威士顿工业AI数据提取软件:让工业文本数据“活”起来,赋能企业数字化转型

企业在日常的生产、运营等环节协同中,会持续产生大量以文本形式记录的业务信息。比如设备维护报告、质检单据、供应链合同、技术说明书等文档中,往往沉淀着设备运行规律、质量波动特征、采购与供应链状态、技术参数与工艺要点等关键内容。
这些非结构化文本蕴含着企业的重要“隐形资产”,但由于缺乏可直接利用的结构化形态,它们在多数情况下难以被检索、分析或用于业务决策。通过对这些文本进行系统化的抽取与结构化处理,企业便能将分散的信息转化为可支持预测性维护、质量追溯、供应链预警与知识库建设的数据基础,从而提升运营效率并降低管理与决策风险。
基于这一普遍痛点,威士顿(301315)工业AI数据提取软件以“小样本学习+可视化操作+全流程闭环优化”为核心,打破工业文本数据提取瓶颈,让沉睡的数据转化为可驱动决策的资产,助力企业加速数字化转型、提升业务执行力。
赋能工业多场景
释放数据潜能
威士顿工业AI数据提取软件,作为一款可应用于设备维护、供应链、能源等场景的企业级工具,能够帮助企业解决多种实际业务痛点。在以下常见的工业场景中,软件通过结构化与智能抽取,帮助企业赋能场景、释放数据潜力:
01
设备管理——设备维护与预测性运维
软件可自动识别并提取故障报告中的“故障类型”“故障部位”“故障原因”“处理措施”等关键字段,生成结构化报表,支撑趋势分析与预测性维护,缩短故障响应周期。

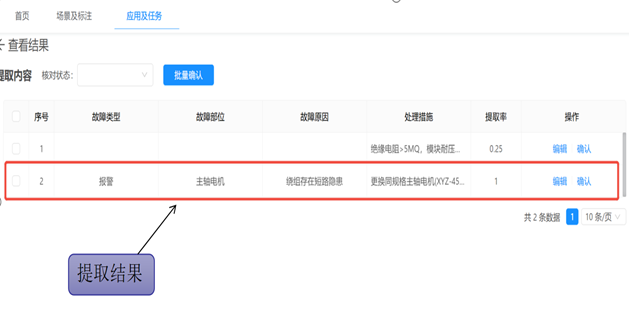
02
供应链管理——采购与物流自动化:
软件可批量处理采购单据、物流单,提取“供应商名称”“物料编码”“数量”“金额”等信息,自动与ERP系统对接,显著降低人工录入错误率。
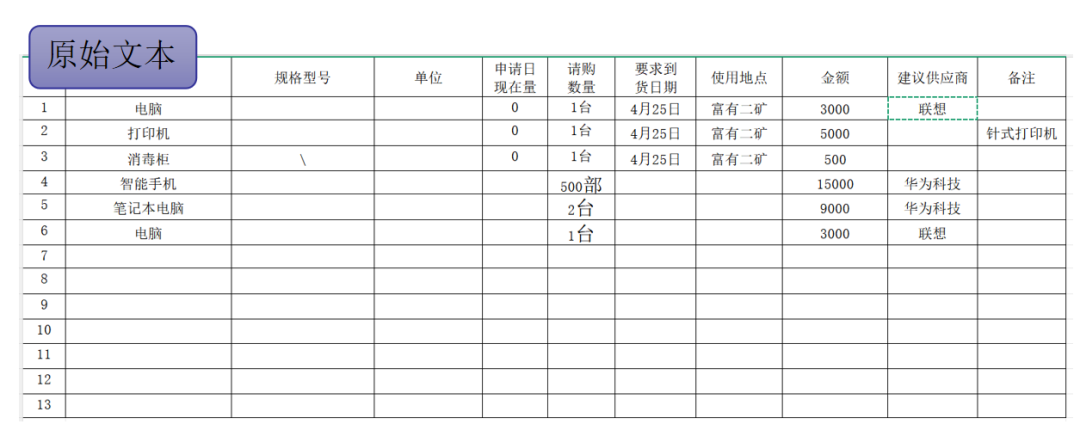
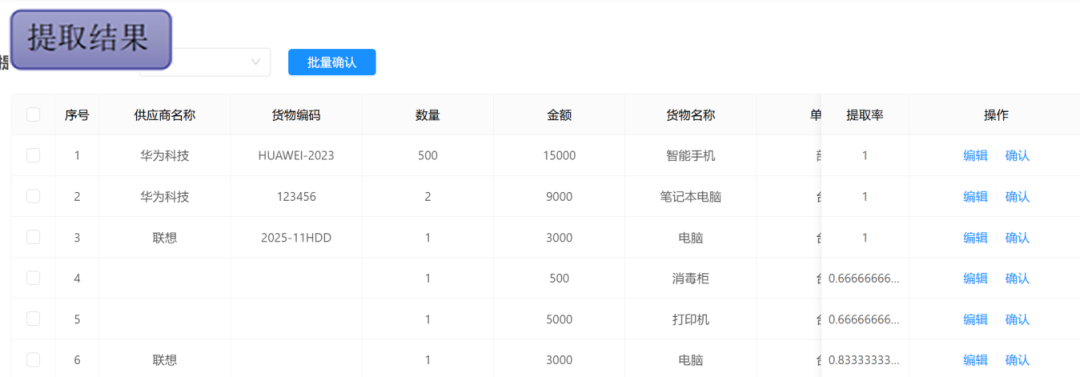
除了设备维护与供应链管理外,威士顿工业AI数据提取软件还能在更丰富的工业场景中释放价值——例如工程变更记录的知识抽取、培训与作业指导书的要点结构化。通过为各业务环节的数据分析提供高质量结构化数据底座,使得业务人员能够从海量文本中快速获得可执行洞见,推动管理与生产效率的持续提升。
据统计,软件在落地某家大型交通企业后,协助用户在短时间内完成了近6年的历史数据的结构化,提取准确率达90%以上,显著提升了历史数据利用率并为后续的预测性维护模型提供了可靠数据支撑。
三大核心能力
支撑业务场景的快速落地
威士顿的技术体系围绕“快速落地、可用可控、持续优化”三大目标设计:通过小样本学习降低标注成本、可视化操作降低使用门槛、以及闭环的样本沉淀机制保证系统随业务演进持续提升。
小样本学习:降低标注成本,快速完成场景上线
仅需少量标注样本,即可生成高质量提示词与抽取规则,突破传统AI对大规模标注数据的依赖,让中小企业也能在短周期内完成验证与上线。
可视化操作:降低技术门槛,实现业务自助
全流程采用拖拽式、点击式交互,业务人员无需代码基础即可独立创建抽取场景、定义字段、调试映射并发布任务,加快场景迭代速度。
全流程闭环:从场景到优化,一体化解决方案
覆盖“场景定义→标注→应用→核对→样本沉淀→模型优化”全链路,避免数据孤岛,实现数据端到端闭环流转与价值最大化,为用户打造高效智能、持续迭代的业务解决方案。
四大核心模块
破解工业文本结构化难题
软件围绕“场景构建-应用落地-模型优化-样本沉淀”打造全流程解决方案,四大模块协同工作,覆盖从需求定义到价值实现的每一步:
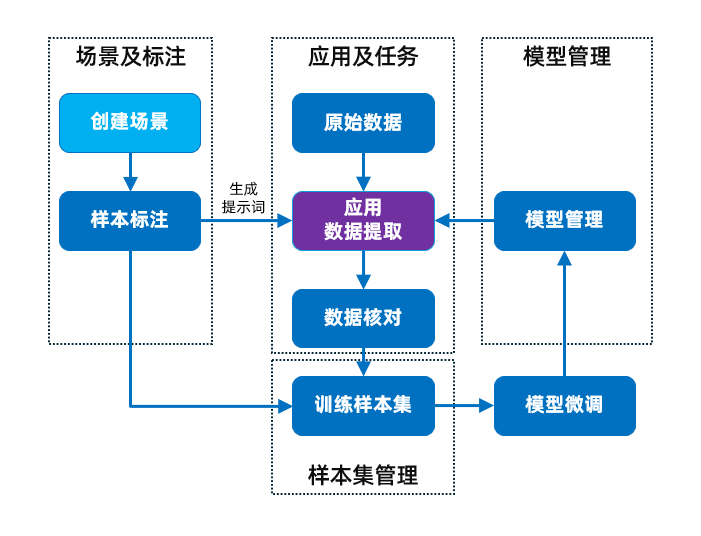
场景及标注
可视化构建专属业务场景,小样本标注快速生成提示词,业务人员无需技术背景即可独立完成;
应用及任务
将场景转化为可执行应用,批量处理文本数据,自动核对优化,降低人工成本;
模型管理
支持多模型适配,兼容主流AI模型(如GPT系列、开源模型),企业可灵活选择,降低技术选型成本;
样本集管理
沉淀企业专属样本库,驱动模型持续优化,提升数据处理精度。
软件以用户为中心,简化复杂流程。业务人员无需技术背景,1小时即可完成专属场景构建,标注效率提升80%,大幅加速了场景的落地。
威士顿工业AI数据提取软件不仅是一种能力载体,更是推动企业从“文档堆积”迈向“知识沉淀”的关键节点。通过对非结构化文本的系统化提取与加工,它使分散的信息重新获得秩序,使隐性的经验得以呈现,也让日常业务中产生的数据真正进入可复用、可分析、可持续演进的循环体系。
在工业数字化不断深化的背景下,这种能力正在成为企业构建内生增长动力的重要组成部分。