(分类任务设为 10-50);要求 JSON 格式输出(比自然语言短 40-60%);在提示词中指定“请简洁回答,最多3句话”。
批处理 API:非实时任务(测试用例生成、批量文档输出)使用 Message Batches API,享受标准价格 50% 折扣。凤凰会将日均 2,500 次测试任务全部转为批处理,该部分成本直接减半。

纸上得来终觉浅。研发团队在三个核心项目中全面落地了上述优化策略,以真实数据验证方案的有效性。
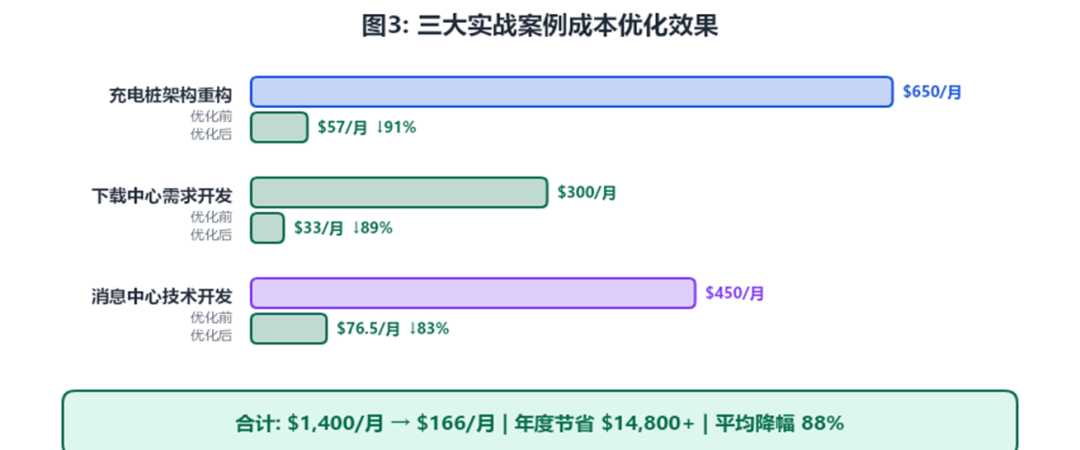
|3.1 充电桩平台架构重构
(月度成本 ↓91%)
背景:某充电桩运营商在业务快速扩张期,需要对后端系统进行主流程架构重构。日均约 4,000 次 API 调用,最初全部使用 Opus 4.6,月度 API 费用约 $650。
优化措施:80% 的任务(需求文档模板填充、接口文档生成)降级到 Sonnet 4.6;系统提示词从 3,500 Token 压缩为 1,200 Token(↓66%);架构规范写入 CLAUDE.md + 缓存命中率 96%;“架构分析”和“需求文档生成”封装为 Skill + 输出约束。
指标优化前优化后变化使用模型全部 Opus 4.6Sonnet 4.6 为主模型降级系统提示词3,500 Token1,200 Token↓ 66%平均每次请求 Token5,800 Token2,400 Token↓ 59%缓存未使用命中率 96%输入成本 ↓90%月度成本$650/月$57/月↓ 91%
|3.2 下载中心需求开发
(月度成本 ↓89%)
背景:新业务团队使用 Claude API 辅助 PRD 撰写、用户故事拆分等,日均约 10,000 次调用,月度费用约 $300。
优化措施:智能路由(70% Sonnet + 30% Opus);提示词从 3,200 Token 压缩为 1,100 Token;需求迭代对话采用摘要+最近 3 轮(上下文从 ~8K 降至 ~2.5K);“PRD 生成”封装为 Skill + Rules 缓存命中率 94%。
指标优化前优化后变化使用模型全部 Opus 4.6路由: Opus/Sonnet/Haiku智能路由需求模板提示词3,200 Token1,100 Token↓ 66%多轮上下文全部历史(~8K)摘要+近3轮(~2.5K)↓ 69%平均输出 Token800 Token350 Token↓ 56%月度成本$300/月$33/月↓ 89%
|3.3 消息中心技术开发
(月度成本 ↓83%)
背景:新业务团队使用 Claude API 辅助代码生成、API 文档编写、单元测试生成、Code Review。日均约 7,500 次调用,月度费用约 $450。
优化措施:代码补全(67%)→ Sonnet 4.6 实时;测试用例(33%)→ Sonnet 4.6 批处理(↓50%);项目规范写入 CLAUDE.md + 缓存命中率 97%;通过 MCP 按需读取源码替代全量注入;Agent + Skill 协同 + 输出约束。
指标优化前优化后变化使用模型全部 Opus 4.6Sonnet 4.6 + 批处理降级 + 批处理开发规范2,800 Token(手动)2,800 Token(缓存)缓存节省 90%测试用例生成Opus 实时Sonnet 批处理成本 ↓70%月度成本$450/月$76.5/月↓ 83%测试覆盖率45%82%↑ 82%
|3.4 三项目汇总
案例业务场景优化前优化后年度节省案例一充电桩架构重构$650/月$57/月$7,116案例二下载中心需求开发$300/月$33/月$3,204案例三消息中心技术开发$450/月$76.5/月$4,482合计-$1,400/月$166/月$14,802

以上优化并非一步到位,而是分四个阶段逐步落地。这样既能快速见效、增强团队信心,又能循序渐进地引入复杂度更高的优化手段。
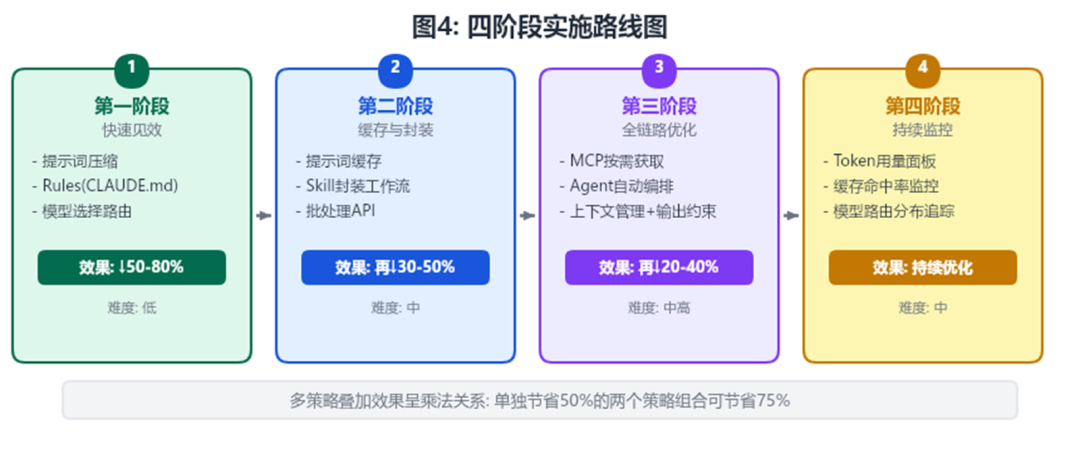
阶段核心动作预期效果实施难度一: 快速见效提示词压缩 + Rules + 模型选择↓ 50-80%低二: 缓存封装提示词缓存 + Skill封装 + 批处理API↓ 30-50%中三: 全链路MCP按需获取 + Agent编排 + 上下文管理↓ 20-40%中高四: 持续监控Token用量面板 + 缓存命中率 + 路由分布持续优化中
关键经验:多策略叠加效果呈乘法关系——单独节省 50% 的两个策略组合可节省 75%。

|5.1 成果总结
通过“Context → Rules → Skill → MCP → Agent”五层协同优化体系,碧桂园服务在三个核心项目中实现了 AI API 成本的系统性治理:
月度 API 总成本从 $1,400 降至 $166,降幅 88%,年度节省超过 $14,800;Token 有效利用率从不足 40% 提升至 85%+;开发效率同步提升:需求文档产出效率提升 3-4 倍,测试覆盖率从 45% 提升至 82%;架构方案和 PRD 产出质量不降反升——压缩的是 Token,不是信息。
|5.2 核心经验
从三个项目的实践中,研发团队提炼出五条通用经验:
模型路由是必选项:70%+ 的开发辅助任务不需要 Opus 4.6,Sonnet 4.6 足以胜任;提示词缓存对开发场景效果立竿见影:项目规范、PRD 模板都应通过 Rules + 缓存自动注入;非实时任务一定要用 Batch API:50% 折扣零改动实现;Skill + Rules + MCP 组合从工程层面系统性减少 Token 消耗,避免重复注入;控制输出比控制输入更重要:输出价格是输入的 5 倍,善用 max_tokens 和 JSON 格式。
|5.3 未来方向
随着 AI 编程工具的快速迭代和模型能力的持续增强,碧桂园服务将在以下方向继续深耕:
搭建统一的 Token 用量监控面板,实现成本的实时可视化和异常预警;探索自动化的模型路由策略,基于任务复杂度动态选择最优模型;将全链路优化经验沉淀为团队标准操作手册,向集团其他技术中心推广复用;持续跟踪 Claude 新版本的定价变化和新功能(如更长上下文窗口、更低价格模型),及时调整优化策略。
最后附上整体调用token的消耗:
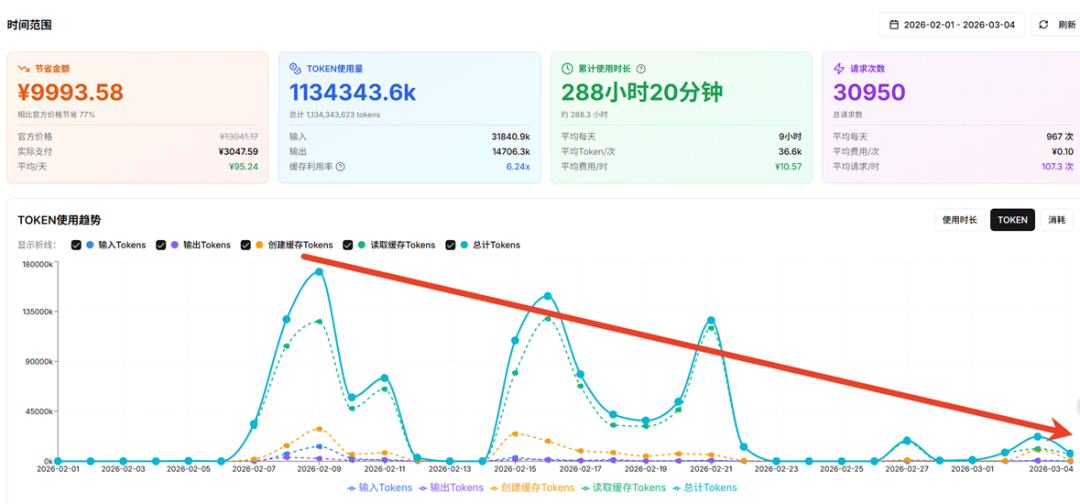
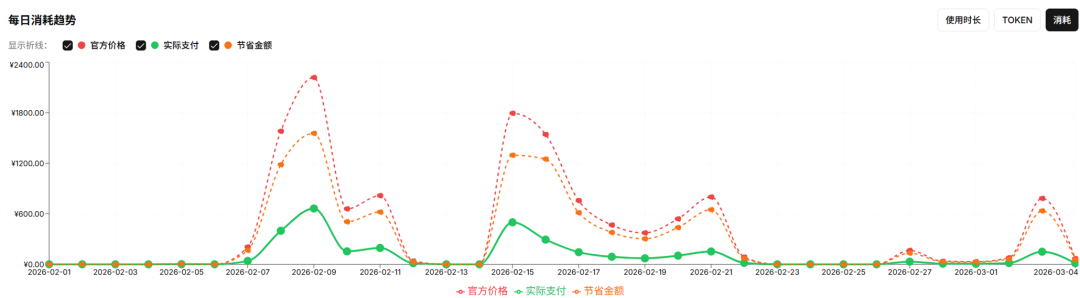
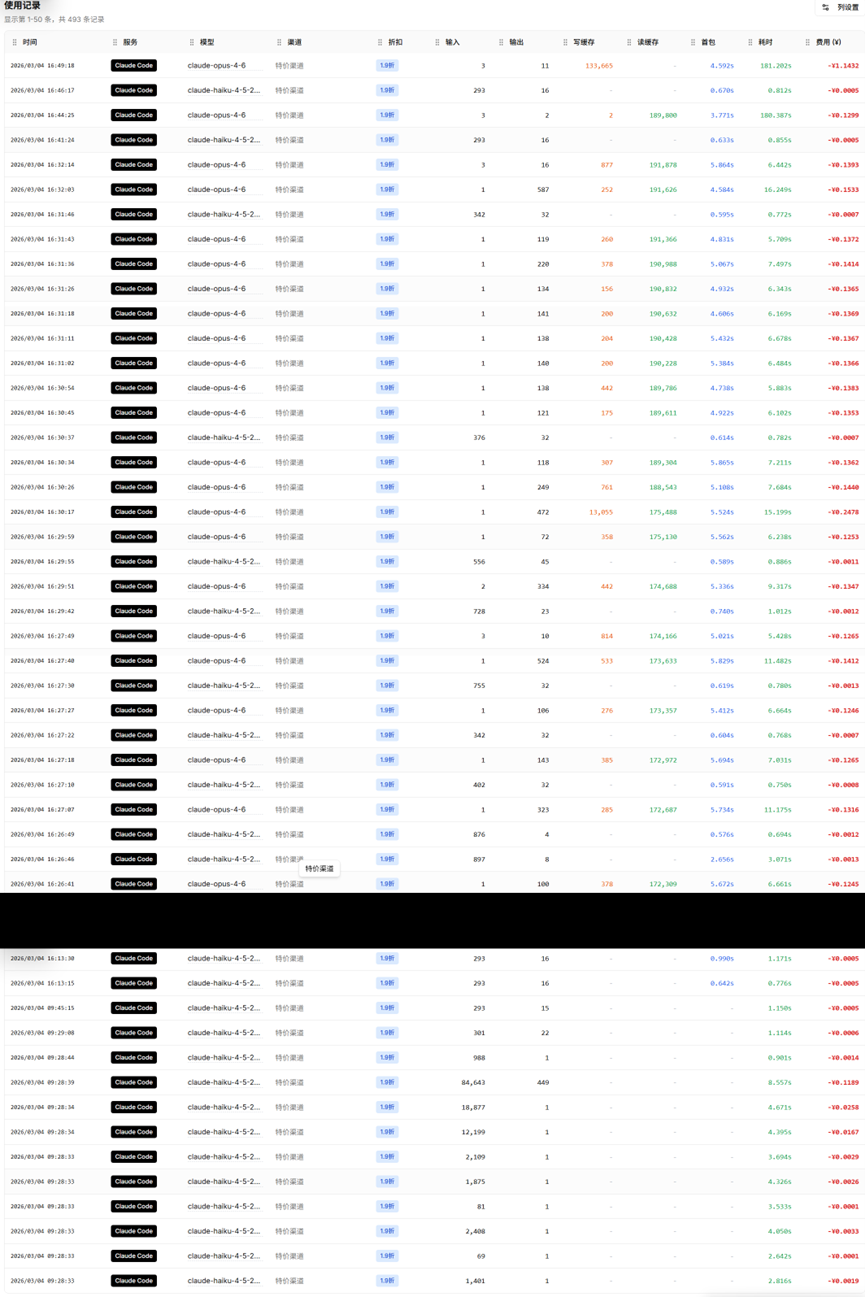
一句话总结:AI API 成本优化不是省钱,而是让每一分钱都花在刀刃上——用更少的 Token,做更多的事。
来源:智在碧得